ค้นหาภาพใบหน้าอนิเมะจากเว็บ safebooru
เขียนเมื่อ 2018/03/29 09:14
แก้ไขล่าสุด 2021/09/28 16:42
เนื่องจากช่วงนี้กำลังพยายามหารูปใบหน้าอนิเมะเพื่อจะมาเป็นข้อมูลสำหรับการเรียนรู้ของเครื่องโดยใช้โครงข่ายประสาทเทียม
แรงบันดาลใจเดิมทีแล้วมาจากเว็บนี้ https://zhuanlan.zhihu.com/p/24767059
ในนี้ได้ลงโค้ดสำหรับดึงข้อมูลจากเว็บ konachan จากนั้นก็นำภาพที่ได้มาเข้าโปรแกรมค้นหาใบหน้าด้วย opencv แล้วสุดท้ายก็จะได้ใบหน้าอนิเมะจำนวนมากจากในเว็บ จึงได้ลองเรียนรู้จากโค้ดในนี้แล้วดัดแปลงเขียนขึ้นใหม่ในแบบของตัวเอง
เรื่องของการล้วงข้อมูลจากเว็บได้เขียนถึงไว้แล้วใน https://phyblas.hinaboshi.com/20180320 และ https://phyblas.hinaboshi.com/20180323
ส่วนเรื่องการค้นหาใบหน้าด้วย opencv ก็เขียนถึงไปใน https://phyblas.hinaboshi.com/20180326
และเพื่อเร่งความเร็วจึงใช้ multiprocessing เข้าร่วมได้ ก็มีเขียนถึงไปใน https://phyblas.hinaboshi.com/20180317
เว็บเป้าหมายสำหรับครั้งนี้มีอยู่ ๒ แหล่ง คือเว็บ https://konachan.net และ https://safebooru.org ซึ่งเป็นแหล่งรวมภาพอนิเมะที่มีคนเอามาลงไว้มากมาย
ทาง konachan นั้นมีภาพน้อยกว่า คือรวมแล้วแสนกว่าภาพ แต่ safebooru มีกว่าสองล้านภาพ ดังนั้นตอนที่ค้นข้อมูล konachan จึงดึงรูปมาทั้งหมด แต่ safebooru นั้นมีเยอะจึงค้นเอาเฉพาะแท็กที่ต้องการ เพราะไม่เช่นนั้นจะเยอะ เว็บนี้ทำระบบแท็กไว้ค่อนข้างดี
เพื่อที่จะได้รูปมาใช้ในการเรียนรู้ของเครื่องนั้นยิ่งเยอะยิ่งดี มีสักหลักหมื่นหลักแสนได้ยิ่งดี
วิธีการดึงข้อมูลจากทั้งสองเว็บนี้ก็คล้ายกัน ในที่นี้จะแสดงแค่โค้ดสำหรับดึงข้อมูลจาก safebooru ซึ่งมีข้อมูลมากกว่า
โค้ดนี้มีไว้เพื่อโหลดภาพจาก safebooru ตามแท็กที่ต้องการ จากนั้นก็ใช้ cv2 ค้นหาภาพใบหน้าจากในนั้น พอค้นเสร็จก็ลบภาพเดิมทันที
หากใครที่ตั้งใจจะเอาภาพเต็มแต่แรกไม่ต้องตัดเอาใบหน้าก็อาจลบตรง hana และ os.remove ออกได้ เพียงแต่ว่าภาพที่ได้มีขนาดใหญ่มาก หากไม่ลบทันทีพื้นที่ในเครื่องอาจจะเต็มอย่างรวดเร็ว
thila เป็นตัวกำหนดว่าจะทำทีละกี่งานพร้อมกัน โดยทั่วไปสามารถทำได้ทีละเป็นสิบๆ ยิ่งเยอะยิ่งเร็วแต่เครื่องก็ยิ่งทำงานหนัก ถ้าเต็มขีดจำกัดก็ไม่เร็วขึ้นแล้ว ไหวแค่ไหนขึ้นอยู่กับเครื่อง
ไอดีและแท็กของรูปจะถูกเก็บบันทึกไว้ในไฟล์ด้วย เผื่อนำมาใช้ตอนหลัง และในระหว่างโหลดอาจเจอปัญหาเชื่อมต่อไปม่สำเร็จขึ้น ก็เก็บไอดีของรูปที่มีข้อผิดพลาดเอาไว้ เพื่อจะมาลองใหม่อีกเฉพาะไฟล์ที่พลาดไป
และขอย้ำว่า ให้ระลึกไว้เสมอว่าเมื่อเราใช้โปรแกรมเพื่อดึงข้อมูลแบบนี้จะทำให้เว็บเขาทำงานหนักขึ้นกว่าปกติ ดังนั้นไม่ควรทำเกินความจำเป็น พอได้ข้อมูลที่ต้องการแล้วก็ควรหยุด หากใช้อย่างไม่บันยะบันยังอาจส่งผลเสียต่อเว็บนั้นได้
ดังนั้นโค้ดนี้ขอสงวนไว้ใช้เพื่อการศึกษาเท่านั้น
ต่อไปจะขอแสดงผลที่ได้จากการดึงข้อมูลจากเว็บตามที่ตัวเองได้ลองทำวันก่อน
เริ่มแรกได้ลองล้วงภาพจากเว็บ konachan เอาภาพทั้งหมด พอทำการค้นหาภาพใบหน้าแล้วก็เหลือได้ภาพมา 136059 ภาพ แต่ในนี้ดูแล้วมีที่ใช้ไม่ได้อยู่ส่วนหนึ่ง หากต้องการใช้ให้ได้ประสิทธิภาพสูงก็ยังควรจะมาคัดอีก
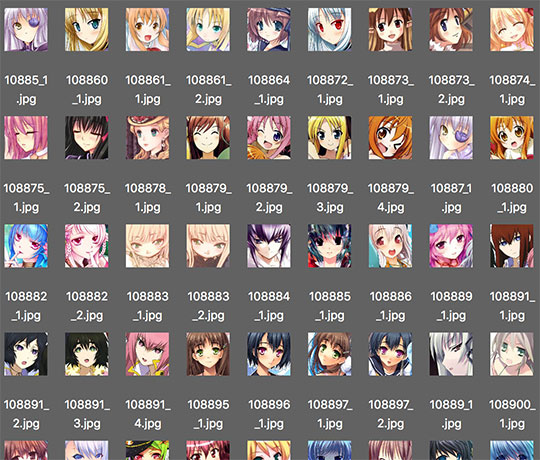
แต่ได้ลองนั่งคัดไปชั่วโมงครึ่ง พบว่าเพิ่งตรวจผ่านไป 3212 ภาพ แค่นี้ก็พอกะประมาณได้ว่าถ้าจะคัดเสร็จคงต้องใช้เวลา 60 กว่าชั่วโมง จึงตัดใจไปซะเลย
เท่าที่ลองพบว่าในจำนวนนั้นคัดเอาแค่ 2200 ภาพ คัดทิ้งไปตั้ง 1212 ภาพ ถ้าเป็นไปตามสัดส่วนนี้พอคัดเสร็จคงเหลือไม่ถึงแสนภาพ
เพียงแต่ว่านี่เป็นการคัดแบบเข้มงวด ตัดอันที่เห็นว่าไม่สวยหรือไม่ชัดทิ้งไปด้วย ถ้าคัดเฉพาะที่ล้มเหลวโดยสมบูรณ์ คือไปตัดเอาอะไรก็ไม่รู้มาหรือตัดเอาหน้าสัตว์มา มีแค่ 112 รูป คิดแล้วเป็น 3% ของภาพทั้งหมด น่าจะยังพอรับไหว
อันนี้เป็นภาพเสียที่คิดออกมาได้
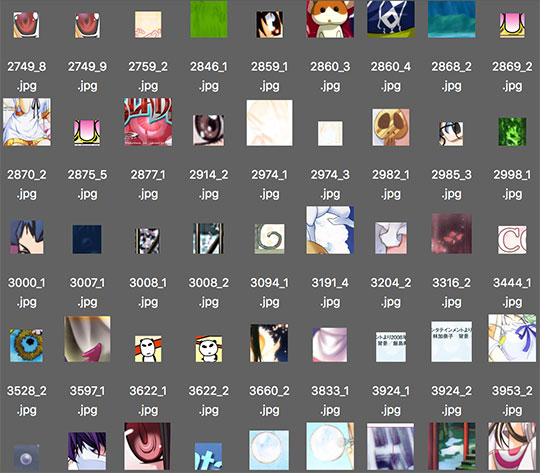
แล้วภาพที่ไม่ดีส่วนใหญ่จะมีขนาดค่อนข้างเล็ก ดังนั้นพอคัดเอาภาพที่เล็กไปออกก็ยิ่งเหลือภาพไม่ดีน้อยลงอีก
สุดท้ายคัดเฉพาะที่มีขนาดใหญ่ 80 ขึ้นไปมาใช้ก็รวมแล้วมีทั้งหมด 117870 ภาพ ส่วนที่ขนาด 96 ขึ้นไปมี 109928 ภาพ
หลังจากนั้นจึงได้มาลองค้นภาพจาก safebooru โดยมีการคัดเลือกแท็กเพื่อกรองรูปเพื่อให้ได้ ซึ่งเป้าหมายจริงๆคือต้องการรูปเด็กผู้หญิงคนเดียวที่หันหน้าเข้าหา นอกจากนี้ยังได้เพิ่มเงื่อนไขเรื่องสีผมเข้าไปด้วย
การทำแบบนี้จะได้ภาพที่มีคุณภาพมากขึ้นกว่า แต่ก็ยังไม่วายมีที่ไม่เกี่ยวข้องปนมาบ้าง ถึงอย่างนั้นก็ดีขึ้นเยอะแล้ว
คราวนี้ลองให้ค้นแค่สาวผมฟ้ากับผมแดง แต่เนื่องจากผมแดงมีน้อยกว่ามาก จึงรวมผมชมพูไปด้วยก็ได้มาเพิ่มอีกเล็กน้อย
สุดท้ายได้ภาพสาวผมฟ้ามา 11457 ภาพ ผมแดง 6513 ภาพ ผมชมพู 1490 ภาพ
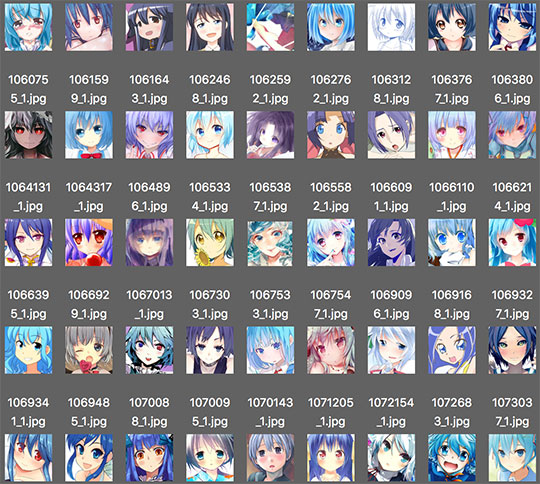
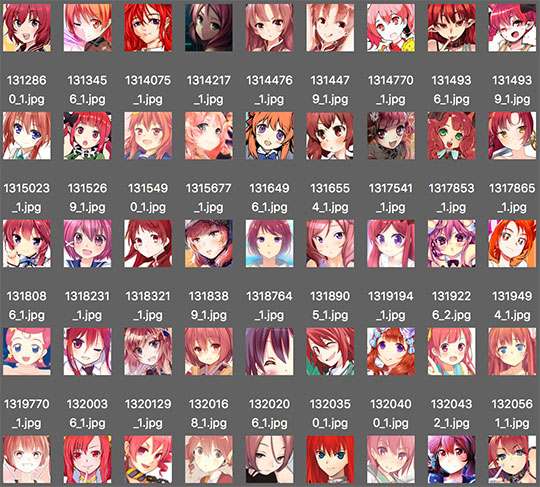
เสร็จแล้วเอามาคัดเฉพาะที่ขนาด 80 ขึ้นไป ก็ได้รวมแล้ว 19008 ภาพ 96 ขึ้นไป 18624 ภาพ
สุดท้ายได้ลองเอาภาพที่ได้มาฝึก DCGAN เพื่อสังเคราะห์ภาพเลียนแบบขึ้นมา ได้อะไรแบบนี้ออกมา

DCGAN ก็คือเทคนิคหนึ่งที่ใช้สร้างภาพเลียนแบบขึ้นจากภาพตัวอย่างที่ป้อนให้โปรแกรมเพื่อเรียนรู้ ภาพที่ได้จะมีลักษณะเหมือนเอาส่วนต่างๆของภาพตัวอย่างมาผสมผสาน เกิดเป็นภาพใหม่ขึ้นมา
เรื่องของ DCGAN จะยังไม่เล่ารายละเอียดตอนนี้ แต่มีเขียนบันทึกไว้เป็นภาษาญี่ปุ่น พร้อมลงโค้ดไว้ ตามอ่านได้ที่ https://qiita.com/phyblas/items/bcab394e1387f15f66ee
แรงบันดาลใจเดิมทีแล้วมาจากเว็บนี้ https://zhuanlan.zhihu.com/p/24767059
ในนี้ได้ลงโค้ดสำหรับดึงข้อมูลจากเว็บ konachan จากนั้นก็นำภาพที่ได้มาเข้าโปรแกรมค้นหาใบหน้าด้วย opencv แล้วสุดท้ายก็จะได้ใบหน้าอนิเมะจำนวนมากจากในเว็บ จึงได้ลองเรียนรู้จากโค้ดในนี้แล้วดัดแปลงเขียนขึ้นใหม่ในแบบของตัวเอง
เรื่องของการล้วงข้อมูลจากเว็บได้เขียนถึงไว้แล้วใน https://phyblas.hinaboshi.com/20180320 และ https://phyblas.hinaboshi.com/20180323
ส่วนเรื่องการค้นหาใบหน้าด้วย opencv ก็เขียนถึงไปใน https://phyblas.hinaboshi.com/20180326
และเพื่อเร่งความเร็วจึงใช้ multiprocessing เข้าร่วมได้ ก็มีเขียนถึงไปใน https://phyblas.hinaboshi.com/20180317
เว็บเป้าหมายสำหรับครั้งนี้มีอยู่ ๒ แหล่ง คือเว็บ https://konachan.net และ https://safebooru.org ซึ่งเป็นแหล่งรวมภาพอนิเมะที่มีคนเอามาลงไว้มากมาย
ทาง konachan นั้นมีภาพน้อยกว่า คือรวมแล้วแสนกว่าภาพ แต่ safebooru มีกว่าสองล้านภาพ ดังนั้นตอนที่ค้นข้อมูล konachan จึงดึงรูปมาทั้งหมด แต่ safebooru นั้นมีเยอะจึงค้นเอาเฉพาะแท็กที่ต้องการ เพราะไม่เช่นนั้นจะเยอะ เว็บนี้ทำระบบแท็กไว้ค่อนข้างดี
เพื่อที่จะได้รูปมาใช้ในการเรียนรู้ของเครื่องนั้นยิ่งเยอะยิ่งดี มีสักหลักหมื่นหลักแสนได้ยิ่งดี
วิธีการดึงข้อมูลจากทั้งสองเว็บนี้ก็คล้ายกัน ในที่นี้จะแสดงแค่โค้ดสำหรับดึงข้อมูลจาก safebooru ซึ่งมีข้อมูลมากกว่า
import multiprocessing as mp
import requests,os,re,time,cv2,traceback
from bs4 import BeautifulSoup as Bs
# ฟังก์ชันสำหรับค้นหาใบหน้าภายในรูป
def hana(chuefilerup,idrup):
rup = cv2.imread(chuefilerup,cv2.IMREAD_COLOR)
raisi = cv2.equalizeHist(cv2.cvtColor(rup,cv2.COLOR_BGR2GRAY))
hachoe = cascade.detectMultiScale(raisi,1.1,minSize=(leksut,leksut))
for j,(x,y,w,h) in enumerate(hachoe,1):
baina = rup[y:y+h,x:x+w,:]
chuetem = os.path.join(folderrup,idrup+'_%d.jpg'%j)
if(not os.path.exists(chuetem)):
cv2.imwrite(chuetem,baina)
# ฟังก์ชันค้นรูป
def khonrup(pid):
t0 = time.time()
nathi = int(pid/40)+1
# เปิดไฟล์เพื่อดูว่าภาพไหนมีแล้ว
with open(filemilaeo) as f:
milaeo = [s.split(' ')[0] for s in f.readlines()]
html_nalist = requests.get(url_nalist+'%d'%pid).text
sup_nalist = Bs(html_nalist, 'lxml')
# ค้นหาภาพเล็กในแต่ละหน้า
for thumb in sup_nalist.find_all('span',class_='thumb'):
idrup = thumb['id'][1:] # ไอดีรูป
if(idrup in milaeo):
print('%s มีแล้ว'%idrup)
continue
href = chueweb+thumb.find('a')['href']
html_narup = requests.get(href).text # อ่านหน้าเว็บของรูปนั้น
sup_narup = Bs(html_narup, 'lxml')
url_rup = sup_narup.find('img',id='image')
# ถ้ามีข้อผิดพลาดก็ขึ้นเตือนแล้วข้ามไป
if(not url_rup):
print('หน้า %d รูป %s มีข้อผิดพลาด'%(nathi,idrup))
with open(filephitphlat,'a') as f: # บันทึกไอดีรูปที่มีข้อผิดพลาด
f.write(idrup+'\n')
continue
url_rup = 'https:'+url_rup['src']
tag = sup_narup.find('img',id='image')['alt'] # แท็กทั้งหมดของภาพ
sakunrup = re.findall(r'.(\.\w+)\?',url_rup)[0] # สกุลภาพ
if(sakunrup=='gif'): # ไม่เอาภาพ gif
print('หน้า %d รูป %s เป็น gif'%(nathi,idrup))
continue
chuefilerup = idrup+sakunrup
try:
# อ่านข้อมูลไฟล์ภาพแล้วบันทึก
r = requests.get(url_rup,stream=True,timeout=60)
r.raise_for_status()
with open(chuefilerup,'wb') as f:
for c in r.iter_content(1024):
if c:
f.write(c)
hana(chuefilerup,idrup) # ค้นหาใบหน้าจากในรูป
os.remove(chuefilerup) # หาเจอเสร็จก็ลบทิ้ง
# บันทึกไอดีภาพพร้อมแท็กลงไฟล์
with open(filemilaeo,'a') as f:
f.write(idrup +' '+tag+'\n')
print('หน้า %d รูป %s ผ่านไปแล้ว %.3f นาที'%(nathi,idrup,(time.time()-t0)/60))
except KeyboardInterrupt: # กรณีที่กด ctrl+c เพื่อหยุด ก็ให้หยุด
if os.path.exists(chuefilerup):
os.remove(chuefilerup)
raise KeyboardInterrupt
except Exception: # กรณีที่เกิดข้อผิดพลาดเหนือความคาดหมาย ก็ให้ขึ้นเตือนแต่ก็ยังทำต่อไป
traceback.print_exc()
if os.path.exists(chuefilerup):
os.remove(chuefilerup)
print('หน้า %d รูป %s มีข้อผิดพลาด'%(nathi,idrup))
with open(filephitphlat,'a') as f: # บันทึกไอดีรูปที่มีข้อผิดพลาด
f.write(idrup+'\n')
if(__name__=='__main__'):
cascade_file = 'lbpcascade_animeface.xml'
folderrup = 'rupsaophomfa' # โฟลเดอร์ที่จะบันทึกรูปที่ได้
filemilaeo = 'milaeo.txt' # ไฟล์ที่จะบันทึกไอดีและแท็กของรูปที่มีแล้ว
filephitphlat = 'phitphlat.txt' # ไฟล์ที่เก็บไอดีของรูปที่มีข้อผิดพลาดเอาไว้เพื่อจะลองใหม่
tag_ao = '1girl blue_hair looking_at_viewer' # แท็กที่จะเอา
tag_maiao = '1boy multiple_boys multicolored_hair looking_back chibi hood hat red_hair' # แท็กที่จะกรองออก
leksut = 48 # ขนาดเล็กสุดของรูปใบหน้าที่จะเอา
thila = 4 # จำนวนหน้าที่จะโหลดพร้อมกัน
sutthai = 10000 # จำนวนรูปที่ต้องการ
cascade = cv2.CascadeClassifier(cascade_file)
# ไฟล์หรือโฟลเดอร์ที่ยังไม่มีก็สร้างไว้ก่อน
if not os.path.exists(folderrup):
os.makedirs(folderrup)
if not os.path.exists(filemilaeo):
with open(filemilaeo,'w') as f: 0
if not os.path.exists(filephitphlat):
with open(filephitphlat,'w') as f: 0
chueweb = 'https://safebooru.org/'
url_nalist = chueweb+'index.php?page=post&s=list&tags='
url_nalist += ''.join(['+'+s for s in tag_ao.split()] + ['+-'+s for s in tag_maiao.split()])
url_nalist += '&pid='
p = mp.Pool(processes=thila)
for i in range(0,sutthai+1,thila*40):
p.map(khonrup,range(i,i+thila*40,40))โค้ดนี้มีไว้เพื่อโหลดภาพจาก safebooru ตามแท็กที่ต้องการ จากนั้นก็ใช้ cv2 ค้นหาภาพใบหน้าจากในนั้น พอค้นเสร็จก็ลบภาพเดิมทันที
หากใครที่ตั้งใจจะเอาภาพเต็มแต่แรกไม่ต้องตัดเอาใบหน้าก็อาจลบตรง hana และ os.remove ออกได้ เพียงแต่ว่าภาพที่ได้มีขนาดใหญ่มาก หากไม่ลบทันทีพื้นที่ในเครื่องอาจจะเต็มอย่างรวดเร็ว
thila เป็นตัวกำหนดว่าจะทำทีละกี่งานพร้อมกัน โดยทั่วไปสามารถทำได้ทีละเป็นสิบๆ ยิ่งเยอะยิ่งเร็วแต่เครื่องก็ยิ่งทำงานหนัก ถ้าเต็มขีดจำกัดก็ไม่เร็วขึ้นแล้ว ไหวแค่ไหนขึ้นอยู่กับเครื่อง
ไอดีและแท็กของรูปจะถูกเก็บบันทึกไว้ในไฟล์ด้วย เผื่อนำมาใช้ตอนหลัง และในระหว่างโหลดอาจเจอปัญหาเชื่อมต่อไปม่สำเร็จขึ้น ก็เก็บไอดีของรูปที่มีข้อผิดพลาดเอาไว้ เพื่อจะมาลองใหม่อีกเฉพาะไฟล์ที่พลาดไป
และขอย้ำว่า ให้ระลึกไว้เสมอว่าเมื่อเราใช้โปรแกรมเพื่อดึงข้อมูลแบบนี้จะทำให้เว็บเขาทำงานหนักขึ้นกว่าปกติ ดังนั้นไม่ควรทำเกินความจำเป็น พอได้ข้อมูลที่ต้องการแล้วก็ควรหยุด หากใช้อย่างไม่บันยะบันยังอาจส่งผลเสียต่อเว็บนั้นได้
ดังนั้นโค้ดนี้ขอสงวนไว้ใช้เพื่อการศึกษาเท่านั้น
ต่อไปจะขอแสดงผลที่ได้จากการดึงข้อมูลจากเว็บตามที่ตัวเองได้ลองทำวันก่อน
เริ่มแรกได้ลองล้วงภาพจากเว็บ konachan เอาภาพทั้งหมด พอทำการค้นหาภาพใบหน้าแล้วก็เหลือได้ภาพมา 136059 ภาพ แต่ในนี้ดูแล้วมีที่ใช้ไม่ได้อยู่ส่วนหนึ่ง หากต้องการใช้ให้ได้ประสิทธิภาพสูงก็ยังควรจะมาคัดอีก
แต่ได้ลองนั่งคัดไปชั่วโมงครึ่ง พบว่าเพิ่งตรวจผ่านไป 3212 ภาพ แค่นี้ก็พอกะประมาณได้ว่าถ้าจะคัดเสร็จคงต้องใช้เวลา 60 กว่าชั่วโมง จึงตัดใจไปซะเลย
เท่าที่ลองพบว่าในจำนวนนั้นคัดเอาแค่ 2200 ภาพ คัดทิ้งไปตั้ง 1212 ภาพ ถ้าเป็นไปตามสัดส่วนนี้พอคัดเสร็จคงเหลือไม่ถึงแสนภาพ
เพียงแต่ว่านี่เป็นการคัดแบบเข้มงวด ตัดอันที่เห็นว่าไม่สวยหรือไม่ชัดทิ้งไปด้วย ถ้าคัดเฉพาะที่ล้มเหลวโดยสมบูรณ์ คือไปตัดเอาอะไรก็ไม่รู้มาหรือตัดเอาหน้าสัตว์มา มีแค่ 112 รูป คิดแล้วเป็น 3% ของภาพทั้งหมด น่าจะยังพอรับไหว
อันนี้เป็นภาพเสียที่คิดออกมาได้
แล้วภาพที่ไม่ดีส่วนใหญ่จะมีขนาดค่อนข้างเล็ก ดังนั้นพอคัดเอาภาพที่เล็กไปออกก็ยิ่งเหลือภาพไม่ดีน้อยลงอีก
สุดท้ายคัดเฉพาะที่มีขนาดใหญ่ 80 ขึ้นไปมาใช้ก็รวมแล้วมีทั้งหมด 117870 ภาพ ส่วนที่ขนาด 96 ขึ้นไปมี 109928 ภาพ
หลังจากนั้นจึงได้มาลองค้นภาพจาก safebooru โดยมีการคัดเลือกแท็กเพื่อกรองรูปเพื่อให้ได้ ซึ่งเป้าหมายจริงๆคือต้องการรูปเด็กผู้หญิงคนเดียวที่หันหน้าเข้าหา นอกจากนี้ยังได้เพิ่มเงื่อนไขเรื่องสีผมเข้าไปด้วย
การทำแบบนี้จะได้ภาพที่มีคุณภาพมากขึ้นกว่า แต่ก็ยังไม่วายมีที่ไม่เกี่ยวข้องปนมาบ้าง ถึงอย่างนั้นก็ดีขึ้นเยอะแล้ว
คราวนี้ลองให้ค้นแค่สาวผมฟ้ากับผมแดง แต่เนื่องจากผมแดงมีน้อยกว่ามาก จึงรวมผมชมพูไปด้วยก็ได้มาเพิ่มอีกเล็กน้อย
สุดท้ายได้ภาพสาวผมฟ้ามา 11457 ภาพ ผมแดง 6513 ภาพ ผมชมพู 1490 ภาพ
เสร็จแล้วเอามาคัดเฉพาะที่ขนาด 80 ขึ้นไป ก็ได้รวมแล้ว 19008 ภาพ 96 ขึ้นไป 18624 ภาพ
สุดท้ายได้ลองเอาภาพที่ได้มาฝึก DCGAN เพื่อสังเคราะห์ภาพเลียนแบบขึ้นมา ได้อะไรแบบนี้ออกมา
DCGAN ก็คือเทคนิคหนึ่งที่ใช้สร้างภาพเลียนแบบขึ้นจากภาพตัวอย่างที่ป้อนให้โปรแกรมเพื่อเรียนรู้ ภาพที่ได้จะมีลักษณะเหมือนเอาส่วนต่างๆของภาพตัวอย่างมาผสมผสาน เกิดเป็นภาพใหม่ขึ้นมา
เรื่องของ DCGAN จะยังไม่เล่ารายละเอียดตอนนี้ แต่มีเขียนบันทึกไว้เป็นภาษาญี่ปุ่น พร้อมลงโค้ดไว้ ตามอ่านได้ที่ https://qiita.com/phyblas/items/bcab394e1387f15f66ee