pytorch เบื้องต้น บทที่ ๑๒: โครงข่ายประสาทเทียมแบบคอนโวลูชัน (CNN)
เขียนเมื่อ 2018/09/16 14:35
แก้ไขล่าสุด 2022/07/09 16:22
>> ต่อจาก บทที่ ๑๑
บทนี้จะเป็นวิธีการสร้างโครงข่ายประสาทเทียมแบบคอนโวลูชัน (卷积神经网路, convolutional neural network, CNN)
โครงข่ายประสาทเทียมแบบคอนโวลูชันมีส่วนประกอบที่เพิ่มขึ้นมาจากเพอร์เซปตรอนหลายชั้นแบบธรรมดาคือมีส่วนที่ประกอบขึ้นจากชั้นคอนโวลูชัน (convolution layer) และชั้นบ่อรวม (pooling layer)
ชั้นคอนโวลูชัน
ใน pytorch ได้เตรียมชั้นคอนโวลูชันแยกตามมิติของข้อมูล คือ
- torch.nn.Conv1d
- torch.nn.Conv2d
- torch.nn.Conv3d
ค่าที่ต้องระบุ เรียงตามลำดับดังนี้
in_channels = จำนวนช่องข้อมูลขาเข้า
out_channels = จำนวนช่องข้อมูลขาออก
kernel_size = ขนาดตัวกรอง
ส่วนค่าต่อไปนี้เป็นตัวเลือกเสริม
stride = จำนวนช่องที่เลื่อนต่อครั้ง ค่าตั้งต้นคือ 1
padding = ค่า 0 ที่เติมเสริมที่ขอบ ค่าตั้งต้นคือ 0
bias = ให้มีพารามิเตอร์ไบแอสหรือไม่ ค่าตั้งต้นคือ True
กรณีสองมิติขึ้นไป kernel_size, stride และ padding นั้นถ้าใส่ค่าเป็นเลขตัวเดียวจะมีผลกับทุกมิติ แต่ถ้าใส่เป็นทูเพิลจะแยกค่าของแต่ละมิติ
ขนาดของพารามิเตอร์น้ำหนักคือ (out_channels,in_channels,kernel_size[0],kernel_size[1]) ส่วนไบแอสจะมีขนาดเป็น out_channels
ชั้นบ่อรวม
ชั้นบ่อรวมสูงสุด (max pooling) คือ
- torch.nn.MaxPool1d
- torch.nn.MaxPool2d
- torch.nn.MaxPool3d
ส่วนชั้นบ่อรวมเฉลี่ย (average pooling) คือ
- torch.nn.AvgPool1d
- torch.nn.AvgPool2d
- torch.nn.AvgPool3d
ค่าที่ต้องใส่คือ
kernel_size = ขนาดตัวกรอง
ค่าตัวเลือกเพิ่มเติมคือ
stride = จำนวนช่องที่เลื่อนต่อครั้ง ค่าตั้งต้นคือเท่ากับขนาดเคอร์เนล
padding = ค่า 0 ที่เติมเสริมที่ขอบ ค่าตั้งต้นคือ 0
ceil_mode = ถ้าเป็น True จะเก็บเอาเศษที่เลื่อนแล้วเหลือไม่ครบตามขนาดตัวกรองด้วย ถ้า false จะทิ้งไป ค่าตั้งต้นคือ False
นอกจากนี้ ยังมีบ่อรวมแบบปรับแต่งได้ (adaptive) ซึ่งจะต่างจากแบบธรรมดาตรงที่จะกำหนดขนาดของข้อมูลขาออก แทนที่จะกำหนดว่าให้กรองกี่ตัวเป็นตัวเดียว แบบนี้จะสะดวกเวลาที่ใช้กับข้อมูลที่มีขนาดไม่แน่นอน
- torch.nn.AdaptiveMaxPool1d
- torch.nn.AdaptiveMaxPool2d
- torch.nn.AdaptiveMaxPool3d
- torch.nn.AdaptiveAvgPool1d
- torch.nn.AdaptiveAvgPool2d
- torch.nn.AdaptiveAvgPool3d
สำหรับชั้นแบบนี้สิ่งที่ต้องกำหนดมีแค่ output_size ที่ต้องการ
สร้างโครงข่ายประสาท
เพื่อแสดงตัวอย่างการใช้ง่ายๆ ขอเริ่มจากลองสร้างโครงข่ายขึ้นโดยใช้ Module ง่ายๆ ดังนี้
โครงข่ายประกอบไปด้วยชั้นคอนโวลูชัน ๒ ชั้น และชั้นเชิงเส้น ๒ ชั้น โดยแต่ละชั้นมีการใช้แบตช์นอร์มด้วย
แบตช์นอร์มที่ใช้ระหว่างชั้นคอนโวลูชันจะเป็น BatchNorm2d ในขณะที่แบตช์นอร์มระหว่างชั้นเชิงเส้นจะเป็น BatchNorm1d
ลองนำโครงข่ายมาใช้วิเคราะห์ข้อมูลตัวเลข MNIST
ได้
จะพบว่าแค่วนครบรอบแรกก็ทายได้แม่นเกือบ 99% แล้ว แสดงให้เห็นว่าโครงข่ายประสาทเทียมแค่แบบง่ายๆนี้ก็ใช้การได้ดีมากแล้วกับข้อมูลชุดนี้
ข้อควรระวังเรื่องมิติของข้อมูล
ครั้งนี้เราใช้ torchvision.datasets โหลดข้อมูลรูป รูปจึงถูกแปลงเทนเซอร์สี่มิติขนาดเท่ากับ (จำนวนภาพ,สี,ความสูง,ความกว้าง)
ถ้าเราเปิดไฟล์ข้อมูลรูปภาพเอาเองโดยไม่ได้ใช้วิธีนี้ละก็ ต้องอย่าลืมแปลงเทนเซอร์เป็นขนาดแบบนี้ด้วย ปกติรูปที่โหลดด้วยคำสั่งอ่านรูปเช่นใน matplotlib จะได้อาเรย์ในรูป (ความสูง,ความกว้าง,สี) ซึ่งลำดับไม่ตรงกับที่ชั้นคอนโวลูชันต้องการ กรณีแบบนี้ต้องสลับแกนให้เรียบร้อย
กรณีภาพขาวดำ มิติของสีจะมีแค่ 1 แต่ยังไงก็ต้องมีมิตินั้นอยู่ จำนวนช่องข้อมูลขาเข้าจะเป็น 1 ขนาดข้อมูลป้อนเข้าจะกลายเป็น (จำนวนภาพ,1,ความสูง,ความกว้าง)
ใช้ Sequential
ในตัวอย่างที่แล้วจะเห็นว่าใน forward มีการคำนวณเป็นลำดับขั้น แบบนี้ควรใช้ Sequential เขียนเพื่อจะได้ไม่ต้องมานิยาม forward
ปัญหาอยู่ตรงขั้นตอน h2 ที่มีการ reshape ตรงนี้จำเป็นต้องนิยามชั้นขึ้นมาเสริมเพื่อใช้ในการเปลี่ยนรูป
เราอาจนิยามชั้นสำหรับทำการเปลี่ยนรูปเทนเซอร์ได้ดังนี้
ถ้าป้อนค่าเป็น -1 ก็จะเป็นการยุบมิติที่สองขึ้นไปให้มารวมเป็นมิติเดียว เหลือสองมิติ
แบบจำลองเดิม ถ้าใช้ Sequential อาจสร้างได้ง่ายๆในลักษณะนี้
สร้างแบบจำลองให้ปรับส่วนประกอบได้
เพื่อความสะดวกในการสร้างข้อมูลหลายชั้น เพื่อจะได้ไม่ต้องพิมพ์ซ้ำไปมา และสามารถปรับแต่งได้ง่าย คราวนี้จะลองสร้างเป็นคลาสของโครงข่ายประสาทแบบสำเร็จรูปที่ปรับรูปแบบได้โดยแค่เปลี่ยนแก้ตัวเลข
ส่วนประกอบมีดังนี้
- กำหนดจำนวนชั้นคอนโวลูชันและขนาดตัวกรองได้
- ให้ตั้งว่าจะให้มีแบตช์นอร์มหรือดรอปเอาต์หรือเปล่าได้
- ตั้งค่าน้ำหนักตั้งต้นแจกแจงปกติแบบเหอ ไข่หมิง ไบแอสตั้งต้นเป็น 0
- ชั้นคำนวณเชิงเส้นสร้างโดยกำหนดแค่ขนาดขาออก
- ขนาดขาเข้าของชั้นคำนวณเชิงเส้นชั้นแรกจะถูกคำนวณโดยอัตโนมัติ
ขนาดข้อมูลขาเข้าของชั้นคำนวณเชิงเส้นจะต้องสัมพันธ์กับขนาดของข้อมูลขาออกของชั้นคอนโวลูชันชั้นสุดท้าย เราสามารถเขียนให้มีการคำนวณขนาดที่ควรเป็นตรงนี้โดยอัตโนมัติเพื่อจะได้ปรับขนาดชั้นคอนโวลูชันได้โดยไม่ตรงกังวลตรงนี้
เราอาจเขียน Sequential ให้เป็นคลาสของโครงข่ายตามแบบที่อธิบายมาได้ดังนี้
ในส่วนของเมธอด .rianru() นั้นข้อมูลป้อนเข้าคือข้อมูลฝึกในรูปของ DataLoader สำหรับทำมินิแบตช์ และข้อมูลตรวจสอบในรูปของเทนเซอร์ของข้อมูลทั้งหมด
ข้อมูลตรวจสอบใช้เพื่อเป็นเงื่อนไขในการหยุด ถ้าความแม่นยำในการทำนายข้อมูลตรวจสอบไม่เพิ่มหลังจากฝึกต่อไปแล้วเป็นจำนวนกี่ครั้งตามที่กำหนดก็ให้สิ้นสุดการเรียนรู้
คราวนี้ลองทดสอบกับข้อมูล FashionMNIST บ้าง ส่วนประกอบต่างๆจะเหมือนกับข้อมูล MNIST ธรรมดา แต่จะยากกว่าหน่อย
เนื่องจากเป็นข้อมูลเสื้อผ้า ดังนั้นการนำภาพมากลับซ้ายขวาจึงช่วยเพิ่มความหลากหลายในการเรียนรู้ได้ เราสามารถใช้ตัวเลือกแปลง tf.RandomHorizontalFlip() ได้ สำหรับชุดข้อมูลฝึก ส่วนชุดข้อมูลทดสอบไม่จำเป็นต้องทำก็ได้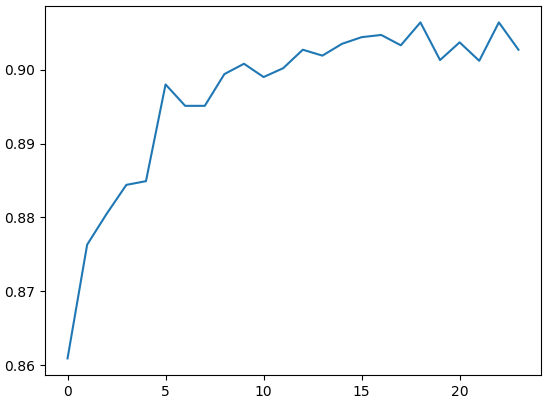
ผลออกมาไม่ดีมากเท่าชุดข้อมูลตัวเลข แต่ก็ถึง 90% ได้เหมือนกัน
บทนี้จะเป็นวิธีการสร้างโครงข่ายประสาทเทียมแบบคอนโวลูชัน (卷积神经网路, convolutional neural network, CNN)
โครงข่ายประสาทเทียมแบบคอนโวลูชันมีส่วนประกอบที่เพิ่มขึ้นมาจากเพอร์เซปตรอนหลายชั้นแบบธรรมดาคือมีส่วนที่ประกอบขึ้นจากชั้นคอนโวลูชัน (convolution layer) และชั้นบ่อรวม (pooling layer)
ชั้นคอนโวลูชัน
ใน pytorch ได้เตรียมชั้นคอนโวลูชันแยกตามมิติของข้อมูล คือ
- torch.nn.Conv1d
- torch.nn.Conv2d
- torch.nn.Conv3d
ค่าที่ต้องระบุ เรียงตามลำดับดังนี้
in_channels = จำนวนช่องข้อมูลขาเข้า
out_channels = จำนวนช่องข้อมูลขาออก
kernel_size = ขนาดตัวกรอง
ส่วนค่าต่อไปนี้เป็นตัวเลือกเสริม
stride = จำนวนช่องที่เลื่อนต่อครั้ง ค่าตั้งต้นคือ 1
padding = ค่า 0 ที่เติมเสริมที่ขอบ ค่าตั้งต้นคือ 0
bias = ให้มีพารามิเตอร์ไบแอสหรือไม่ ค่าตั้งต้นคือ True
กรณีสองมิติขึ้นไป kernel_size, stride และ padding นั้นถ้าใส่ค่าเป็นเลขตัวเดียวจะมีผลกับทุกมิติ แต่ถ้าใส่เป็นทูเพิลจะแยกค่าของแต่ละมิติ
ขนาดของพารามิเตอร์น้ำหนักคือ (out_channels,in_channels,kernel_size[0],kernel_size[1]) ส่วนไบแอสจะมีขนาดเป็น out_channels
import torch
conv1 = torch.nn.Conv1d(3,4,5)
print(conv1.weight.shape) # ได้ torch.Size([4, 3, 5])
conv2 = torch.nn.Conv2d(3,4,5)
print(conv2.weight.shape) # ได้ torch.Size([4, 3, 5, 5])
conv2 = torch.nn.Conv2d(3,4,[5,6])
print(conv2.weight.shape) # ได้ torch.Size([4, 3, 5, 6])
print(conv2.bias.shape) # ได้ torch.Size([4])ชั้นบ่อรวม
ชั้นบ่อรวมสูงสุด (max pooling) คือ
- torch.nn.MaxPool1d
- torch.nn.MaxPool2d
- torch.nn.MaxPool3d
ส่วนชั้นบ่อรวมเฉลี่ย (average pooling) คือ
- torch.nn.AvgPool1d
- torch.nn.AvgPool2d
- torch.nn.AvgPool3d
ค่าที่ต้องใส่คือ
kernel_size = ขนาดตัวกรอง
ค่าตัวเลือกเพิ่มเติมคือ
stride = จำนวนช่องที่เลื่อนต่อครั้ง ค่าตั้งต้นคือเท่ากับขนาดเคอร์เนล
padding = ค่า 0 ที่เติมเสริมที่ขอบ ค่าตั้งต้นคือ 0
ceil_mode = ถ้าเป็น True จะเก็บเอาเศษที่เลื่อนแล้วเหลือไม่ครบตามขนาดตัวกรองด้วย ถ้า false จะทิ้งไป ค่าตั้งต้นคือ False
นอกจากนี้ ยังมีบ่อรวมแบบปรับแต่งได้ (adaptive) ซึ่งจะต่างจากแบบธรรมดาตรงที่จะกำหนดขนาดของข้อมูลขาออก แทนที่จะกำหนดว่าให้กรองกี่ตัวเป็นตัวเดียว แบบนี้จะสะดวกเวลาที่ใช้กับข้อมูลที่มีขนาดไม่แน่นอน
- torch.nn.AdaptiveMaxPool1d
- torch.nn.AdaptiveMaxPool2d
- torch.nn.AdaptiveMaxPool3d
- torch.nn.AdaptiveAvgPool1d
- torch.nn.AdaptiveAvgPool2d
- torch.nn.AdaptiveAvgPool3d
สำหรับชั้นแบบนี้สิ่งที่ต้องกำหนดมีแค่ output_size ที่ต้องการ
สร้างโครงข่ายประสาท
เพื่อแสดงตัวอย่างการใช้ง่ายๆ ขอเริ่มจากลองสร้างโครงข่ายขึ้นโดยใช้ Module ง่ายๆ ดังนี้
relu = torch.nn.ReLU()
ha_entropy = torch.nn.CrossEntropyLoss()
maxp = torch.nn.MaxPool2d(2)
class Khrongkhai(torch.nn.Module):
def __init__(self):
super(Khrongkhai,self).__init__()
self.c1 = torch.nn.Conv2d(1,16,5,1,0)
self.b1 = torch.nn.BatchNorm2d(16)
self.c2 = torch.nn.Conv2d(16,16,5,1,0)
self.b2 = torch.nn.BatchNorm2d(16)
self.l1 = torch.nn.Linear(4*4*16,16)
self.b3 = torch.nn.BatchNorm1d(16)
self.l2 = torch.nn.Linear(16,10)
def forward(self,X):
a1 = self.c1(X)
r1 = relu(a1)
d1 = self.b1(r1)
h1 = maxp(d1)
a2 = self.c2(h1)
r2 = relu(a2)
d2 = self.b2(r2)
h2 = maxp(d2).reshape(len(X),-1)
a3 = self.l1(h2)
r3 = relu(a3)
h3 = self.b3(r3)
a4 = self.l2(h3)
return a4โครงข่ายประกอบไปด้วยชั้นคอนโวลูชัน ๒ ชั้น และชั้นเชิงเส้น ๒ ชั้น โดยแต่ละชั้นมีการใช้แบตช์นอร์มด้วย
แบตช์นอร์มที่ใช้ระหว่างชั้นคอนโวลูชันจะเป็น BatchNorm2d ในขณะที่แบตช์นอร์มระหว่างชั้นเชิงเส้นจะเป็น BatchNorm1d
ลองนำโครงข่ายมาใช้วิเคราะห์ข้อมูลตัวเลข MNIST
from torch.utils.data import DataLoader as Dalo
import torchvision.datasets as ds
import torchvision.transforms as tf
import time
folder_mnist = '~/pytorchdata/mnist'
tran = tf.Compose([tf.ToTensor(),tf.Normalize((0.5,),(0.5,))])
rup_fuek = ds.MNIST(folder_mnist,transform=tran,train=1) # ข้อมูลฝึก
rup_truat = ds.MNIST(folder_mnist,transform=tran,train=0) # ข้อมูลตรวจสอบ
minibatch = Dalo(rup_fuek,batch_size=64,shuffle=True) # ข้อมูลฝึกทำเป็นมินิแบตช์
X_truat,z_truat = list(Dalo(rup_truat,10000))[0] # ข้อมูลตรวจสอบนำมาใช้ทีเดียว
khrongkhai = Khrongkhai()
opt = torch.optim.Adam(khrongkhai.parameters(),lr=0.001)
lis_khanaen = [] # ลิสต์บันทึกคะแนนในแต่ละขั้น
t_roem = time.time()
for o in range(5):
khrongkhai.train()
for Xb,zb in minibatch:
a = khrongkhai(Xb)
J = ha_entropy(a,zb)
J.backward()
opt.step()
opt.zero_grad()
khrongkhai.eval()
khanaen = (khrongkhai(X_truat).argmax(1)==z_truat).numpy().mean() # คำนวณคะแนนความแม่นในการทายข้อมูลตรวจสอบ
lis_khanaen.append(khanaen)
print('%d ครั้งผ่านไป ใช้เวลาไป %.1f นาที ทำนายแม่น %.4f'%(o+1,(time.time()-t_roem)/60,khanaen))ได้
1 ครั้งผ่านไป ใช้เวลาไป 0.8 นาที ทำนายแม่น 0.9865
2 ครั้งผ่านไป ใช้เวลาไป 1.6 นาที ทำนายแม่น 0.9887
3 ครั้งผ่านไป ใช้เวลาไป 2.5 นาที ทำนายแม่น 0.9891
4 ครั้งผ่านไป ใช้เวลาไป 3.4 นาที ทำนายแม่น 0.9895
5 ครั้งผ่านไป ใช้เวลาไป 4.3 นาที ทำนายแม่น 0.9885จะพบว่าแค่วนครบรอบแรกก็ทายได้แม่นเกือบ 99% แล้ว แสดงให้เห็นว่าโครงข่ายประสาทเทียมแค่แบบง่ายๆนี้ก็ใช้การได้ดีมากแล้วกับข้อมูลชุดนี้
ข้อควรระวังเรื่องมิติของข้อมูล
ครั้งนี้เราใช้ torchvision.datasets โหลดข้อมูลรูป รูปจึงถูกแปลงเทนเซอร์สี่มิติขนาดเท่ากับ (จำนวนภาพ,สี,ความสูง,ความกว้าง)
ถ้าเราเปิดไฟล์ข้อมูลรูปภาพเอาเองโดยไม่ได้ใช้วิธีนี้ละก็ ต้องอย่าลืมแปลงเทนเซอร์เป็นขนาดแบบนี้ด้วย ปกติรูปที่โหลดด้วยคำสั่งอ่านรูปเช่นใน matplotlib จะได้อาเรย์ในรูป (ความสูง,ความกว้าง,สี) ซึ่งลำดับไม่ตรงกับที่ชั้นคอนโวลูชันต้องการ กรณีแบบนี้ต้องสลับแกนให้เรียบร้อย
กรณีภาพขาวดำ มิติของสีจะมีแค่ 1 แต่ยังไงก็ต้องมีมิตินั้นอยู่ จำนวนช่องข้อมูลขาเข้าจะเป็น 1 ขนาดข้อมูลป้อนเข้าจะกลายเป็น (จำนวนภาพ,1,ความสูง,ความกว้าง)
ใช้ Sequential
ในตัวอย่างที่แล้วจะเห็นว่าใน forward มีการคำนวณเป็นลำดับขั้น แบบนี้ควรใช้ Sequential เขียนเพื่อจะได้ไม่ต้องมานิยาม forward
ปัญหาอยู่ตรงขั้นตอน h2 ที่มีการ reshape ตรงนี้จำเป็นต้องนิยามชั้นขึ้นมาเสริมเพื่อใช้ในการเปลี่ยนรูป
เราอาจนิยามชั้นสำหรับทำการเปลี่ยนรูปเทนเซอร์ได้ดังนี้
class Plianrup(torch.nn.Module):
def __init__(self,*k):
super(Plianrup,self).__init__()
self.k = k
def forward(self,x):
return x.reshape(x.size()[0],*self.k)ถ้าป้อนค่าเป็น -1 ก็จะเป็นการยุบมิติที่สองขึ้นไปให้มารวมเป็นมิติเดียว เหลือสองมิติ
แบบจำลองเดิม ถ้าใช้ Sequential อาจสร้างได้ง่ายๆในลักษณะนี้
khrongkhai = torch.nn.Sequential(
torch.nn.Conv2d(1,16,5,1,0),
relu,
torch.nn.BatchNorm2d(16),
maxp,
torch.nn.Conv2d(16,16,5,1,0),
relu,
torch.nn.BatchNorm2d(16),
maxp,
Plianrup(-1),
torch.nn.Linear(4*4*16,16),
relu,
torch.nn.BatchNorm1d(16),
torch.nn.Linear(16,10)
)สร้างแบบจำลองให้ปรับส่วนประกอบได้
เพื่อความสะดวกในการสร้างข้อมูลหลายชั้น เพื่อจะได้ไม่ต้องพิมพ์ซ้ำไปมา และสามารถปรับแต่งได้ง่าย คราวนี้จะลองสร้างเป็นคลาสของโครงข่ายประสาทแบบสำเร็จรูปที่ปรับรูปแบบได้โดยแค่เปลี่ยนแก้ตัวเลข
ส่วนประกอบมีดังนี้
- กำหนดจำนวนชั้นคอนโวลูชันและขนาดตัวกรองได้
- ให้ตั้งว่าจะให้มีแบตช์นอร์มหรือดรอปเอาต์หรือเปล่าได้
- ตั้งค่าน้ำหนักตั้งต้นแจกแจงปกติแบบเหอ ไข่หมิง ไบแอสตั้งต้นเป็น 0
- ชั้นคำนวณเชิงเส้นสร้างโดยกำหนดแค่ขนาดขาออก
- ขนาดขาเข้าของชั้นคำนวณเชิงเส้นชั้นแรกจะถูกคำนวณโดยอัตโนมัติ
ขนาดข้อมูลขาเข้าของชั้นคำนวณเชิงเส้นจะต้องสัมพันธ์กับขนาดของข้อมูลขาออกของชั้นคอนโวลูชันชั้นสุดท้าย เราสามารถเขียนให้มีการคำนวณขนาดที่ควรเป็นตรงนี้โดยอัตโนมัติเพื่อจะได้ปรับขนาดชั้นคอนโวลูชันได้โดยไม่ตรงกังวลตรงนี้
เราอาจเขียน Sequential ให้เป็นคลาสของโครงข่ายตามแบบที่อธิบายมาได้ดังนี้
import numpy as np
import matplotlib.pyplot as plt
class Prasat(torch.nn.Sequential):
def __init__(self,kwang,m_cnn,m_lin,eta=0.001,dropout=0,bn=0):
super(Prasat,self).__init__()
'''
ค่าภายใน m_cnn:
m[0]: จำนวนขาเข้า
m[1]: จำนวนขาออก
m[2]: ขนาดตัวกรอง
m[3]: stride
m[4]: pad
m[5]: ขนาด maxpool
m_lin: ขนาดขาออกของชั้นเชิงเส้นแต่ละชั้น
eta: อัตราการเรียนรู้
dropout: อัตราดรอปเอาต์ในแต่ละชั้น
bn: แทรกแบตช์นอร์มระหว่างแต่ละชั้นหรือไม่
'''
for i,m in enumerate(m_cnn,1):
kwang = np.floor((kwang-m[2]+m[4]*2.)/m[3])+1
c = torch.nn.Conv2d(m[0],m[1],m[2],m[3],m[4])
torch.nn.init.kaiming_normal_(c.weight)
c.bias.data.fill_(0)
self.add_module('c%d'%i,c)
self.add_module('relu_c%d'%i,relu)
if(bn):
self.add_module('bano_c%d'%i,torch.nn.BatchNorm2d(m[1]))
if(m[5]>1):
self.add_module('maxp_c%d'%i,torch.nn.MaxPool2d(m[5]))
kwang = np.floor(kwang/m[5])
if(dropout):
self.add_module('droa_c%d'%i,torch.nn.Dropout(dropout))
self.add_module('o',Plianrup(-1))
m_lin = [int(kwang)**2*m_cnn[-1][1]]+m_lin
nm = len(m_lin)
for i in range(1,nm):
c = torch.nn.Linear(m_lin[i-1],m_lin[i])
torch.nn.init.kaiming_normal_(c.weight)
c.bias.data.fill_(0)
self.add_module('l%d'%i,c)
if(i<nm-1):
if(bn):
self.add_module('bano_l%d'%i,torch.nn.BatchNorm1d(m_lin[i]))
if(dropout):
self.add_module('droa_l%d'%i,torch.nn.Dropout(dropout))
self.add_module('relu_l%d'%i,relu)
self.opt = torch.optim.Adam(self.parameters(),lr=eta)
def rianru(self,rup_fuek,rup_truat,n_thamsam,ro=10):
X_truat,z_truat = rup_truat
self.khanaen = []
khanaen_sungsut = 0
t_roem = time.time()
for o in range(n_thamsam):
self.train()
for Xb,zb in rup_fuek:
a = self(Xb)
J = ha_entropy(a,zb)
J.backward()
self.opt.step()
self.opt.zero_grad()
self.eval()
khanaen = self.ha_khanaen_(X_truat,z_truat)
self.khanaen.append(khanaen)
print('%d ครั้งผ่านไป ใช้เวลาไป %.1f นาที ทำนายแม่น %.4f'%(o+1,(time.time()-t_roem)/60,khanaen))
if(khanaen>khanaen_sungsut):
khanaen_sungsut = khanaen
maiphoem = 0
else:
maiphoem += 1
if(ro>0 and maiphoem>=ro):
break
def thamnai_(self,X):
return self(X).argmax(1)
def ha_khanaen_(self,X,z):
return (self.thamnai_(X)==z).numpy().mean()ในส่วนของเมธอด .rianru() นั้นข้อมูลป้อนเข้าคือข้อมูลฝึกในรูปของ DataLoader สำหรับทำมินิแบตช์ และข้อมูลตรวจสอบในรูปของเทนเซอร์ของข้อมูลทั้งหมด
ข้อมูลตรวจสอบใช้เพื่อเป็นเงื่อนไขในการหยุด ถ้าความแม่นยำในการทำนายข้อมูลตรวจสอบไม่เพิ่มหลังจากฝึกต่อไปแล้วเป็นจำนวนกี่ครั้งตามที่กำหนดก็ให้สิ้นสุดการเรียนรู้
คราวนี้ลองทดสอบกับข้อมูล FashionMNIST บ้าง ส่วนประกอบต่างๆจะเหมือนกับข้อมูล MNIST ธรรมดา แต่จะยากกว่าหน่อย
เนื่องจากเป็นข้อมูลเสื้อผ้า ดังนั้นการนำภาพมากลับซ้ายขวาจึงช่วยเพิ่มความหลากหลายในการเรียนรู้ได้ เราสามารถใช้ตัวเลือกแปลง tf.RandomHorizontalFlip() ได้ สำหรับชุดข้อมูลฝึก ส่วนชุดข้อมูลทดสอบไม่จำเป็นต้องทำก็ได้
folder_fashionmnist = '~/pytorchdata/fashionmnist/'
tran = tf.Compose([
tf.RandomHorizontalFlip(), # สุ่มกลับซ้ายขวา
tf.ToTensor(),
tf.Normalize((0.5,),(0.5,))])
rup_fuek = ds.FashionMNIST(folder_fashionmnist,transform=tran,train=1,download=True)
rup_fuek = Dalo(rup_fuek,batch_size=64,shuffle=True) # ข้อมูลฝึก ทำเป็นมินิแบตช์
tran = tf.Compose([
tf.ToTensor(),
tf.Normalize((0.5,),(0.5,))])
rup_truat = ds.FashionMNIST(folder_fashionmnist,transform=tran,train=0)
rup_truat = list(Dalo(rup_truat,100000))[0] # ข้อมูลตรวจสอบ ดึงมาทีเดียว
# โครงสร้างโครงข่ายประสาท
m_cnn = [
[1,16,5,1,0,2],
[16,16,5,1,0,2],
]
m_lin = [32,10]
prasat = Prasat(28,m_cnn,m_lin,eta=0.001,dropout=0,bn=1)
prasat.rianru(rup_fuek,rup_truat,n_thamsam=200,ro=5)
plt.plot(prasat.khanaen)
plt.show()ผลออกมาไม่ดีมากเท่าชุดข้อมูลตัวเลข แต่ก็ถึง 90% ได้เหมือนกัน
-----------------------------------------
囧囧囧囧囧囧囧囧囧囧囧囧囧囧囧囧囧囧囧囧囧囧囧囧囧
หมวดหมู่
-- คอมพิวเตอร์ >> ปัญญาประดิษฐ์ >> โครงข่ายประสาทเทียม-- คอมพิวเตอร์ >> เขียนโปรแกรม >> python >> pytorch