[python] การแยกข้อมูลตรวจสอบกับข้อมูลฝึกเพื่อป้องกันการเรียนรู้เกิน
เขียนเมื่อ 2017/09/24 09:25
แก้ไขล่าสุด 2021/09/28 16:42
ในการเรียนรู้ของเครื่องปกติเราจะใช้ข้อมูลจำนวนหนึ่งที่เตรียมไว้เพื่อใช้สำหรับการฝึก แล้วทำการเรียนรู้โดยวนซ้ำเพื่อปรับค่าน้ำหนักไปเรื่อยๆเพื่อให้ค่าที่ได้ผลลัพธ์สอดคล้องตรงกับข้อมูลชุดนั้น มีค่าความคลาดเคลื่อนน้อยที่สุด
อย่างไรก็ตามเป้าหมายที่แท้จริงของการเรียนรู้ของเครื่องนั้นไม่ใช่เพื่อให้แบบจำลองใช้ได้กับข้อมูลกลุ่มใดกลุ่มหนึ่งโดยเฉพาะ แต่ต้องการให้สามารถใช้ได้กับข้อมูลใดๆที่อาจจะถูกนำมาทำนายหลังจากนี้
ดังนั้นเราต้องมั่นใจว่าข้อมูลที่เรานำมาใช้เรียนรู้นั้นเป็นตัวแทนที่ดีของข้อมูลทั้งหมด ควรจะมีความหลากหลายมากพอที่จะครอบคลุมขอบเขตที่เป็นไปได้ของข้อมูล
หากไม่เช่นนั้นแล้วจะเกิดสิ่งที่เรียกว่า "การเรียนรู้เกิน" (过学习, overlearning) ซึ่งหมายถึงการที่แบบจำลองของเราสามารถทำนายข้อมูลฝึกได้อย่างแม่นยำ แต่พอลองทำนายข้อมูลชุดอื่นก็กลับล้มเหลว
โดยทั่วไปก็คือต้องเตรียมข้อมูลที่ใช้สำหรับเรียนรู้ให้มีความหลากหลายและจำนวนมากพอ
การป้องกับการเรียนรู้เกินมีอยู่หลายวิธี วิธีหนึ่งซึ่งจะกล่าวถึงในบทความนี้ก็คือ การนำข้อมูลที่มีส่วนหนึ่งมาใช้เป็นข้อมูลตรวจสอบเพื่อให้รู้ว่าการเรียนรู้ควรจะสิ้นสุดลงเมื่อไหร่
ขอเริ่มโดยยกตัวอย่างด้วยข้อมูล MNIST ซึ่งได้เขียนถึงไปในก่อนหน้านี้ใน https://phyblas.hinaboshi.com/20170922
ในตัวอย่างนั้นเราใช้พิจารณาแต่ความแม่นยำในการทำนายคำตอบจากตัวข้อมูลที่ใช้ในการเรียนรู้นั้นเอง

นั่นคือเราให้โปรแกรมเรียนรู้ตัวเลขท้งหมดที่อยู่ในนี้ เสร็จแล้วเราก็เอาภาพหนึ่งจากในนี้มาให้โปรแกรมทายดู แบบนั้นถ้าหากโปรแกรมตั้งใจเรียนรู้ข้อมูลชุดนั้นมาเป็นอย่างดีโอกาสถูกย่อมมาก
แต่ถ้าหากอยู่ดีๆเอาตัวเลขที่ไม่มีอยู่ในนั้นมา แล้วตัวเลขนั้นมีรูปแบบที่แปลกไปจากที่อยู่ในนั้นมาก แบบนี้โปรแกรมก็อาจทายผิดได้ง่าย
เช่น สมมุติถ้าเลข 1 ในข้อมูลที่ให้ฝึกฝนทั้งหมดเป็นแบบขีดแนวตั้งตรงทื่อๆไม่มีหัวเลย แบบนี้พอเจอเลข 1 ที่มีหัว โปรแกรมก็อาจทายผิดเป็นเลข 7 ได้
ดังนั้นคราวนี้จะเก็บข้อมูลส่วนหนึ่งไว้ ไม่ได้ใช้ในการฝึกด้วย แต่เอาไว้ใช้ตรวจสอบอย่างเดียว
บ่อยครั้งเวลาได้ข้อมูลมา แทนที่จะเอาไปใช้ในการฝึกฝนทั้งหมด อาจควรแยกส่วนหนึ่งมาไว้ใช้เป็นตัวตรวจสอบ ทำแบบนี้จะช่วยให้ได้ผลลัพธ์ที่มั่นใจมากกว่า
สมมุติว่าอยากเก็บข้อมูลสัก 20% ไว้ใช้ฝึกก็อาจทำการแบ่งโดยเขียนโค้ดได้ดังนี้
หรืออาจใช้ sklearn ช่วยก็ได้เพื่อให้ง่ายขึ้น ใน sklearn มีคำสั่งที่ช่วยในการแยกข้อมูลออกมาเป็นข้อมูลฝึกฝนและข้อมูลตรวจสอบ
คำสั่งนี้คือ train_test_split อยู่ในมอดูลย่อย model_selection
จะใช้แบบไหนผลที่ได้ก็จะเหมือนกันคือแบ่งข้อมูลออกเป็นข้อมูลฝึก 56000 และข้อมูลตรวจสอบ 14000
ถ้าอยากเปลี่ยนจำนวนก็แค่แก้ test_size
ทีนี้ลองเอามาใช้ดู โดยจะปรับปรุงโปรแกรมจากคราวที่แล้วสักหน่อย โดยแค่แก้ตัวเงื่อนไขในการหยุดจากความแม่นยำในการทายข้อมูลฝึก มาเป็นความแม่นยำในการทายข้อมูลตรวจสอบ
เมื่อลองรันดูแล้ว ดูกราฟแสดงความคืบหน้าในการเรียนรู้ที่ได้ออกมาจะเห็นได้ชัดว่ายิ่งเรียนความแม่นของชุดข้อมูลฝึกยิ่งเพิ่ม พอไปถึงจุดนึงแล้วของข้อมูลทดสอบจะเริ่มไม่มีการเพิ่ม แถมยังจะลดลงด้วย
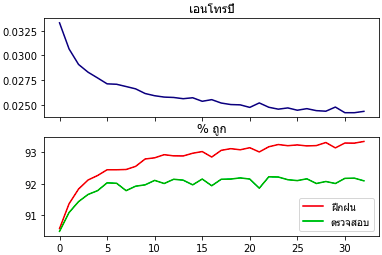
สัญญาณแบบนี้เป็นตัวแสดงว่าเริ่มจะเกิดการเรียนรู้เกินแล้ว ควรรีบหยุดการเรียนรู้โดยเร็ว หากไม่หยุดละก็ เรียนไปก็อาจมีแต่จะยิ่งแย่
หากลองแก้โปรแกรมสักหน่อยโดยลบเงื่อนไขที่ให้หยุดเร็วไปแล้วให้เรียนรู้ซ้ำๆต่อไปเรื่อยๆ ผลที่ได้ก็เป็นแบบนี้
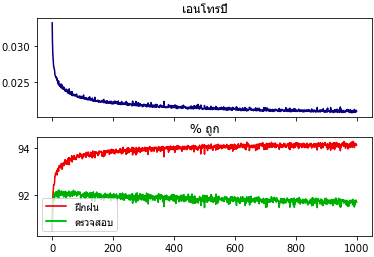
ยิ่งเรียนรู้ไปเรื่อยๆก็ยิ่งทายข้อมูลฝึกได้แม่นขึ้นทีละน้อย แต่กลับทายข้อมูลทดสอบได้น้อยลง ซึ่งเป็นผลลัพธ์ที่ไม่พึงปรารถนา
นี่เป็นตัวอย่างที่ดีที่แสดงว่าการที่โปรแกรมเรียนรู้จนเข้ากับข้อมูลฝึกแต่กลับเข้ากับข้อมูลทั่วไปไม่ได้นั้นเป็นยังไง
ดังนั้นเราจึงตรวจะใช้ความแม่นยำในการทายข้อมูลตรวจสอบเป็นตัวกำหนดเงื่อนไขในการหยุด ไม่ใช่ใช้ข้อมูลฝึกฝน
สำหรับการเรียนรู้ของเครื่องแล้ว ข้อมูลเป็นอาหารที่สำคัญ แต่ข้อมูลที่ซ้ำๆกันอาจไม่มีประโยชน์ ต้องมีความหลากหลายจึงจะเกิดการเรียนรู้อย่างถูกต้อง
บางทีข้อมูลที่เจอตอนทดสอบอาจเป็นข้อมูลในรูปแบบที่ไม่มีอยู่ในข้อมูลฝึกเลย พอเจอแบบนั้นโปรแกรมก็ทายไม่ถูกแล้ว
เช่นถ้าเจอเลข 4 ที่ลากหางยาวๆแบบนี้อาจถูกมองว่าเป็นเลข 9 ก็ได้

ชีวิตคนก็เหมือนกัน เรียนมากก็ไม่ใช่ว่าจะดีเสมอไป ถ้ายังเรียนแต่สิ่งเดิมๆอยู่ซ้ำๆไปเรื่อยๆก็ไม่ได้อะไร มีแต่จะยิ่งติดอยู่ในกรอบแคบๆ ไม่รู้ว่าโลกภายนอกเป็นยังไง
อ้างอิง
อย่างไรก็ตามเป้าหมายที่แท้จริงของการเรียนรู้ของเครื่องนั้นไม่ใช่เพื่อให้แบบจำลองใช้ได้กับข้อมูลกลุ่มใดกลุ่มหนึ่งโดยเฉพาะ แต่ต้องการให้สามารถใช้ได้กับข้อมูลใดๆที่อาจจะถูกนำมาทำนายหลังจากนี้
ดังนั้นเราต้องมั่นใจว่าข้อมูลที่เรานำมาใช้เรียนรู้นั้นเป็นตัวแทนที่ดีของข้อมูลทั้งหมด ควรจะมีความหลากหลายมากพอที่จะครอบคลุมขอบเขตที่เป็นไปได้ของข้อมูล
หากไม่เช่นนั้นแล้วจะเกิดสิ่งที่เรียกว่า "การเรียนรู้เกิน" (过学习, overlearning) ซึ่งหมายถึงการที่แบบจำลองของเราสามารถทำนายข้อมูลฝึกได้อย่างแม่นยำ แต่พอลองทำนายข้อมูลชุดอื่นก็กลับล้มเหลว
โดยทั่วไปก็คือต้องเตรียมข้อมูลที่ใช้สำหรับเรียนรู้ให้มีความหลากหลายและจำนวนมากพอ
การป้องกับการเรียนรู้เกินมีอยู่หลายวิธี วิธีหนึ่งซึ่งจะกล่าวถึงในบทความนี้ก็คือ การนำข้อมูลที่มีส่วนหนึ่งมาใช้เป็นข้อมูลตรวจสอบเพื่อให้รู้ว่าการเรียนรู้ควรจะสิ้นสุดลงเมื่อไหร่
ขอเริ่มโดยยกตัวอย่างด้วยข้อมูล MNIST ซึ่งได้เขียนถึงไปในก่อนหน้านี้ใน https://phyblas.hinaboshi.com/20170922
ในตัวอย่างนั้นเราใช้พิจารณาแต่ความแม่นยำในการทำนายคำตอบจากตัวข้อมูลที่ใช้ในการเรียนรู้นั้นเอง
นั่นคือเราให้โปรแกรมเรียนรู้ตัวเลขท้งหมดที่อยู่ในนี้ เสร็จแล้วเราก็เอาภาพหนึ่งจากในนี้มาให้โปรแกรมทายดู แบบนั้นถ้าหากโปรแกรมตั้งใจเรียนรู้ข้อมูลชุดนั้นมาเป็นอย่างดีโอกาสถูกย่อมมาก
แต่ถ้าหากอยู่ดีๆเอาตัวเลขที่ไม่มีอยู่ในนั้นมา แล้วตัวเลขนั้นมีรูปแบบที่แปลกไปจากที่อยู่ในนั้นมาก แบบนี้โปรแกรมก็อาจทายผิดได้ง่าย
เช่น สมมุติถ้าเลข 1 ในข้อมูลที่ให้ฝึกฝนทั้งหมดเป็นแบบขีดแนวตั้งตรงทื่อๆไม่มีหัวเลย แบบนี้พอเจอเลข 1 ที่มีหัว โปรแกรมก็อาจทายผิดเป็นเลข 7 ได้
ดังนั้นคราวนี้จะเก็บข้อมูลส่วนหนึ่งไว้ ไม่ได้ใช้ในการฝึกด้วย แต่เอาไว้ใช้ตรวจสอบอย่างเดียว
บ่อยครั้งเวลาได้ข้อมูลมา แทนที่จะเอาไปใช้ในการฝึกฝนทั้งหมด อาจควรแยกส่วนหนึ่งมาไว้ใช้เป็นตัวตรวจสอบ ทำแบบนี้จะช่วยให้ได้ผลลัพธ์ที่มั่นใจมากกว่า
สมมุติว่าอยากเก็บข้อมูลสัก 20% ไว้ใช้ฝึกก็อาจทำการแบ่งโดยเขียนโค้ดได้ดังนี้
from sklearn import datasets
mnist = datasets.fetch_mldata('MNIST original')
X,z = mnist.data,mnist.target
n = len(X)
sumriang = np.random.permutation(n)
nn = int(n/5)
X_fuekfon,X_truatsop = X[sumriang[nn:]],X[sumriang[:nn]]
z_fuekfon,z_truatsop = z[sumriang[nn:]],z[sumriang[:nn]]หรืออาจใช้ sklearn ช่วยก็ได้เพื่อให้ง่ายขึ้น ใน sklearn มีคำสั่งที่ช่วยในการแยกข้อมูลออกมาเป็นข้อมูลฝึกฝนและข้อมูลตรวจสอบ
คำสั่งนี้คือ train_test_split อยู่ในมอดูลย่อย model_selection
from sklearn.model_selection import train_test_split
X_fuekfon,X_truatsop,z_fuekfon,z_truatsop = train_test_split(X,z,test_size=0.2)จะใช้แบบไหนผลที่ได้ก็จะเหมือนกันคือแบ่งข้อมูลออกเป็นข้อมูลฝึก 56000 และข้อมูลตรวจสอบ 14000
ถ้าอยากเปลี่ยนจำนวนก็แค่แก้ test_size
ทีนี้ลองเอามาใช้ดู โดยจะปรับปรุงโปรแกรมจากคราวที่แล้วสักหน่อย โดยแค่แก้ตัวเงื่อนไขในการหยุดจากความแม่นยำในการทายข้อมูลฝึก มาเป็นความแม่นยำในการทายข้อมูลตรวจสอบ
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
from sklearn.model_selection import train_test_split
def softmax(x):
exp_x = np.exp(x.T-x.max(1))
return (exp_x/exp_x.sum(0)).T
class ThotthoiLogistic:
def __init__(self,eta):
self.eta = eta
def rianru(self,X,z,n_thamsam,n_batch=0,X_truat=0,z_truat=0,romaiphoem=0):
n = len(z)
if(type(X_truat)!=np.ndarray): # ถ้าไม่ได้ป้อนข้อมูลตรวจสอบมาด้วย ก็ให้ใช้ข้อมูลฝึกฝนเป็นข้อมูลตรวจสอบ
X_truat,z_truat = X,z
if(n_batch==0 or n<n_batch):
n_batch = n
self.kiklum = int(z.max()+1)
z_1h = z[:,None]==range(self.kiklum)
self.w = np.zeros([X.shape[1]+1,self.kiklum])
self.entropy = []
self.maen_fuek = []
self.maen_truat = []
disut = 0 # ค่าจำนวนที่ถูกมากสุด
maiphoem = 0 # นับว่าจำนวนที่ถูกไม่เพิ่มมาแล้วกี่ครั้ง
for j in range(n_thamsam):
lueak = np.random.permutation(n)
for i in range(0,n,n_batch):
Xn = X[lueak[i:i+n_batch]]
zn = z_1h[lueak[i:i+n_batch]]
phi = self.ha_softmax(Xn)
eee = (zn-phi)/len(zn)*self.eta
self.w[1:] += np.dot(eee.T,Xn).T
self.w[0] += eee.sum(0)
thukmai = self.thamnai(X)==z
maen_fuek = thukmai.mean()*100
thukmai = self.thamnai(X_truat)==z_truat
maen_truat = thukmai.mean()*100
if(maen_truat > disut):
# ถ้าจำนวนที่ถูกมากขึ้นกว่าเดิมก็บันทึกค่าจำนวนนั้น และน้ำหนักในตอนนั้นไว้
disut = maen_truat
maiphoem = 0
w = self.w.copy()
else:
maiphoem += 1 # ถ้าไม่ถูกมากขึ้นก็นับไว้ว่าไม่เพิ่มไปอีกครั้งแล้ว
self.maen_fuek += [maen_fuek]
self.maen_truat += [maen_truat]
self.entropy += [self.ha_entropy(X,z_1h)]
print(u'ครั้งที่ %d ถูก %.3f%% สูงสุด %.3f%% ไม่เพิ่มมาแล้ว %d ครั้ง'%(j+1,self.maen_truat[-1],disut,maiphoem))
if(romaiphoem!=0 and maiphoem>=romaiphoem):
break # ถ้าจำนวนที่ถูกไม่เพิ่มเลยจนถึงจำนวนที่กำหนดก็เลิกทำ
self.w = w # ค่าน้ำหนักที่ได้ในท้ายสุด เอาตามค่าที่ทำให้ทายถูกมากที่สุด
def thamnai(self,X):
return (np.dot(X,self.w[1:])+self.w[0]).argmax(1)
def ha_softmax(self,X):
return softmax(np.dot(X,self.w[1:])+self.w[0])
def ha_entropy(self,X,z_1h):
return -(z_1h*np.log(self.ha_softmax(X)+1e-7)).mean()
# ดึงข้อมูล MNIST
mnist = datasets.fetch_mldata('MNIST original')
X,z = mnist.data,mnist.target
X = X/255.
np.random.seed(0)
X_fuek,X_truat,z_fuek,z_truat = train_test_split(X,z,test_size=0.2)
# เริ่มการเรียนรู้
eta = 0.24 # อัตราการเรียนรู้
n_thamsam = 1000 # จำนวนทำซ้ำสูงสุดถ้าไม่มีการหยุดเสียก่อน
n_batch = 100 # จำนวนมินิแบตช์
romaiphoem = 10 # จะให้หยุดเมื่อความแม่นยำไม่เพิ่มเกินกี่ครั้ง
tl = ThotthoiLogistic(eta)
tl.rianru(X_fuek,z_fuek,n_thamsam,n_batch,X_truat,z_truat,romaiphoem)
# กราฟแสดงความคืบหน้าในการเรียนรู้
ax = plt.subplot(211)
ax.set_title(u'เอนโทรปี',fontname='Tahoma')
plt.plot(tl.entropy,'#000077')
plt.tick_params(labelbottom='off')
ax = plt.subplot(212)
ax.set_title(u'% ถูก',fontname='Tahoma')
plt.plot(tl.maen_fuek,'#dd0000')
plt.plot(tl.maen_truat,'#00aa00')
plt.legend([u'ฝึกฝน',u'ตรวจสอบ'],prop={'family':'Tahoma'})
plt.show()เมื่อลองรันดูแล้ว ดูกราฟแสดงความคืบหน้าในการเรียนรู้ที่ได้ออกมาจะเห็นได้ชัดว่ายิ่งเรียนความแม่นของชุดข้อมูลฝึกยิ่งเพิ่ม พอไปถึงจุดนึงแล้วของข้อมูลทดสอบจะเริ่มไม่มีการเพิ่ม แถมยังจะลดลงด้วย
สัญญาณแบบนี้เป็นตัวแสดงว่าเริ่มจะเกิดการเรียนรู้เกินแล้ว ควรรีบหยุดการเรียนรู้โดยเร็ว หากไม่หยุดละก็ เรียนไปก็อาจมีแต่จะยิ่งแย่
หากลองแก้โปรแกรมสักหน่อยโดยลบเงื่อนไขที่ให้หยุดเร็วไปแล้วให้เรียนรู้ซ้ำๆต่อไปเรื่อยๆ ผลที่ได้ก็เป็นแบบนี้
ยิ่งเรียนรู้ไปเรื่อยๆก็ยิ่งทายข้อมูลฝึกได้แม่นขึ้นทีละน้อย แต่กลับทายข้อมูลทดสอบได้น้อยลง ซึ่งเป็นผลลัพธ์ที่ไม่พึงปรารถนา
นี่เป็นตัวอย่างที่ดีที่แสดงว่าการที่โปรแกรมเรียนรู้จนเข้ากับข้อมูลฝึกแต่กลับเข้ากับข้อมูลทั่วไปไม่ได้นั้นเป็นยังไง
ดังนั้นเราจึงตรวจะใช้ความแม่นยำในการทายข้อมูลตรวจสอบเป็นตัวกำหนดเงื่อนไขในการหยุด ไม่ใช่ใช้ข้อมูลฝึกฝน
สำหรับการเรียนรู้ของเครื่องแล้ว ข้อมูลเป็นอาหารที่สำคัญ แต่ข้อมูลที่ซ้ำๆกันอาจไม่มีประโยชน์ ต้องมีความหลากหลายจึงจะเกิดการเรียนรู้อย่างถูกต้อง
บางทีข้อมูลที่เจอตอนทดสอบอาจเป็นข้อมูลในรูปแบบที่ไม่มีอยู่ในข้อมูลฝึกเลย พอเจอแบบนั้นโปรแกรมก็ทายไม่ถูกแล้ว
เช่นถ้าเจอเลข 4 ที่ลากหางยาวๆแบบนี้อาจถูกมองว่าเป็นเลข 9 ก็ได้
ชีวิตคนก็เหมือนกัน เรียนมากก็ไม่ใช่ว่าจะดีเสมอไป ถ้ายังเรียนแต่สิ่งเดิมๆอยู่ซ้ำๆไปเรื่อยๆก็ไม่ได้อะไร มีแต่จะยิ่งติดอยู่ในกรอบแคบๆ ไม่รู้ว่าโลกภายนอกเป็นยังไง
อ้างอิง
-----------------------------------------
囧囧囧囧囧囧囧囧囧囧囧囧囧囧囧囧囧囧囧囧囧囧囧囧囧
หมวดหมู่
-- คอมพิวเตอร์ >> ปัญญาประดิษฐ์-- คอมพิวเตอร์ >> เขียนโปรแกรม >> python >> numpy
-- คอมพิวเตอร์ >> เขียนโปรแกรม >> python >> matplotlib
-- คอมพิวเตอร์ >> เขียนโปรแกรม >> python >> sklearn