numpy & matplotlib เบื้องต้น บทที่ ๑๕: การสุ่ม
เขียนเมื่อ 2016/06/11 22:35
แก้ไขล่าสุด 2021/09/28 16:42
ภาษาไพธอนมีมอดูลชื่อ random ซึ่งเก็บรวบรวมฟังก์ชันที่เกี่ยวกับการสุ่ม อ่านรายละเอียดได้ใน https://phyblas.hinaboshi.com/20160508
แต่ว่ากรณีที่ต้องการสุ่มข้อมูลทีละจำนวนมากๆใช้ numpy ช่วยอาจจะเร็วกว่ามาก
numpy มีมอดูลย่อยชื่อ random ซึ่งมีฟังก์ชันสำหรับสุ่มข้อมูลจำนวนมากที่มีประสิทธิภาพสูง ใช้คู่กับอาเรย์ได้ดี
ในที่นี้จะขอแนะนำฟังก์ชันส่วนหนึ่งจากมอดูลย่อยนี้ที่ใช้บ่อย
การสุ่มแบบแจกแจงสม่ำเสมอ
ฟังก์ชัน np.random.rand จะสร้างอาเรย์ที่มีขนาดและมิติตามที่เรากำหนด โดยมีค่าสุ่มในช่วง 0 ถึง 1
ตัวอย่าง
ลองวาดฮิสโทแกรมแสดงการแจกแจงดู
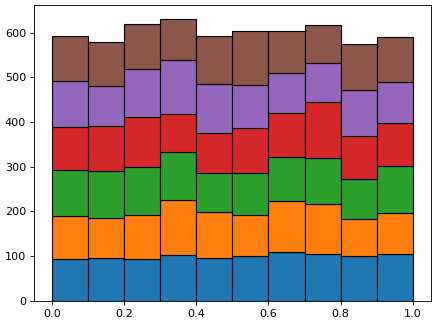
จะเห็นว่าแต่ละชุดจะมีจำนวนในแต่ละช่วงเท่าๆกันหมด โดยมีค่าเฉลี่ยที่ประมาณ จำนวนข้อมูลแต่ละชุดหารด้วยจำนวนช่องที่แบ่ง = 1000/10 = 100
np.random.rand นั้นทำการแจกแจงได้แค่ในช่วง 0 ถึง 1 เท่านั้นแต่หากต้องการให้การแจกแจงอยู่ในช่วงอื่นใดๆซึ่งเรากำหนดขึ้นเองก็อาจเลือกใช้ np.random.uniform
np.random.uniform ต้องการอาร์กิวเมนต์ ๓ ตัวคือ ค่าต่ำสุด, ค่าสูงสุด และขนาดของอาเรย์ โดยที่ขนาดของอาเรย์ต้องใส่เป็นทูเพิลหรือลิสต์คู่อันดับ จะไม่ใส่ขนาดของอาเรย์ก็ได้ หากไม่ใส่ก็จะได้ผลเป็นค่าเลขตัวเดียวไม่ใช่อาเรย์
ตัวอย่าง
การแจกแจงแบบปกติ
np.random.randn จะทำการสร้างอาเรย์ที่มีขนาดตามที่ระบุโดยมีค่าสุ่มตามการแจกแจงแบบปกติที่ มีค่าศูนย์กลาง (μ) เป็น 0 และความกว้างของการกระจาย (σ) เป็น 1
ตัวอย่าง
ลองสร้างอาเรย์ใหญ่ๆมาแล้ววาดฮิสโทแกรมแสดงการแจกแจงดู
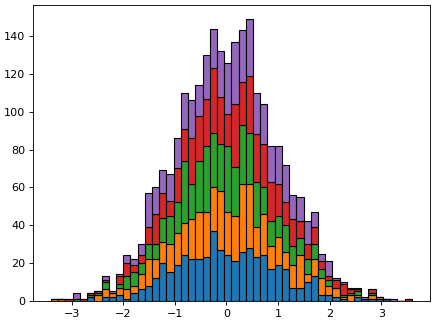
np.random.normal ก็เป็นฟังก์ชันที่สร้างการสุ่มที่มีการแจกแจงแบบปกติเช่นกัน เพียงแต่สามารถกำหนดค่า μ และ σ ได้
โดยอาร์กิวเมนต์ที่ต้องใส่ ตัวแรกคือ μ ตัวที่สองคือ σ และตัวที่สามคือขนาดของอาเรย์ที่ต้องการ ถ้าไม่ใส่ขนาดของอาเรย์จะได้เป็นค่าตัวเลขสุ่มค่าเดียวออกมา
ตัวอย่างการกระจายด้วยฮิสโทแกรม
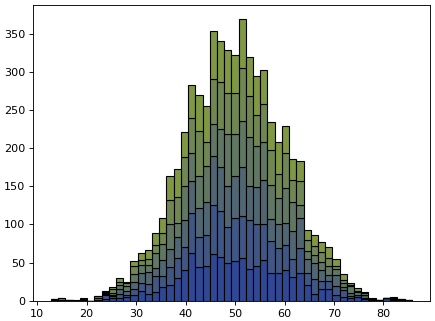
นอกจากนี้ยังมีการแจกแจงชนิดอื่นๆอีกเช่น np.random.binomical, np.random.poisson, np.random.beta, ฯลฯ
การสุ่มจำนวนเต็ม
ฟังก์ชันที่ใช้สุ่มจำนวนเต็มคือ np.random.randint
randint จะสุ่มตัวเลขจำนวนเต็มที่อยู่ในช่วงตั้งแต่อาร์กิวเมนต์ตัวแรกไปจนถึงอาร์กิวเมนต์ตัวที่สอง เพื่อนำมาสร้างอาเรย์ตามขนาดที่ระบุไว้ในอาร์กิวเมนต์ตัวที่สาม
ตัวอย่าง
** ในเวอร์ชันเก่าๆมีฟังก์ชันอีกตัวคือ np.random.random_integers แต่ปัจจุบันเลิกใช้แล้ว
การสุ่มข้อมูลจากอาเรย์
np.random.choice เป็นฟังก์ชันที่ทำการสุ่มหยิบข้อมูลออกมาจากอาเรย์หรือลิสต์เพื่อมาสร้างอาเรย์ที่มีขนาดตามที่กำหนด
อาร์กิวเมนต์ของฟังก์ชันนี้ตัวแรกคืออาเรย์ที่ต้องการให้สุ่มสมาชิก และตัวที่สองคือขนาดของอาเรย์ที่ต้องการสร้าง
ตัวอย่าง
เราสามารถกำหนดน้ำหนักความน่าจะเป็นในการสุ่มได้แต่ละค่าได้ด้วยโดยเพิ่มคีย์เวิร์ด p
ค่าของ p นั้นใช้เป็นลิสต์หรืออาเรย์ที่มีจำนวนเท่ากับจำนวนข้อมูลที่ต้องการเลือก โดยค่าทั้งหมดต้องรวมกันแล้วได้เป็น 1
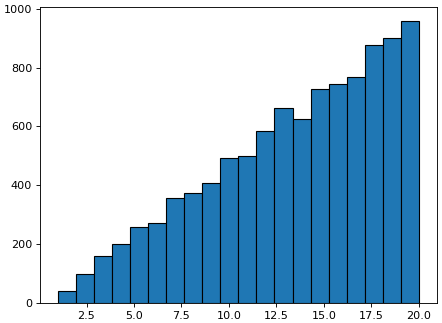
ถ้าลองสุ่มตัวเลขจำนวนเต็มตั้งแต่ 1 ถึง 20 แล้วให้น้ำหนักในการสุ่มเป็นสัดส่วนกันกับค่าของตัวเลขพอเขียนฮิสโทแกรมแล้ว ก็จะได้เป็นแท่งที่สูงขึ้นเรื่อยๆ
การสุ่มสลับข้อมูลในอาเรย์
ในการสลับจัดเรียงข้อมูลในอาเรย์ใหม่นั้นมีฟังก์ชันอยู่ ๒ ตัวคือ np.random.permutation และ np.random.shuffle
ฟังก์ชันทั้ง ๒ ตัวนี้จะทำการสลับอาเรย์ในแกนแรกสุด
ข้อแตกต่างก็คือ np.random.permutation จะแค่คืนค่าของอาเรย์ที่ถูกจัดเรียงแล้วออกมา แต่อาเรย์ตัวเดิมก็ยังอยู่
ส่วน np.random.shuffle จะเป็นการแก้ไขเขียนทับอาเรย์ตัวที่ถูกทำ
การสร้างเมล็ดในการสุ่ม
เช่นเดียวกับมอดูล random ใน np.random เองก็มีฟังก์ชันสำหรับการสร้างเมล็ดในการสุ่ม ชื่อ np.random.seed
รายละเอียดให้ไปดูในบทความที่เขียนเรื่องมอดูล random (ลิงก์อยู่ด้านบน) จะไม่ขอกล่าวซ้ำ
ตัวอย่าง
ได้
อ้างอิง
แต่ว่ากรณีที่ต้องการสุ่มข้อมูลทีละจำนวนมากๆใช้ numpy ช่วยอาจจะเร็วกว่ามาก
numpy มีมอดูลย่อยชื่อ random ซึ่งมีฟังก์ชันสำหรับสุ่มข้อมูลจำนวนมากที่มีประสิทธิภาพสูง ใช้คู่กับอาเรย์ได้ดี
ในที่นี้จะขอแนะนำฟังก์ชันส่วนหนึ่งจากมอดูลย่อยนี้ที่ใช้บ่อย
การสุ่มแบบแจกแจงสม่ำเสมอ
ฟังก์ชัน np.random.rand จะสร้างอาเรย์ที่มีขนาดและมิติตามที่เรากำหนด โดยมีค่าสุ่มในช่วง 0 ถึง 1
ตัวอย่าง
import numpy as np
print(np.random.rand(3,4))
# ได้
# [[ 0.13841332 0.05870797 0.09343369 0.66872065]
# [ 0.61801752 0.60977038 0.25617062 0.64403814]
# [ 0.83894127 0.99375777 0.06242056 0.34824402]]
print(np.random.rand(3,4))
# ได้
# [[ 0.13841332 0.05870797 0.09343369 0.66872065]
# [ 0.61801752 0.60977038 0.25617062 0.64403814]
# [ 0.83894127 0.99375777 0.06242056 0.34824402]]
ลองวาดฮิสโทแกรมแสดงการแจกแจงดู
import numpy as np
import matplotlib.pyplot as plt
x = np.random.rand(1000,6)
bara = plt.hist(x,bins=10,stacked=1,ec='k')
plt.show()
import matplotlib.pyplot as plt
x = np.random.rand(1000,6)
bara = plt.hist(x,bins=10,stacked=1,ec='k')
plt.show()
จะเห็นว่าแต่ละชุดจะมีจำนวนในแต่ละช่วงเท่าๆกันหมด โดยมีค่าเฉลี่ยที่ประมาณ จำนวนข้อมูลแต่ละชุดหารด้วยจำนวนช่องที่แบ่ง = 1000/10 = 100
np.random.rand นั้นทำการแจกแจงได้แค่ในช่วง 0 ถึง 1 เท่านั้นแต่หากต้องการให้การแจกแจงอยู่ในช่วงอื่นใดๆซึ่งเรากำหนดขึ้นเองก็อาจเลือกใช้ np.random.uniform
np.random.uniform ต้องการอาร์กิวเมนต์ ๓ ตัวคือ ค่าต่ำสุด, ค่าสูงสุด และขนาดของอาเรย์ โดยที่ขนาดของอาเรย์ต้องใส่เป็นทูเพิลหรือลิสต์คู่อันดับ จะไม่ใส่ขนาดของอาเรย์ก็ได้ หากไม่ใส่ก็จะได้ผลเป็นค่าเลขตัวเดียวไม่ใช่อาเรย์
ตัวอย่าง
print(np.random.uniform(10,12,[5,5]))
# ได้
# [[ 11.90063992 11.23890703 10.20759811 11.61095323 11.927567 ]
# [ 10.5614266 11.35633258 11.20055723 11.42188658 10.36799342]
# [ 10.82890397 10.34821344 10.02067618 11.67635054 10.74097174]
# [ 10.99379641 10.16120106 11.1839129 11.0085007 10.6263869 ]
# [ 11.68345769 11.24997368 10.64367458 11.91462817 10.63300529]]
# ได้
# [[ 11.90063992 11.23890703 10.20759811 11.61095323 11.927567 ]
# [ 10.5614266 11.35633258 11.20055723 11.42188658 10.36799342]
# [ 10.82890397 10.34821344 10.02067618 11.67635054 10.74097174]
# [ 10.99379641 10.16120106 11.1839129 11.0085007 10.6263869 ]
# [ 11.68345769 11.24997368 10.64367458 11.91462817 10.63300529]]
การแจกแจงแบบปกติ
np.random.randn จะทำการสร้างอาเรย์ที่มีขนาดตามที่ระบุโดยมีค่าสุ่มตามการแจกแจงแบบปกติที่ มีค่าศูนย์กลาง (μ) เป็น 0 และความกว้างของการกระจาย (σ) เป็น 1
ตัวอย่าง
print(np.random.randn(3,5))
# ได้
# [[-0.80200003 -0.9494691 0.99710938 3.19348425 0.93456897]
# [ 0.92803985 0.83077379 1.96311357 0.95209212 -0.832348 ]
# [ 0.39231038 0.19578248 -0.13636935 -0.47126378 0.37539167]]
# ได้
# [[-0.80200003 -0.9494691 0.99710938 3.19348425 0.93456897]
# [ 0.92803985 0.83077379 1.96311357 0.95209212 -0.832348 ]
# [ 0.39231038 0.19578248 -0.13636935 -0.47126378 0.37539167]]
ลองสร้างอาเรย์ใหญ่ๆมาแล้ววาดฮิสโทแกรมแสดงการแจกแจงดู
x = np.random.randn(500,5)
plt.hist(x,bins=50,stacked=1,ec='k')
plt.show()
plt.hist(x,bins=50,stacked=1,ec='k')
plt.show()
np.random.normal ก็เป็นฟังก์ชันที่สร้างการสุ่มที่มีการแจกแจงแบบปกติเช่นกัน เพียงแต่สามารถกำหนดค่า μ และ σ ได้
โดยอาร์กิวเมนต์ที่ต้องใส่ ตัวแรกคือ μ ตัวที่สองคือ σ และตัวที่สามคือขนาดของอาเรย์ที่ต้องการ ถ้าไม่ใส่ขนาดของอาเรย์จะได้เป็นค่าตัวเลขสุ่มค่าเดียวออกมา
ตัวอย่างการกระจายด้วยฮิสโทแกรม
x = np.random.normal(50,10,(1000,6))
c = ['#%d0%d7%d3'%(i+3,i+4,9-i) for i in range(6)]
bara = plt.hist(x,bins=50,stacked=1,color=c,ec='k')
plt.show()
c = ['#%d0%d7%d3'%(i+3,i+4,9-i) for i in range(6)]
bara = plt.hist(x,bins=50,stacked=1,color=c,ec='k')
plt.show()
นอกจากนี้ยังมีการแจกแจงชนิดอื่นๆอีกเช่น np.random.binomical, np.random.poisson, np.random.beta, ฯลฯ
การสุ่มจำนวนเต็ม
ฟังก์ชันที่ใช้สุ่มจำนวนเต็มคือ np.random.randint
randint จะสุ่มตัวเลขจำนวนเต็มที่อยู่ในช่วงตั้งแต่อาร์กิวเมนต์ตัวแรกไปจนถึงอาร์กิวเมนต์ตัวที่สอง เพื่อนำมาสร้างอาเรย์ตามขนาดที่ระบุไว้ในอาร์กิวเมนต์ตัวที่สาม
ตัวอย่าง
print(np.random.randint(2,4,20)) # ได้ [2 2 3 3 2 3 2 3 3 2 3 3 3 3 3 3 3 3 2 3]
print(np.random.randint(3,7,(3,8)))
# ได้
# [[4 4 5 6 5 6 4 3]
# [3 6 3 6 4 6 4 5]
# [5 4 6 4 4 3 3 5]]
print(np.random.randint(3,7,(3,8)))
# ได้
# [[4 4 5 6 5 6 4 3]
# [3 6 3 6 4 6 4 5]
# [5 4 6 4 4 3 3 5]]
** ในเวอร์ชันเก่าๆมีฟังก์ชันอีกตัวคือ np.random.random_integers แต่ปัจจุบันเลิกใช้แล้ว
การสุ่มข้อมูลจากอาเรย์
np.random.choice เป็นฟังก์ชันที่ทำการสุ่มหยิบข้อมูลออกมาจากอาเรย์หรือลิสต์เพื่อมาสร้างอาเรย์ที่มีขนาดตามที่กำหนด
อาร์กิวเมนต์ของฟังก์ชันนี้ตัวแรกคืออาเรย์ที่ต้องการให้สุ่มสมาชิก และตัวที่สองคือขนาดของอาเรย์ที่ต้องการสร้าง
ตัวอย่าง
a = np.array([2,2,2,2,3,5])
ar = np.random.choice(a,(2,20))
print(ar)
# ได้
# [[2 2 2 2 2 2 2 2 3 2 2 3 5 3 2 2 2 5 2 5]
# [2 5 2 2 2 2 2 2 2 3 2 3 2 2 2 2 3 2 2 5]]
ar = np.random.choice(a,(2,20))
print(ar)
# ได้
# [[2 2 2 2 2 2 2 2 3 2 2 3 5 3 2 2 2 5 2 5]
# [2 5 2 2 2 2 2 2 2 3 2 3 2 2 2 2 3 2 2 5]]
เราสามารถกำหนดน้ำหนักความน่าจะเป็นในการสุ่มได้แต่ละค่าได้ด้วยโดยเพิ่มคีย์เวิร์ด p
ค่าของ p นั้นใช้เป็นลิสต์หรืออาเรย์ที่มีจำนวนเท่ากับจำนวนข้อมูลที่ต้องการเลือก โดยค่าทั้งหมดต้องรวมกันแล้วได้เป็น 1
ถ้าลองสุ่มตัวเลขจำนวนเต็มตั้งแต่ 1 ถึง 20 แล้วให้น้ำหนักในการสุ่มเป็นสัดส่วนกันกับค่าของตัวเลขพอเขียนฮิสโทแกรมแล้ว ก็จะได้เป็นแท่งที่สูงขึ้นเรื่อยๆ
a = np.arange(1,21.)
p = a/sum(a) # น้ำหนักเป็นค่าของแต่ละตัวหารด้วยค่าผลรวม
x = np.random.choice(a,10000,p=p)
plt.hist(x,bins=20,ec='k')
plt.show()
p = a/sum(a) # น้ำหนักเป็นค่าของแต่ละตัวหารด้วยค่าผลรวม
x = np.random.choice(a,10000,p=p)
plt.hist(x,bins=20,ec='k')
plt.show()
การสุ่มสลับข้อมูลในอาเรย์
ในการสลับจัดเรียงข้อมูลในอาเรย์ใหม่นั้นมีฟังก์ชันอยู่ ๒ ตัวคือ np.random.permutation และ np.random.shuffle
ฟังก์ชันทั้ง ๒ ตัวนี้จะทำการสลับอาเรย์ในแกนแรกสุด
ข้อแตกต่างก็คือ np.random.permutation จะแค่คืนค่าของอาเรย์ที่ถูกจัดเรียงแล้วออกมา แต่อาเรย์ตัวเดิมก็ยังอยู่
ส่วน np.random.shuffle จะเป็นการแก้ไขเขียนทับอาเรย์ตัวที่ถูกทำ
a = np.arange(20).reshape(4,5)
print(a)
# ได้
# [[ 0 1 2 3 4]
# [ 5 6 7 8 9]
# [10 11 12 13 14]
# [15 16 17 18 19]]
print(np.random.permutation(a))
# ได้
# [[ 5 6 7 8 9]
# [10 11 12 13 14]
# [ 0 1 2 3 4]
# [15 16 17 18 19]]
print(a)
# ได้
# [[ 0 1 2 3 4]
# [ 5 6 7 8 9]
# [10 11 12 13 14]
# [15 16 17 18 19]]
print(np.random.shuffle(a)) # ได้ None
np.random.shuffle(a)
print(a)
# ได้
# [[10 11 12 13 14]
# [15 16 17 18 19]
# [ 0 1 2 3 4]
# [ 5 6 7 8 9]]
print(a)
# ได้
# [[ 0 1 2 3 4]
# [ 5 6 7 8 9]
# [10 11 12 13 14]
# [15 16 17 18 19]]
print(np.random.permutation(a))
# ได้
# [[ 5 6 7 8 9]
# [10 11 12 13 14]
# [ 0 1 2 3 4]
# [15 16 17 18 19]]
print(a)
# ได้
# [[ 0 1 2 3 4]
# [ 5 6 7 8 9]
# [10 11 12 13 14]
# [15 16 17 18 19]]
print(np.random.shuffle(a)) # ได้ None
np.random.shuffle(a)
print(a)
# ได้
# [[10 11 12 13 14]
# [15 16 17 18 19]
# [ 0 1 2 3 4]
# [ 5 6 7 8 9]]
การสร้างเมล็ดในการสุ่ม
เช่นเดียวกับมอดูล random ใน np.random เองก็มีฟังก์ชันสำหรับการสร้างเมล็ดในการสุ่ม ชื่อ np.random.seed
รายละเอียดให้ไปดูในบทความที่เขียนเรื่องมอดูล random (ลิงก์อยู่ด้านบน) จะไม่ขอกล่าวซ้ำ
ตัวอย่าง
for i in range(5):
np.random.seed(1)
print(np.random.randn(1,4))
np.random.seed(1)
print(np.random.randn(1,4))
ได้
[[ 1.62434536 -0.61175641 -0.52817175 -1.07296862]]
[[ 1.62434536 -0.61175641 -0.52817175 -1.07296862]]
[[ 1.62434536 -0.61175641 -0.52817175 -1.07296862]]
[[ 1.62434536 -0.61175641 -0.52817175 -1.07296862]]
[[ 1.62434536 -0.61175641 -0.52817175 -1.07296862]]
[[ 1.62434536 -0.61175641 -0.52817175 -1.07296862]]
[[ 1.62434536 -0.61175641 -0.52817175 -1.07296862]]
[[ 1.62434536 -0.61175641 -0.52817175 -1.07296862]]
[[ 1.62434536 -0.61175641 -0.52817175 -1.07296862]]
อ้างอิง
http://qiita.com/yubais/items/bf9ce0a8fefdcc0b0c97
http://openbook4.me/projects/155/sections/946
http://aidiary.hatenablog.com/entry/20140621/1403321082
http://kaisk.hatenadiary.com/entry/2014/10/30/170522
http://python.dogrow.net/?p=86
http://openbook4.me/projects/155/sections/946
http://aidiary.hatenablog.com/entry/20140621/1403321082
http://kaisk.hatenadiary.com/entry/2014/10/30/170522
http://python.dogrow.net/?p=86