ทำความรู้จักกับโครงข่ายประสาทเทียมและการเรียนรู้เชิงลึก
เขียนเมื่อ 2018/08/26 23:01
แก้ไขล่าสุด 2021/09/28 16:42
กระแสนิยมเรื่องปัญญาประดิษฐ์ในช่วงไม่กี่ปีที่ผ่านมาเกิดขึ้นมาจากการที่ ปัญญาประดิษฐ์ Alpha Go ซึ่งใช้เทคนิคการเรียนรู้ของเครื่อง สามารถเล่นหมากล้อมเอาชนะนักหมากล้อมมืออาชีพอย่างอี เซดล (이세돌) และ เคอเจี๋ย (柯洁) ทำให้ผู้คนหันมาสนใจปัญญาประดิษฐ์กันอย่างมาก
เทคนิคการเรียนรู้ของเครื่องที่ Alpha Go ใช้นั้นเรียกว่า "การเรียนรู้เชิงลึก" (深度学习, deep learning) ซึ่งสร้างขึ้นมาจาก "โครงข่ายประสาทเทียม" (人工神经网络, artificial neural network)
บทความนี้เขียนขึ้นเพื่อแนะนำเกี่ยวกับโครงข่ายประสาทเทียม และการเรียนรู้เชิงลึก โดยภาพรวม
และพร้อมกันนั้นก็เป็นบทนำสำหรับบทความสอนเขียนโครงข่ายประสาทเทียม https://phyblas.hinaboshi.com/saraban/khrong_khai_prasat_thiam
แนวคิด
โครงข่ายประสาทเทียมเป็นเทคนิคการเรียนรู้ของเครื่องชนิดหนึ่ง
สำหรับรายละเอียดเรื่องความหมายของการเรียนรู้ของเครื่องและปัญญาประดิษฐ์ได้มีเขียนถึงไปในบทความนี้ https://phyblas.hinaboshi.com/panyapradit
แนวคิดของโครงข่ายประสาทเทียมนั้นมีแบบอย่างมาจากการทำงานของสมองมนุษย์
สมองมนุษย์ประกอบด้วยเซลล์ประสาทมากมายรวมตัวกันเป็นระบบที่ซับซ้อน ระบบประสาทประกอบไปด้วยหน่วยย่อยคือเซลล์ประสาท (神经元, nerve cell) ซึ่งมักเรียกว่านิวรอน (neuron)
ภาพคร่าวๆของเซลล์ประสาทเป็นดังนี้
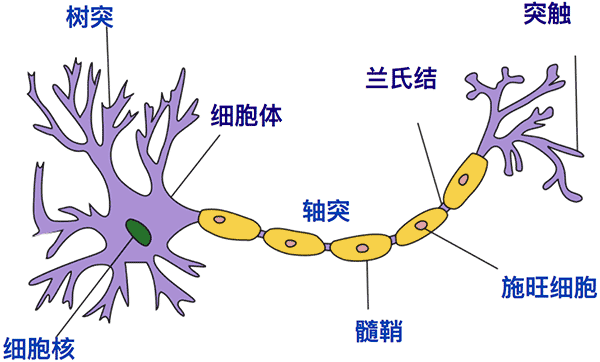
(ที่มา: วิกิพีเดีย)
ตัวเซลล์ประสาทคือสีม่วงที่มีก้อนสีเขียวอยู่ด้านใน จะเห็นว่ามีกิ่งก้านมากมาย ซึ่งส่วนนี้เป็นบริเวณที่รับสัญญาณกระแสประสาทจากเซลล์หลายเซลล์
จากนั้นตัวเซลล์จะส่งสัญญาณต่อไปยังทางขวา ซึ่งก็มีแตกกิ่งก้านไปยังเซลล์อีกหลายเซลล์ต่อไป
ส่วนประกอบต่างๆมีชื่อเรียกและรายละเอียดปลีกย่อย แต่ในที่นี้ไม่ได้จำเป็นต้องจำ เพราะไม่ใช่วิชาชีววิทยา เราแค่นำหลักการของเซลล์ประสาทมาใช้ ประเด็นสำคัญคือเข้าใจหลักการทำงาน ว่าเซลล์ประสาทเซลล์หนึ่งรับสัญญาณมาจากหลายเซลล์ แล้วทำการประมาณผลบางอย่าง แล้วส่งกระแสต่อไปยังอีกหลายเซลล์
ในโครงข่ายประสาทเทียม เซลล์ประสาทแต่ละเซลล์นั้นภายในจะเกิดการคำนวณอย่างง่ายๆขึ้น เป็นแค่หน่วยคำนวณง่ายๆ แต่เมื่อหน่วยเล็กๆนี้มารวมกันเข้าเยอะๆก็จะเกิดเป็นระบบที่สามารถคำนวณอะไรซับซ้อนได้ขึ้นมา
สมองคนเองก็ประกอบไปด้วยเซลล์ประสาทซึ่งแต่ละเซลล์ก็มีโครงสร้างง่ายๆ แต่รวมกันแล้วก็ประกอบกันเป็นสมองมนุษย์ซึ่งทำให้เราสามารถคิดอะไรซับซ้อนอย่างที่ทำอยู่นี้ได้
โครงข่ายประสาทเทียมอาจมีเซลล์ต่างๆเชื่อมต่อระโยงระยางมากมาย แต่โดยทั่วไปจะมีโครงสร้างแบ่งเป็น ๓ ชั้น
- ชั้นขาเข้า (输入层, input layer)
- ชั้นซ่อน (隐藏层, hidden layer)
- ชั้นขาออก (输出层, output layer)
โดยข้อมูลที่เราต้องการวิเคราะห์จะถูกป้อนเข้าไปยังชั้นขาเข้า แล้วผ่านต่อไปยังชั้นซ่อนซึ่งอาจมีกี่ชั้นก็ได้ การวิเคราะห์คำนวณอะไรต่างๆจะเกิดขึ้นภายในนั้น จากนั้นสุดท้ายแล้วผลลัพธ์ที่เราต้องการจะถูกส่งออกมายังชั้นขาออก
ชั้นซ่อนคือชั้นที่อยู่ตรงกลางระหว่างชั้นขาเข้าและขาออก โดยทั่วไปแล้วเราจะไม่รู้การทำงานอะไรต่างๆภายในชั้นนี้โดยละเอียด ยากที่จะคาดเดา เสมือนเป็นกล่องดำ จึงถูกเรียกว่าชั้นซ่อน
ชั้นซ่อนจะมีลักษณะอย่างไรก็ขึ้นอยู่กับชนิดของโครงข่ายประสาท มีความหลากหลายแตกต่างกันไป อาจมีความซับซ้อนมาก หรือเรียบง่าย
ชนิดของโครงข่ายประสาทเทียม
โครงข่ายประสาทที่มีโครงสร้างเรียบง่ายที่สุดก็คือโครงข่ายประสาทแบบป้อนไปข้างหน้า (前馈神经网络, feedforward neural network) คือโครงข่ายที่มีการแบ่งเป็นชั้นๆชัดเจน และข้อมูลจะถูกป้อนจากชั้นแรกแล้วไหลไปเป็นทางเดียวไปเรื่อยๆจนถึงชั้นสุดท้ายโดยไม่มีการย้อนกลับไปยังชั้นก่อนหน้า
โครงข่ายประสาทแบบป้อนไปข้างหน้าในรูปแบบที่ง่ายที่สุด เรียกว่าเพอร์เซปตรอน (感知器, perceptron)
โครงสร้างจะประกอบด้วยชั้นขาเข้าและชั้นขาออก โดยข้อมูลจากชั้นขาเข้าจะเข้าสู่เซลล์ของชั้นขาออกและเกิดการคำนวณให้ผลลัพธ์ทันทีครั้งเดียว ไม่มีการผ่านชั้นซ่อน
เมื่อนำเซลล์ประสาทหลายๆเซลล์มาต่อกันเข้าเป็นชั้นๆหลายชั้นจะเกิดเป็นโครงข่ายที่เรียกว่า เพอร์เซปตรอนหลายชั้น (多层感知器, multi-layer perceptron)
ในแต่ละชั้นอาจมีเซลล์ประสาทกี่เซลล์ก็ได้ โครงสร้างเป็นดังรูปนี้
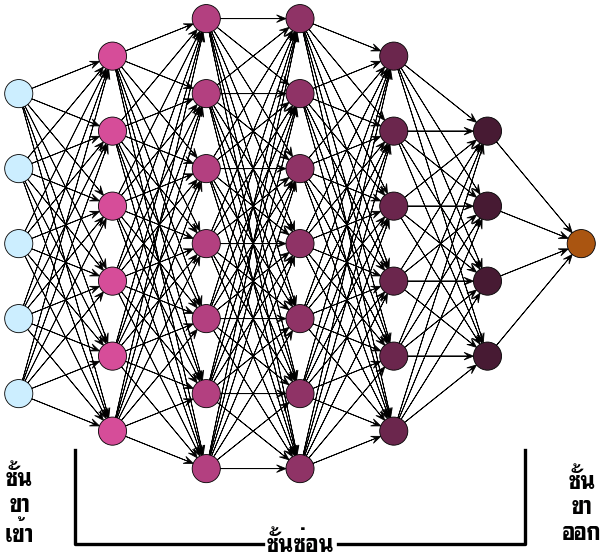
โดยปกติการนับจำนวนชั้นนั้นจะนับชั้นขาเข้ากับชั้นขาออกรวมกันเป็นชั้นเดียว ดังนั้นที่มีแค่ชั้นขาเข้าและชั้นขาออกจึงเรียกว่าเพอร์เซปตรอนชั้นเดียว
ส่วนหากมีชั้นซ่อนหนึ่งชั้นจะเรียกว่าเป็นโครงข่ายสองชั้น อย่างไรก็ตาม ก็มีบางคนนับรวมชั้นขาเข้าเป็นชันนึงและชั้นขาออกเป็นชั้นนึง แบบนั้นถ้ามีชั้นซ่อนชั้นนึงก็จะนับเป็นโครงข่าย ๓ ชั้น
ปกติถ้าพูดว่าเพอร์เซปตรอนเฉยๆจะหมายถึงเพอร์เซปตรอนที่มีเพียงชั้นเดียว แต่เพื่อเป็นการแยกให้ชัดเจน บางทีก็จะเรียกว่าเพอร์เซปตรอนชั้นเดียว (单层感知器, single-layer perceptron)
เมื่อนำหลายชั้นมาต่อกันเข้าจนลึกก็จะถูกเรียกว่าโครงข่ายประสาทเชิงลึก (深度神经网络, deep neural network)
โครงข่ายที่มีโครงสร้างลึกๆมีแนวโน้มที่จะสามารถคิดอะไรได้ซับซ้อนกว่า แต่ก็ไม่ใช่ว่าแค่เพิ่มจำนวนชั้นให้เยอะๆแล้วจะยิ่งดี มีปัจจัยต้องพิจารณามากมาย ต้องออกแบบให้ดี
เพอร์เซปตรอนหลายชั้นที่มีการคำนวณคอนโวลูชันจะเรียกว่า โครงข่ายประสาทแบบคอนโวลูชัน (卷积神经网络, convolutional neural network, CNN) นิยมใช้ในงานวิเคราะห์รูปภาพหรือข้อมูลที่มีความต่อเนื่อง
นอกจากโครงข่ายประสาทแบบป้อนไปข้างหน้าอย่างเดียวแล้ว ก็มีโครงข่ายประสาทบางชนิดที่มีการคำนวณวกกลับด้วย เรียกว่าโครงข่ายประสาทแบบวกกลับ (递归神经网络, recurrent neural network, RNN) นิยมใช้ในการวิเคราะห์ข้อมูลที่เป็นอนุกรมเวลา
รูปแบบหนึ่งของโครงข่ายประสาทแบบวกกลับที่นิยมใช้คือ โครงข่ายที่เรียกว่าหน่วยความจำระยะสั้นแบบยาว (长短期记忆, Long short-term memory, LSTM)
และยังมีโครงข่ายประสาทเทียมแบบที่ใช้อัลกอริธึมค่อนข้างต่างไปจากชนิดส่วนใหญ่ที่มีพื้นฐานมาจากเพอร์เซปตรอนมาก แต่ก็ถูกเรียกว่าโครงข่ายประสาทเทียมเหมือนกัน เช่น แผนที่โยงก่อร่างตัวเอง (自组织映射, self-organizing maps)
เนื้อหาเกี่ยวกับ SOM ได้แยกเขียนไว้ต่างหาก อ่านได้ใน https://phyblas.hinaboshi.com/20180805
นอกจากนี้ยังมีโครงข่ายประสาทเทียมอีกหลายรูปแบบ ในที่นี้ได้แนะนำไปแค่ที่นิยมใช้กันมาก
การเรียนรู้
ลักษณะสำคัญอย่างหนึ่งของโครงข่ายประสาทเทียมก็คือ ต้องมีการเรียนรู้
ทำไมปัญญาประดิษฐ์จึงสามารถทำนายข้อมูลได้อย่างถูกต้อง เช่น โปรแกรมทายภาพทำไมถึงบอกได้ว่าภาพนั้นนี้คืออะไร นั่นก็เพราะต้องมีประสบการณ์ลองผิดลองถูกมาก่อนมากมาย ไม่ใช่ว่าสามารถทายได้แม่นตั้งแต่เริ่มต้น
หรืออย่าง alpha go ทำไมจึงรู้ว่าควรจะวางหมากลงตรงไหน นั่นก็เพราะว่ามีประสบการณ์มาก่อนว่าลงตรงนี้แล้วน่าจะมีโอกาสชนะสูงจึงตัดสินใจ
ประสบการณ์ที่ว่านี้ ไม่ใช่แค่จากการจดจำอย่างเดียว แต่ยังมาจากการเชื่อมโยงข้อมูลต่างๆที่มีเข้าด้วยกันแล้วประมวลผลออกมา
นักเล่นโกะมือใหม่ หรือบอทที่ไม่เคยถูกฝึกมาก่อนเลย มาเล่นโกะทีแรกก็ทำได้แต่ลงหมากไปมั่วๆ แต่พอเล่นไปหลายๆตาก็จะเริ่มรู้แล้วว่าควรจะเล่นยังไงถึงจะดี
ภายในโครงข่ายประสาทนั้นเต็มไปด้วยตัวแปรมากมายที่มีส่วนในการคำนวณและจะปรับค่าไปเรื่อยๆเมื่อมีการเรียนรู้ ตัวแปรเหล่านั้นเรียกว่า พารามิเตอร์ (参数, parameter)
เมื่อพารามิเตอร์เปลี่ยนไป ผลการคำนวณและประมวลอะไรต่างๆภายในก็จะเปลี่ยนไป หากการเรียนรู้มีการคืบหน้าละก็ พารามิเตอร์จะปรับเปลี่ยนไปในทางที่ทำให้ผลลัพธ์ออกมาดีขึ้น
สำหรับโปรแกรมทายภาพ พอวิเคราะห์แบบนี้แล้วไปสู่คำตอบที่ผิด มันก็จะเริ่มรู้ได้ว่าวิธีคิดแบบนี้ผิด คราวหลังก็เปลี่ยนวิธีคิด หาแนวทางอื่นที่น่าจะทำให้ทายได้แม่นกว่า
อย่างกรณีของบอทเล่นโกะ เมื่อเดินตานี้ไปแล้วปรากฏว่าแพ้ มันก็จะได้เรียนรู้ว่าตานี้ไม่ควรเดินและคราวหลังก็จะเลือกตาอื่นที่น่าจะมีโอกาสชนะมากกว่า
การเรียนรู้ที่ว่าก็คือการปรับพารามิเตอร์ใหม่ ซึ่งจะทำให้ค่าที่คำนวณได้ภายในมีการเปลี่ยนแปลง เป็นผลให้ผลการตัดสินใจที่ออกมาต่างไปจากเดิม
การเรียนรู้ของโครงข่ายประสาทเทียมจะเริ่มจากการที่ตอนแรกให้สุ่มค่าพารามิเตอร์ต่างๆภายในโครงข่าย จากนั้นป้อนข้อมูลขาเข้าจำนวนหนึ่งเข้าไป แล้วให้ระบบทำการคำนวณแล้วให้ผลลัพธ์เป็นคำตอบที่ต้องการออกมา
จากนั้นนำคำตอบที่ได้มาเทียบกับคำตอบจริงว่าถูกต้องแค่ไหน ซึ่งตอนแรกมันจะคำนวณออกมาได้ไม่ดี มีข้อผิดพลาดเต็มไปหมด แต่ค่าที่ผิดพลาดนั้นจะถูกนำไปพิจารณาเพื่อปรับปรุงค่าพารามิเตอร์ภายในโครงข่ายประสาท
หลังจากนั้นก็ป้อนข้อมูลเข้าไปให้โครงข่ายทำการคำนวณใหม่อีกที แล้วก็เทียบผลลัพธ์อีกรอบ จะพบว่าคำตอบถูกต้องมากขึ้นกว่าเดิม
จากนั้นทำซ้ำแบบนี้ไปเรื่อยๆ พารามิเตอร์ก็จะยิ่งถูกปรับไปเรื่อยๆ ทำให้คำนวณและทำนายผลได้ถูกต้องมากขึ้น ในที่สุดก็จะทำนายได้ถูกเกือบหมด พอถึงจุดนี้ก็อาจจะจบการเรียนรู้ลงเท่านี้
หลังจากเรียนรู้เสร็จโครงข่ายของเราก็จะสามารถนำมาใช้คำนวณทำนายให้ได้ผลลัพธ์ตามที่ต้องการได้ สามารถนำไปใช้ทำนายผลของข้อมูลชุดอื่นๆต่อไปได้
วิธีการที่ใช้ในการปรับค่าพารามิเตอร์ในโครงข่ายประสาทเทียมโดยทั่วไปจะใช้วิธีการที่เรียกว่าการเคลื่อนลงตามความชัน (梯度下降法, gradient descent)
เนื่องจากโครงข่ายประสาทมีการจัดเรียงเชื่อมต่อโยงกันจากชั้นขาเข้าไปจนถึงชั้นขาออก เมื่อเรานำผลที่ได้จากชั้นขาออกไปเทียบกับคำตอบจริงแล้วคำนวณค่าความต่างจากผลจริงนั้นออกมา ค่าที่ได้นั้นเป็นผลจากการคำนวณต่างๆภายในโครงข่าย หากเราเริ่มพิจารณาค่าความผิดพลาดแล้วไล่ย้อนกลับไปตามลำดับสามารถจะคำนวณได้ว่าค่าพารามิเตอร์ภายในโครงข่ายควรปรับค่าไปเท่าไหร่ การคำนวณนี้เริ่มจากชั้นขาออกแล้วไล่ย้อนไปจนถึงชั้นขาเข้า ดังนั้นจึงเรียกว่า การแพร่ย้อนกลับ (反向传播, backpropagation)
ก็คือเป็นการมองจากผลไปหาเหตุ มองผลลัพธ์ว่าผิดพลาดยังไงแล้วมองย้อนไปยังต้นเหตุแล้วแก้ที่เหตุของความผิดพลาดนั้น
ประวัติศาสตร์
โครงข่ายประสาทเริ่มต้นขึ้นมาจากสิ่งเล็กๆที่ดูเรียบง่ายอย่างเพอร์เซปตรอนชั้นเดียว ซึ่งถูกคิดมาตั้งแต่ปี 1957
หลังจากนั้นช่วงทศวรรษ 1980 งานวิจัยด้านโครงข่ายประสาทเทียมก้าวหน้าขึ้นมามาก
ปี 1989 โครงข่ายประสาทเทียมแบบคอนโวลูชันในยุคแรกเริ่มเรียกว่า LeNet ได้ถูกคิดขึ้น
LeNet นั้นมีโครงสร้างทั่วไปแทยไม่ต่างจากโครงข่ายประสาทเทียมที่นิยมสร้างกันในปัจจุบัน แต่เนื่องจากคอมพิวเตอร์ตอนนั้นยังประสิทธิภาพไม่พอ และข้อมูลมีจำกัด ทำให้ LeNet ไม่ได้สร้างผลงานโดดเด่นเท่าที่ควร
ยิ่งในปี 1991 ได้มีคนชี้ปัญหาเรื่องที่ว่าความชันจะลดลงอย่างมากเมื่อสร้างโครงข่ายลึกหลายชั้น ทำให้คนรู้สึกว่าการที่จะสร้างโครงข่ายลึกๆนั้นเป็นไปได้ยาก
เวลาผ่านไป เมื่อคอมพิวเตอร์มีประสิทธิภาพขึ้น อีกทั้งข้อมูลหาได้ง่ายจากการมีอินเทอร์เน็ต โครงข่ายประสาทเทียมจึงกลับมาอีกครั้ง
ปัญหาเรื่องความชันลดลงในโครงข่ายลึกๆก็ถูกแก้ไขด้วยวิธีต่างๆ เช่นการใช้ฟังก์ชัน ReLU เป็นฟังก์ชันกระตุ้นแทนฟังก์ชันซิกมอยด์ (sigmoid) ซึ่งถูกใช้ในโครงข่ายประสาทเทียมยุคแรกเริ่ม
ในปี 2012 ได้มีโครงข่ายประสาทเทียมแบบคอนโวลูชันลึก ๘ ชั้นที่ชื่อว่า AlexNet ชนะการแข่งขัน ImageNet ซึ่งเป็นการแข่งขันจำแนกประเภทภาพซึ่งจัดขึ้นทุกปี โดยทำผลงานได้โดดเด่นกว่าทีมอื่นมาก
นั่นเป็นตัวจุดประกายสำคัญที่ทำให้การเรียนรู้เชิงลึกเป็นที่จับตามองขึ้นมา มีงานวิจัยด้านนี้เพิ่มขึ้นอย่างรวดเร็วตั้งแต่นั้นเป็นต้นมา
การแข่งขัน ImageNet ในปีถัดๆมาก็มีโครงข่ายประสาทชนิดอื่นๆถูกนำมาใช้แล้วก็ชนะการแข่งขัน
เช่นโครงข่ายประสาทเทียมแบบคอนโวลูชันลึก ๒๒ ชั้นชื่อ GoogLenet ในปี 2014
ปี 2015 มีคนคิด ResNet ซึ่งเป็นโครงข่ายที่มีความลึกถึง ๑๕๐ ชั้น โครงข่ายประสาทมีแนวโน้มที่จะมีจำนวนชั้นมากขึ้นเรื่อยๆ ลึกขึ้นเรื่อยๆ นี่เป็นแนวโน้มของการเรียนรู้เชิงลึก
โดยทั่วไปการสร้างชั้นให้ลึกมากนั้นทำให้วิเคราะห์อะไรซับซ้อนได้มากขึ้น มีโอกาสจะคิดอะไรได้ถูกต้องมากขึ้น แต่ก็ไม่ใช่ว่าแค่สร้างชั้นเยอะๆก็พอ ต้องมีการแก้ปัญหาต่างๆที่จะตามมากับความลึกนั้นด้วย จึงมีงานวิจัยต่างๆมากมายเพื่อที่จะสร้างโครงข่ายลึกๆที่มีประสิทธิภาพเพื่อใช้ทำงานต่างๆ
ปัญหาอย่างหนึ่งของการเรียนรู้เชิงลึกก็คือ ระบบการคิดภายในโครงข่ายนั้นเป็นยังไงยากที่มนุษย์จะเข้าใจได้ ยิ่งเพิ่มความลึกมากขึ้น สิ่งที่เกิดขึ้นภายในโครงข่ายยิ่งเป็นนามธรรม ยากที่จะเข้าใจว่าทำยังไงมันถึงทำนายผลออกมาให้คำตอบออกมาแบบนั้นได้ รู้แต่ว่าผลลัพธ์มันออกมาถูกต้องแม่นยำมากเท่านั้น
การเขียนโปรแกรมโครงข่ายประสาทเทียม
โครงข่ายประสาทเทียมหากเข้าใจหลักการแล้วไม่ว่าใช้ภาษาอะไรก็สามารถเขียนโปรแกรมขึ้นมาได้
แต่เนื่องจากมีความซับซ้อน ส่วนใหญ่จะนิยมใช้เฟรมเวิร์ก ซึ่งอยู่ในรูปของไลบรารี (มอดูล) ในภาษาต่างๆ
เฟรมเวิร์กที่นิยมใช้กันส่วนใหญ่อยู่ในภาษาไพธอน
- pytorch
- chainer
- tensorflow
- keras
- mxnet
- caffe
- lasagne
- paddlepaddle
- cntk
- ฯลฯ
ไม่ว่าอันไหนก็สามารถใช้งานได้และมีคนใช้งานอยู่จริง อาจต้องดูว่าถนัดแบบไหน เพราะแต่ละแบบมีวิธีการเขียนต่างกันไป หรืออาจดูว่าเพื่อนร่วมงานใช้อะไรกันมาก่อน
ทั้งหมดนี้เป็นความเข้าใจในเบื้องต้นเกี่ยวกับโครงข่ายประสาทเทียม สำหรับใครที่ต้องการเข้าใจรายละเอียดและวิธีการเขียนโปรแกรมสามารถตามอ่านต่อได้ในบทความต่อไป
>> โครงข่ายประสาทเทียมเบื้องต้น บทที่ ๑
เทคนิคการเรียนรู้ของเครื่องที่ Alpha Go ใช้นั้นเรียกว่า "การเรียนรู้เชิงลึก" (深度学习, deep learning) ซึ่งสร้างขึ้นมาจาก "โครงข่ายประสาทเทียม" (人工神经网络, artificial neural network)
บทความนี้เขียนขึ้นเพื่อแนะนำเกี่ยวกับโครงข่ายประสาทเทียม และการเรียนรู้เชิงลึก โดยภาพรวม
และพร้อมกันนั้นก็เป็นบทนำสำหรับบทความสอนเขียนโครงข่ายประสาทเทียม https://phyblas.hinaboshi.com/saraban/khrong_khai_prasat_thiam
แนวคิด
โครงข่ายประสาทเทียมเป็นเทคนิคการเรียนรู้ของเครื่องชนิดหนึ่ง
สำหรับรายละเอียดเรื่องความหมายของการเรียนรู้ของเครื่องและปัญญาประดิษฐ์ได้มีเขียนถึงไปในบทความนี้ https://phyblas.hinaboshi.com/panyapradit
แนวคิดของโครงข่ายประสาทเทียมนั้นมีแบบอย่างมาจากการทำงานของสมองมนุษย์
สมองมนุษย์ประกอบด้วยเซลล์ประสาทมากมายรวมตัวกันเป็นระบบที่ซับซ้อน ระบบประสาทประกอบไปด้วยหน่วยย่อยคือเซลล์ประสาท (神经元, nerve cell) ซึ่งมักเรียกว่านิวรอน (neuron)
ภาพคร่าวๆของเซลล์ประสาทเป็นดังนี้
(ที่มา: วิกิพีเดีย)
ตัวเซลล์ประสาทคือสีม่วงที่มีก้อนสีเขียวอยู่ด้านใน จะเห็นว่ามีกิ่งก้านมากมาย ซึ่งส่วนนี้เป็นบริเวณที่รับสัญญาณกระแสประสาทจากเซลล์หลายเซลล์
จากนั้นตัวเซลล์จะส่งสัญญาณต่อไปยังทางขวา ซึ่งก็มีแตกกิ่งก้านไปยังเซลล์อีกหลายเซลล์ต่อไป
ส่วนประกอบต่างๆมีชื่อเรียกและรายละเอียดปลีกย่อย แต่ในที่นี้ไม่ได้จำเป็นต้องจำ เพราะไม่ใช่วิชาชีววิทยา เราแค่นำหลักการของเซลล์ประสาทมาใช้ ประเด็นสำคัญคือเข้าใจหลักการทำงาน ว่าเซลล์ประสาทเซลล์หนึ่งรับสัญญาณมาจากหลายเซลล์ แล้วทำการประมาณผลบางอย่าง แล้วส่งกระแสต่อไปยังอีกหลายเซลล์
ในโครงข่ายประสาทเทียม เซลล์ประสาทแต่ละเซลล์นั้นภายในจะเกิดการคำนวณอย่างง่ายๆขึ้น เป็นแค่หน่วยคำนวณง่ายๆ แต่เมื่อหน่วยเล็กๆนี้มารวมกันเข้าเยอะๆก็จะเกิดเป็นระบบที่สามารถคำนวณอะไรซับซ้อนได้ขึ้นมา
สมองคนเองก็ประกอบไปด้วยเซลล์ประสาทซึ่งแต่ละเซลล์ก็มีโครงสร้างง่ายๆ แต่รวมกันแล้วก็ประกอบกันเป็นสมองมนุษย์ซึ่งทำให้เราสามารถคิดอะไรซับซ้อนอย่างที่ทำอยู่นี้ได้
โครงข่ายประสาทเทียมอาจมีเซลล์ต่างๆเชื่อมต่อระโยงระยางมากมาย แต่โดยทั่วไปจะมีโครงสร้างแบ่งเป็น ๓ ชั้น
- ชั้นขาเข้า (输入层, input layer)
- ชั้นซ่อน (隐藏层, hidden layer)
- ชั้นขาออก (输出层, output layer)
โดยข้อมูลที่เราต้องการวิเคราะห์จะถูกป้อนเข้าไปยังชั้นขาเข้า แล้วผ่านต่อไปยังชั้นซ่อนซึ่งอาจมีกี่ชั้นก็ได้ การวิเคราะห์คำนวณอะไรต่างๆจะเกิดขึ้นภายในนั้น จากนั้นสุดท้ายแล้วผลลัพธ์ที่เราต้องการจะถูกส่งออกมายังชั้นขาออก
ชั้นซ่อนคือชั้นที่อยู่ตรงกลางระหว่างชั้นขาเข้าและขาออก โดยทั่วไปแล้วเราจะไม่รู้การทำงานอะไรต่างๆภายในชั้นนี้โดยละเอียด ยากที่จะคาดเดา เสมือนเป็นกล่องดำ จึงถูกเรียกว่าชั้นซ่อน
ชั้นซ่อนจะมีลักษณะอย่างไรก็ขึ้นอยู่กับชนิดของโครงข่ายประสาท มีความหลากหลายแตกต่างกันไป อาจมีความซับซ้อนมาก หรือเรียบง่าย
ชนิดของโครงข่ายประสาทเทียม
โครงข่ายประสาทที่มีโครงสร้างเรียบง่ายที่สุดก็คือโครงข่ายประสาทแบบป้อนไปข้างหน้า (前馈神经网络, feedforward neural network) คือโครงข่ายที่มีการแบ่งเป็นชั้นๆชัดเจน และข้อมูลจะถูกป้อนจากชั้นแรกแล้วไหลไปเป็นทางเดียวไปเรื่อยๆจนถึงชั้นสุดท้ายโดยไม่มีการย้อนกลับไปยังชั้นก่อนหน้า
โครงข่ายประสาทแบบป้อนไปข้างหน้าในรูปแบบที่ง่ายที่สุด เรียกว่าเพอร์เซปตรอน (感知器, perceptron)
โครงสร้างจะประกอบด้วยชั้นขาเข้าและชั้นขาออก โดยข้อมูลจากชั้นขาเข้าจะเข้าสู่เซลล์ของชั้นขาออกและเกิดการคำนวณให้ผลลัพธ์ทันทีครั้งเดียว ไม่มีการผ่านชั้นซ่อน
เมื่อนำเซลล์ประสาทหลายๆเซลล์มาต่อกันเข้าเป็นชั้นๆหลายชั้นจะเกิดเป็นโครงข่ายที่เรียกว่า เพอร์เซปตรอนหลายชั้น (多层感知器, multi-layer perceptron)
ในแต่ละชั้นอาจมีเซลล์ประสาทกี่เซลล์ก็ได้ โครงสร้างเป็นดังรูปนี้
โดยปกติการนับจำนวนชั้นนั้นจะนับชั้นขาเข้ากับชั้นขาออกรวมกันเป็นชั้นเดียว ดังนั้นที่มีแค่ชั้นขาเข้าและชั้นขาออกจึงเรียกว่าเพอร์เซปตรอนชั้นเดียว
ส่วนหากมีชั้นซ่อนหนึ่งชั้นจะเรียกว่าเป็นโครงข่ายสองชั้น อย่างไรก็ตาม ก็มีบางคนนับรวมชั้นขาเข้าเป็นชันนึงและชั้นขาออกเป็นชั้นนึง แบบนั้นถ้ามีชั้นซ่อนชั้นนึงก็จะนับเป็นโครงข่าย ๓ ชั้น
ปกติถ้าพูดว่าเพอร์เซปตรอนเฉยๆจะหมายถึงเพอร์เซปตรอนที่มีเพียงชั้นเดียว แต่เพื่อเป็นการแยกให้ชัดเจน บางทีก็จะเรียกว่าเพอร์เซปตรอนชั้นเดียว (单层感知器, single-layer perceptron)
เมื่อนำหลายชั้นมาต่อกันเข้าจนลึกก็จะถูกเรียกว่าโครงข่ายประสาทเชิงลึก (深度神经网络, deep neural network)
โครงข่ายที่มีโครงสร้างลึกๆมีแนวโน้มที่จะสามารถคิดอะไรได้ซับซ้อนกว่า แต่ก็ไม่ใช่ว่าแค่เพิ่มจำนวนชั้นให้เยอะๆแล้วจะยิ่งดี มีปัจจัยต้องพิจารณามากมาย ต้องออกแบบให้ดี
เพอร์เซปตรอนหลายชั้นที่มีการคำนวณคอนโวลูชันจะเรียกว่า โครงข่ายประสาทแบบคอนโวลูชัน (卷积神经网络, convolutional neural network, CNN) นิยมใช้ในงานวิเคราะห์รูปภาพหรือข้อมูลที่มีความต่อเนื่อง
นอกจากโครงข่ายประสาทแบบป้อนไปข้างหน้าอย่างเดียวแล้ว ก็มีโครงข่ายประสาทบางชนิดที่มีการคำนวณวกกลับด้วย เรียกว่าโครงข่ายประสาทแบบวกกลับ (递归神经网络, recurrent neural network, RNN) นิยมใช้ในการวิเคราะห์ข้อมูลที่เป็นอนุกรมเวลา
รูปแบบหนึ่งของโครงข่ายประสาทแบบวกกลับที่นิยมใช้คือ โครงข่ายที่เรียกว่าหน่วยความจำระยะสั้นแบบยาว (长短期记忆, Long short-term memory, LSTM)
และยังมีโครงข่ายประสาทเทียมแบบที่ใช้อัลกอริธึมค่อนข้างต่างไปจากชนิดส่วนใหญ่ที่มีพื้นฐานมาจากเพอร์เซปตรอนมาก แต่ก็ถูกเรียกว่าโครงข่ายประสาทเทียมเหมือนกัน เช่น แผนที่โยงก่อร่างตัวเอง (自组织映射, self-organizing maps)
เนื้อหาเกี่ยวกับ SOM ได้แยกเขียนไว้ต่างหาก อ่านได้ใน https://phyblas.hinaboshi.com/20180805
นอกจากนี้ยังมีโครงข่ายประสาทเทียมอีกหลายรูปแบบ ในที่นี้ได้แนะนำไปแค่ที่นิยมใช้กันมาก
การเรียนรู้
ลักษณะสำคัญอย่างหนึ่งของโครงข่ายประสาทเทียมก็คือ ต้องมีการเรียนรู้
ทำไมปัญญาประดิษฐ์จึงสามารถทำนายข้อมูลได้อย่างถูกต้อง เช่น โปรแกรมทายภาพทำไมถึงบอกได้ว่าภาพนั้นนี้คืออะไร นั่นก็เพราะต้องมีประสบการณ์ลองผิดลองถูกมาก่อนมากมาย ไม่ใช่ว่าสามารถทายได้แม่นตั้งแต่เริ่มต้น
หรืออย่าง alpha go ทำไมจึงรู้ว่าควรจะวางหมากลงตรงไหน นั่นก็เพราะว่ามีประสบการณ์มาก่อนว่าลงตรงนี้แล้วน่าจะมีโอกาสชนะสูงจึงตัดสินใจ
ประสบการณ์ที่ว่านี้ ไม่ใช่แค่จากการจดจำอย่างเดียว แต่ยังมาจากการเชื่อมโยงข้อมูลต่างๆที่มีเข้าด้วยกันแล้วประมวลผลออกมา
นักเล่นโกะมือใหม่ หรือบอทที่ไม่เคยถูกฝึกมาก่อนเลย มาเล่นโกะทีแรกก็ทำได้แต่ลงหมากไปมั่วๆ แต่พอเล่นไปหลายๆตาก็จะเริ่มรู้แล้วว่าควรจะเล่นยังไงถึงจะดี
ภายในโครงข่ายประสาทนั้นเต็มไปด้วยตัวแปรมากมายที่มีส่วนในการคำนวณและจะปรับค่าไปเรื่อยๆเมื่อมีการเรียนรู้ ตัวแปรเหล่านั้นเรียกว่า พารามิเตอร์ (参数, parameter)
เมื่อพารามิเตอร์เปลี่ยนไป ผลการคำนวณและประมวลอะไรต่างๆภายในก็จะเปลี่ยนไป หากการเรียนรู้มีการคืบหน้าละก็ พารามิเตอร์จะปรับเปลี่ยนไปในทางที่ทำให้ผลลัพธ์ออกมาดีขึ้น
สำหรับโปรแกรมทายภาพ พอวิเคราะห์แบบนี้แล้วไปสู่คำตอบที่ผิด มันก็จะเริ่มรู้ได้ว่าวิธีคิดแบบนี้ผิด คราวหลังก็เปลี่ยนวิธีคิด หาแนวทางอื่นที่น่าจะทำให้ทายได้แม่นกว่า
อย่างกรณีของบอทเล่นโกะ เมื่อเดินตานี้ไปแล้วปรากฏว่าแพ้ มันก็จะได้เรียนรู้ว่าตานี้ไม่ควรเดินและคราวหลังก็จะเลือกตาอื่นที่น่าจะมีโอกาสชนะมากกว่า
การเรียนรู้ที่ว่าก็คือการปรับพารามิเตอร์ใหม่ ซึ่งจะทำให้ค่าที่คำนวณได้ภายในมีการเปลี่ยนแปลง เป็นผลให้ผลการตัดสินใจที่ออกมาต่างไปจากเดิม
การเรียนรู้ของโครงข่ายประสาทเทียมจะเริ่มจากการที่ตอนแรกให้สุ่มค่าพารามิเตอร์ต่างๆภายในโครงข่าย จากนั้นป้อนข้อมูลขาเข้าจำนวนหนึ่งเข้าไป แล้วให้ระบบทำการคำนวณแล้วให้ผลลัพธ์เป็นคำตอบที่ต้องการออกมา
จากนั้นนำคำตอบที่ได้มาเทียบกับคำตอบจริงว่าถูกต้องแค่ไหน ซึ่งตอนแรกมันจะคำนวณออกมาได้ไม่ดี มีข้อผิดพลาดเต็มไปหมด แต่ค่าที่ผิดพลาดนั้นจะถูกนำไปพิจารณาเพื่อปรับปรุงค่าพารามิเตอร์ภายในโครงข่ายประสาท
หลังจากนั้นก็ป้อนข้อมูลเข้าไปให้โครงข่ายทำการคำนวณใหม่อีกที แล้วก็เทียบผลลัพธ์อีกรอบ จะพบว่าคำตอบถูกต้องมากขึ้นกว่าเดิม
จากนั้นทำซ้ำแบบนี้ไปเรื่อยๆ พารามิเตอร์ก็จะยิ่งถูกปรับไปเรื่อยๆ ทำให้คำนวณและทำนายผลได้ถูกต้องมากขึ้น ในที่สุดก็จะทำนายได้ถูกเกือบหมด พอถึงจุดนี้ก็อาจจะจบการเรียนรู้ลงเท่านี้
หลังจากเรียนรู้เสร็จโครงข่ายของเราก็จะสามารถนำมาใช้คำนวณทำนายให้ได้ผลลัพธ์ตามที่ต้องการได้ สามารถนำไปใช้ทำนายผลของข้อมูลชุดอื่นๆต่อไปได้
วิธีการที่ใช้ในการปรับค่าพารามิเตอร์ในโครงข่ายประสาทเทียมโดยทั่วไปจะใช้วิธีการที่เรียกว่าการเคลื่อนลงตามความชัน (梯度下降法, gradient descent)
เนื่องจากโครงข่ายประสาทมีการจัดเรียงเชื่อมต่อโยงกันจากชั้นขาเข้าไปจนถึงชั้นขาออก เมื่อเรานำผลที่ได้จากชั้นขาออกไปเทียบกับคำตอบจริงแล้วคำนวณค่าความต่างจากผลจริงนั้นออกมา ค่าที่ได้นั้นเป็นผลจากการคำนวณต่างๆภายในโครงข่าย หากเราเริ่มพิจารณาค่าความผิดพลาดแล้วไล่ย้อนกลับไปตามลำดับสามารถจะคำนวณได้ว่าค่าพารามิเตอร์ภายในโครงข่ายควรปรับค่าไปเท่าไหร่ การคำนวณนี้เริ่มจากชั้นขาออกแล้วไล่ย้อนไปจนถึงชั้นขาเข้า ดังนั้นจึงเรียกว่า การแพร่ย้อนกลับ (反向传播, backpropagation)
ก็คือเป็นการมองจากผลไปหาเหตุ มองผลลัพธ์ว่าผิดพลาดยังไงแล้วมองย้อนไปยังต้นเหตุแล้วแก้ที่เหตุของความผิดพลาดนั้น
ประวัติศาสตร์
โครงข่ายประสาทเริ่มต้นขึ้นมาจากสิ่งเล็กๆที่ดูเรียบง่ายอย่างเพอร์เซปตรอนชั้นเดียว ซึ่งถูกคิดมาตั้งแต่ปี 1957
หลังจากนั้นช่วงทศวรรษ 1980 งานวิจัยด้านโครงข่ายประสาทเทียมก้าวหน้าขึ้นมามาก
ปี 1989 โครงข่ายประสาทเทียมแบบคอนโวลูชันในยุคแรกเริ่มเรียกว่า LeNet ได้ถูกคิดขึ้น
LeNet นั้นมีโครงสร้างทั่วไปแทยไม่ต่างจากโครงข่ายประสาทเทียมที่นิยมสร้างกันในปัจจุบัน แต่เนื่องจากคอมพิวเตอร์ตอนนั้นยังประสิทธิภาพไม่พอ และข้อมูลมีจำกัด ทำให้ LeNet ไม่ได้สร้างผลงานโดดเด่นเท่าที่ควร
ยิ่งในปี 1991 ได้มีคนชี้ปัญหาเรื่องที่ว่าความชันจะลดลงอย่างมากเมื่อสร้างโครงข่ายลึกหลายชั้น ทำให้คนรู้สึกว่าการที่จะสร้างโครงข่ายลึกๆนั้นเป็นไปได้ยาก
เวลาผ่านไป เมื่อคอมพิวเตอร์มีประสิทธิภาพขึ้น อีกทั้งข้อมูลหาได้ง่ายจากการมีอินเทอร์เน็ต โครงข่ายประสาทเทียมจึงกลับมาอีกครั้ง
ปัญหาเรื่องความชันลดลงในโครงข่ายลึกๆก็ถูกแก้ไขด้วยวิธีต่างๆ เช่นการใช้ฟังก์ชัน ReLU เป็นฟังก์ชันกระตุ้นแทนฟังก์ชันซิกมอยด์ (sigmoid) ซึ่งถูกใช้ในโครงข่ายประสาทเทียมยุคแรกเริ่ม
ในปี 2012 ได้มีโครงข่ายประสาทเทียมแบบคอนโวลูชันลึก ๘ ชั้นที่ชื่อว่า AlexNet ชนะการแข่งขัน ImageNet ซึ่งเป็นการแข่งขันจำแนกประเภทภาพซึ่งจัดขึ้นทุกปี โดยทำผลงานได้โดดเด่นกว่าทีมอื่นมาก
นั่นเป็นตัวจุดประกายสำคัญที่ทำให้การเรียนรู้เชิงลึกเป็นที่จับตามองขึ้นมา มีงานวิจัยด้านนี้เพิ่มขึ้นอย่างรวดเร็วตั้งแต่นั้นเป็นต้นมา
การแข่งขัน ImageNet ในปีถัดๆมาก็มีโครงข่ายประสาทชนิดอื่นๆถูกนำมาใช้แล้วก็ชนะการแข่งขัน
เช่นโครงข่ายประสาทเทียมแบบคอนโวลูชันลึก ๒๒ ชั้นชื่อ GoogLenet ในปี 2014
ปี 2015 มีคนคิด ResNet ซึ่งเป็นโครงข่ายที่มีความลึกถึง ๑๕๐ ชั้น โครงข่ายประสาทมีแนวโน้มที่จะมีจำนวนชั้นมากขึ้นเรื่อยๆ ลึกขึ้นเรื่อยๆ นี่เป็นแนวโน้มของการเรียนรู้เชิงลึก
โดยทั่วไปการสร้างชั้นให้ลึกมากนั้นทำให้วิเคราะห์อะไรซับซ้อนได้มากขึ้น มีโอกาสจะคิดอะไรได้ถูกต้องมากขึ้น แต่ก็ไม่ใช่ว่าแค่สร้างชั้นเยอะๆก็พอ ต้องมีการแก้ปัญหาต่างๆที่จะตามมากับความลึกนั้นด้วย จึงมีงานวิจัยต่างๆมากมายเพื่อที่จะสร้างโครงข่ายลึกๆที่มีประสิทธิภาพเพื่อใช้ทำงานต่างๆ
ปัญหาอย่างหนึ่งของการเรียนรู้เชิงลึกก็คือ ระบบการคิดภายในโครงข่ายนั้นเป็นยังไงยากที่มนุษย์จะเข้าใจได้ ยิ่งเพิ่มความลึกมากขึ้น สิ่งที่เกิดขึ้นภายในโครงข่ายยิ่งเป็นนามธรรม ยากที่จะเข้าใจว่าทำยังไงมันถึงทำนายผลออกมาให้คำตอบออกมาแบบนั้นได้ รู้แต่ว่าผลลัพธ์มันออกมาถูกต้องแม่นยำมากเท่านั้น
การเขียนโปรแกรมโครงข่ายประสาทเทียม
โครงข่ายประสาทเทียมหากเข้าใจหลักการแล้วไม่ว่าใช้ภาษาอะไรก็สามารถเขียนโปรแกรมขึ้นมาได้
แต่เนื่องจากมีความซับซ้อน ส่วนใหญ่จะนิยมใช้เฟรมเวิร์ก ซึ่งอยู่ในรูปของไลบรารี (มอดูล) ในภาษาต่างๆ
เฟรมเวิร์กที่นิยมใช้กันส่วนใหญ่อยู่ในภาษาไพธอน
- pytorch
- chainer
- tensorflow
- keras
- mxnet
- caffe
- lasagne
- paddlepaddle
- cntk
- ฯลฯ
ไม่ว่าอันไหนก็สามารถใช้งานได้และมีคนใช้งานอยู่จริง อาจต้องดูว่าถนัดแบบไหน เพราะแต่ละแบบมีวิธีการเขียนต่างกันไป หรืออาจดูว่าเพื่อนร่วมงานใช้อะไรกันมาก่อน
ทั้งหมดนี้เป็นความเข้าใจในเบื้องต้นเกี่ยวกับโครงข่ายประสาทเทียม สำหรับใครที่ต้องการเข้าใจรายละเอียดและวิธีการเขียนโปรแกรมสามารถตามอ่านต่อได้ในบทความต่อไป
>> โครงข่ายประสาทเทียมเบื้องต้น บทที่ ๑