[python] การใช้ aiohttp เพื่อล้วงข้อมูลจากเว็บด้วยการถ่ายโอนแบบไม่ประสานเวลา
เขียนเมื่อ 2020/03/18 16:09
แก้ไขล่าสุด 2024/02/22 09:44

เมื่อต้องการดึงข้อมูลจากเว็บด้วยไพธอน ปกติแล้วนิยมใช้มอดูล requests หรืออาจใช้มอดูลที่มีอยู่ในตัวแต่แรกเช่น urllib วิธีการใช้ได้เขียนแนะนำไปใน https://phyblas.hinaboshi.com/20180320
แต่หากต้องการความรวดเร็ว สามารถใช้วิธีการอะซิงโครนัสไอโอ (asynchronous IO) คือ "การถ่ายโอนแบบไม่ประสานเวลา"
aiohttp เป็นมอดูลที่สร้างขึ้นเพื่อทำการล้วงข้อมูลจากเว็บด้วยวิธีนี้ ในบทความนี้จะเขียนถึงวิธีใช้ในเบื้องต้น
การติดตั้งมอดูล
เนื่องจาก aiohttp ไม่ใช่มอดูลที่มีอยู่แล้ว จึงต้องติดตั้งเพิ่มเอง ซึ่งก็ทำได้ง่ายโดยใช้ pip
pip install aiohttp
นอกจากนี้อาจมีส่วนที่อาจติดตั้งเพิ่มเติมเพื่อเสริมอีก รายละเอียดอื่นๆอาจดูในเว็บหลักของ aiohttp
การสร้างเซสชันเพื่อใช้งานเบื้องต้น
ก่อนจะใช้มอดูล aiohttp ควรจะเข้าใจเกี่ยวกับเรื่องการใช้มอดูล asyncio และรูปไวยากรณ์ async await สำหรับทำการถ่ายโอนแบบไม่ประสานเวลา
เกี่ยวกับเรื่องนี้ได้อธิบายไปใน https://phyblas.hinaboshi.com/20200315
ที่สำคัญคือควรเข้าใจความหมายของ async await รู้ว่าเมื่อไหร่ควรใช้ async หรือ await ไม่เช่นนั้นอาจไม่สามารถเข้าใจหลักการทำงานของ aiohttp ได้อย่างเต็มที่
การใช้งานมอดูล aiohttp นั้นมีความคล้ายเคียงกับมอดูล requests แต่ก็ต่างกันไปพอสมควร
เริ่มแรกในการใช้งาน aiohttp เพื่อทำการเชื่อมต่อกับเว็บจะต้องสร้างสิ่งที่เรียกว่า "เซสชัน" (session) ขึ้นมา คำว่า "เซสชัน" ปกติหมายถึง "วาระการประชุม" แต่ในที่นี้สำหรับเรื่องเว็บไซต์จะหมายถึงขอบเขตช่วงเวลาที่ทำการเชื่อมต่อ
โดยใน aiohttp จะสร้างเซสชันขึ้นมาโดยใช้ async คู่กับ with กลายเป็น async with
เพื่อความเข้าใจ ขอยกตัวอย่างการใช้งานเบื้องต้นอย่างง่าย คือสร้างเซสชัน แล้วเปิดหน้าเว็บขึ้นมาธรรมดา
import aiohttp,asyncio
async def aioioio():
async with aiohttp.ClientSession() as ses:
url = 'https://ja.wikipedia.org/wiki/Python'
r = await ses.get(url)
print('==type==\n',type(r))
print('\n==url==\n',r.url)
print('\n==status==\n',r.status)
print('\n==charset==\n',r.charset)
print('\n==cookies==\n',r.cookies)
print('\n==version==\n',r.version)
print('\n==content_type==\n',r.content_type)
print('\n==request_info==\n',r.request_info)
print('\n==reason==\n',r.reason)
print('\n==method==\n',r.method)
r.close()
asyncio.run(aioioio())ได้
==type==
<class 'aiohttp.client_reqrep.ClientResponse'>
==url==
https://ja.wikipedia.org/wiki/Python
==status==
200
==charset==
UTF-8
==cookies==
Set-Cookie: GeoIP=TW:HSQ:Hsinchu:24.81:120.97:v4; Domain=wikipedia.org; Path=/; Secure
Set-Cookie: WMF-Last-Access=17-Mar-2020; Domain=ja.wikipedia.org; expires=Sat, 18 Apr 2020 12:00:00 GMT; HttpOnly; Path=/; Secure
Set-Cookie: WMF-Last-Access-Global=17-Mar-2020; Domain=wikipedia.org; expires=Sat, 18 Apr 2020 12:00:00 GMT; HttpOnly; Path=/; Secure
==version==
HttpVersion(major=1, minor=1)
==content_type==
text/html
==request_info==
RequestInfo(url=URL('https://ja.wikipedia.org/wiki/Python'), method='GET', headers=<CIMultiDictProxy('Host': 'ja.wikipedia.org', 'Accept': '*/*', 'Accept-Encoding': 'gzip, deflate', 'User-Agent': 'Python/3.7 aiohttp/3.6.2')>, real_url=URL('https://ja.wikipedia.org/wiki/Python'))
==reason==
OK
==method==
GETในโปรแกรมหนึ่งๆถ้าไม่ได้ใหญ่มากแนะนำให้ใช้แค่เซสชันเดียวตลอดโปรแกรม จะเชื่อมต่อกี่เว็บก็ทำได้พร้อมกันในเซสชันเดียวกัน ไม่ต้องสร้างเซสชันหลายอันโดยไม่จำเป็น
async with จะสร้างได้ภายในฟังก์ชันโครูทีน (ฟังก์ชันที่สร้างขึ้นด้วย async def) เท่านั้น ดังนั้นในที่นี้จึงสร้างฟังก์ชันโครูทีน คือ aioioio จากนั้นก็สั่งรันด้วย asyncio.run
aiohttp.ClientSession() จะทำการสร้างออบเจ็กต์เซสชันขึ้นมา ในที่นี้ไปเก็บอยู่ในตัวแปร ses ภายในกรอบตรงนั้นให้ใช้ออบเจ็กต์นี้เป็นตัวกลางในการทำการเชื่อมต่อกับเว็บ
ที่ใช้ในครั้งนี้คือเมธอด .get() คือใช้สำหรับเชื่อมต่อแบบ get คือแบบธรรมดา (นอกจากนี้ก็มีพวก post, patch, delete, ฯลฯ)
จะเห็นว่าต้องใช้ await ด้วย เพราะ .get() เป็นฟังก์ชันโครูทีน
ออบเจ็กต์ที่ได้จากการเชื่อมต่อมาเก็บไว้ในตัวแปร r ลองดูชนิดของข้อมูลจะเห็นว่าเป็นคลาส aiohttp.client_reqrep.ClientResponse คือเป็นออบเจ็กต์ที่เก็บผลการเชื่อมต่อเข้ากับเว็บเอาไว้
ในออบเจ็กต์นี้มีแอตทริบิวต์และเมธอดต่างๆมากมาย ในที่นี้ได้ลองให้แสดงส่วนหนึ่ง คือ
- .url คือ เว็บที่เราเข้า
- .status คือ สถานะการเชื่อมต่อ ถ้าต่อสำเร็จจะได้ 200
- .charset คือ ชุดรหัสอักษรที่ใช้ ปกติเว็บสมัยนี้มักจะใช้ยูนิโค้ด UTF-8 กันหมดแล้ว แต่ก็อาจมีบางเว็บใช้อย่างอื่น บางทีก็มีผลต่อการอ่านข้อมูลในเว็บ
- ฯลฯ
และตอนท้ายสุดควรจะใช้เมธอด .close() เพื่อปิดออบเจ็กต์ตัวนี้ด้วย แต่จะไม่ปิดก็ไม่เป็นอะไร แค่บางทีอาจมีเตือนขึ้นมาว่าไม่มีการปิด
หรือจะใช้โครงสร้าง with เพื่อจะได้เปิดมาแล้วปิดให้อัตโนมัติ คล้ายกับเวลาใช้คำสั่ง open เพื่ออ่านไฟล์ก็ได้ (รายละเอียด https://phyblas.hinaboshi.com/tsuchinoko17) เพียงแต่ว่า .get() ก็เป็นฟังก์ชันโครูทีน ก็ต้องเขียนเป็น async with ไม่ใช่ with เฉยๆ
เช่นเขียนแบบนี้
async def aioioio():
async with aiohttp.ClientSession() as ses:
url = 'https://ja.wikipedia.org/wiki/async'
async with ses.get(url) as r:
print('url: ',r.url)
print('status: ',r.status)
print('charset: ',r.charset)
asyncio.run(aioioio())ได้
url: https://ja.wikipedia.org/wiki/Async
status: 200
charset: UTF-8เพียงแต่แบบทำให้ยิ่งมี async ซ้อนกัน ดูซับซ้อนไปหน่อย ตัวอย่างต่อจากนี้ไปนี้จะไม่ใช้วิธีนี้ และจะไม่ใส่ .close() ด้วย แต่หากใครถนัดจะใช้ with ก็สามารถเปลี่ยนโค้ดเอาได้
ต่อไปมาลองดูข้อมูลเฮดเดอร์ สำหรับข้อมูลเฮดเดอร์นั้นจะอยู่ในแอตทริบิวต์ .headers ในรูปของดิกชันนารี สามารถนำมาใช้ดูข้อมูลได้ง่าย ตัวอย่างเช่น
async def aioioio():
async with aiohttp.ClientSession() as ses:
url = 'https://th.wikipedia.org/wiki/สาธารณรัฐจีน'
r = await ses.get(url)
for h in r.headers:
print(h+': '+r.headers[h])
asyncio.run(aioioio())ได้
Date: Tue, 17 Mar 2020 14:04:22 GMT
Content-Type: text/html; charset=UTF-8
Server: mw1405.eqiad.wmnet
X-Powered-By: PHP/7.2.26-1+0~20191218.33+debian9~1.gbpb5a340+wmf1
X-Content-Type-Options: nosniff
P3P: CP="See https://th.wikipedia.org/wiki/Special:CentralAutoLogin/P3P for more info."
Content-Language: th
Vary: Accept-Encoding,Cookie,Authorization
Last-Modified: Sun, 08 Mar 2020 15:33:33 GMT
Backend-Timing: D=155554 t=1584453862004328
X-ATS-Timestamp: 1584453862
Content-Encoding: gzip
X-Varnish: 234496320
Age: 2
X-Cache: cp5012 miss, cp5007 miss
X-Cache-Status: miss
Server-Timing: cache;desc="miss"
Strict-Transport-Security: max-age=106384710; includeSubDomains; preload
Set-Cookie: WMF-Last-Access=17-Mar-2020;Path=/;HttpOnly;secure;Expires=Sat, 18 Apr 2020 12:00:00 GMT
Set-Cookie: WMF-Last-Access=17-Mar-2020;Path=/;HttpOnly;secure;Expires=Sat, 18 Apr 2020 12:00:00 GMT
X-Client-IP: 140.114.202.20
Cache-Control: private, s-maxage=0, max-age=0, must-revalidate
Set-Cookie: WMF-Last-Access=17-Mar-2020;Path=/;HttpOnly;secure;Expires=Sat, 18 Apr 2020 12:00:00 GMT
Accept-Ranges: bytes
Transfer-Encoding: chunked
Connection: keep-aliveการอ่านเนื้อหาภายในเว็บ
หากต้องการเนื้อหา (โค้ด html) ภายในเว็บ ทำได้โดยใช้เมธอด .text() เช่น
async def aioioio():
async with aiohttp.ClientSession() as ses:
url = 'https://ja.wikipedia.org/wiki/Async'
r = await ses.get(url)
html = await r.text()
print(len(html)) # ลองดูความยาวโค้ดทั้งหมด
print(html.count('div')) # ลองนับจำนวนคำว่า div
ss = html.split('\n') # แบ่งเป็นบรรทัด
print(len(ss)) # ลองดูจำนวนบันทัด
print('\n'.join(ss[:5])) # ลองดู 5 บรรทัดแรก
asyncio.run(aioioio())ได้
63738
506
136
<!DOCTYPE html>
<html class="client-nojs" lang="ja" dir="ltr">
<head>
<meta charset="UTF-8"/>
<title>async - Wikipedia</title>ตรงนี้ .text() ก็เป็นฟังก์ชันโครูทีน จึงต้องใช้กับ await เช่นกัน
เวลาอ่านหน้าเว็บ ปกติจะมีการถอดรหัสอักษรตามรูปแบบที่กำหนดไว้ใน charset ในที่นี้คือ UTF-8 เช่นเดียวกับเว็บส่วนใหญ่สมัยนี้
ถ้าหากต้องการให้แน่ใจว่าจะถอดรหัสถูกต้องตามที่ต้องการก็อาจใส่ระบุไปโดยตรงได้ที่คีย์เวิร์ด encoding เช่นถ้าพิมพ์
r.text(encoding='UTF-8') แบบนี้หน้าเว็บก็จะถูกถอดเป็น UTF-8 ไม่ว่า charset
จะถูกกำหนดมาเป็นยังไงก็ตามเพียงแต่โดยทั่วไปเว็บสมัยใหม่มักจะกำหนด charset ไว้ตรงอยู่แล้ว ถ้าหากไม่มีข้อผิดพลาดอะไรก็อาจไม่ได้จำเป็นต้องกำหนด encoding โดยตรง
หากต้องการให้อ่านโดยไม่มีการถอดรหัสก็ใช้เมธอด .read() จะได้ข้อมูลมาเป็นชนิดไบต์
ลองดูความแตกต่างระหว่าง .read() กับ .text()
async def aioioio():
async with aiohttp.ClientSession() as ses:
url = 'https://ja.wikipedia.org/wiki/IO'
r = await ses.get(url)
text = await r.text()
read = await r.read()
print(type(text)) # ได้ <class 'str'>
print(len(text)) # ได้ 33855
print(type(read)) # ได้ <class 'bytes'>
print(len(read)) # ได้ 37753.read() เหมาะจะใช้เมื่อต้องการโหลดข้อมูลทั้งหมดโดยตรงมากกว่า ในขณะที่ .text() ใช้เมื่อต้องการอ่านเนื้อหาข้างใน เอาเนื้อหาบางส่วนมาใช้
การเชื่อมต่อหลายครั้งพร้อมๆกัน
ตัวอย่างที่ยกมาจนถึงตรงนี้แค่อ่านหน้าเว็บทีละหน้าธรรมดา แบบนี้ใช้ aiohttp ไปก็อาจไม่มีผลอะไรนัก นอกจากจะทำให้โค้ดเขียนยากขึ้นกว่าใช้ requests หรือ urllib
แต่จุดประสงค์ของการที่เราใช้ aiohttp ก็คือเพื่อจะสามารถทำการเชื่อมต่อดึงข้อมูลจากเว็บได้อย่างรวดเร็ว จึงต้องอาศัยวิธีอะซิงโครนัส
ตรงนี้ได้เวลาใช้ฟังก์ชันต่างๆในมอดูล asyncio ที่ใช้งานได้สะดวก เช่น asyncio.wait, asyncio.gather, asyncio.as_completed ฟังก์ชันเหล่านี้ช่วยให้สามารถรันโครูทีนหลายตัวได้ในเวลาเดียวกัน
ในที่นี้ขอใช้แค่ asyncio.gather เป็นหลัก เพราะเข้าใจได้ง่ายที่สุด แต่หากจะเปลี่ยนมาใช้วิธีอื่นดูก็ได้เช่นกัน ในตัวอย่างส่วนใหญ่สามารถใช้แทนกันได้
ขอยกตัวอย่างโดยให้ไปดึงข้อมูลโค้ด html ของหน้าตัวเลข 0 ถึง 4 จากหน้าวิกิพีเดีย เพื่อมาดูว่ายาวแค่ไหนและมีกี่บรรทัด ทำได้ดังนี้
import aiohttp,asyncio,time
async def aioioio():
async with aiohttp.ClientSession() as ses:
url = 'https://vi.wikipedia.org/wiki/'
coru_get = [ses.get(url+'%d'%i) for i in range(5)]
print('[เริ่มโหลดหน้าเว็บ] เวลาผ่านไป %.6f'%(time.time()-t0))
rr = await asyncio.gather(*coru_get)
print('[โหลดเสร็จแล้ว] เวลาผ่านไป %.6f'%(time.time()-t0))
coru_text = [r.text() for r in rr]
print('[เริ่มอ่านข้อมูล] เวลาผ่านไป %.6f'%(time.time()-t0))
htmlhtml = await asyncio.gather(*coru_text)
for i,html in enumerate(htmlhtml):
print('หน้า %s ยาว %d มี %d บรรทัด'%(rr[i].url,len(html),len(html.split('\n'))))
print('[อ่านเสร็จแล้ว] เวลาผ่านไป %.6f'%(time.time()-t0))
t0 = time.time()
asyncio.run(aioioio())ได้
[เริ่มโหลดหน้าเว็บ] เวลาผ่านไป 0.000397
[โหลดเสร็จแล้ว] เวลาผ่านไป 0.296747
[เริ่มอ่านข้อมูล] เวลาผ่านไป 0.296778
หน้า https://vi.wikipedia.org/wiki/0 ยาว 33858 มี 273 บรรทัด
หน้า https://vi.wikipedia.org/wiki/1 ยาว 72232 มี 347 บรรทัด
หน้า https://vi.wikipedia.org/wiki/2 ยาว 62739 มี 316 บรรทัด
หน้า https://vi.wikipedia.org/wiki/3 ยาว 62227 มี 318 บรรทัด
หน้า https://vi.wikipedia.org/wiki/4 ยาว 61862 มี 316 บรรทัด
[อ่านเสร็จแล้ว] เวลาผ่านไป 0.342659ในที่นี้เราเริ่มจากสร้างโครูทีนของเมธอด .get() เตรียมไว้ในลิสต์ coru_get จากนั้นก็ใช้ asyncio.gather เพื่อทำการอ่านข้อมูลพร้อมกัน
ขั้นตอนต่อมาคือการอ่านข้อความจากหน้าเว็บด้วยเมธอด .text() นี่ก็เตรียมไว้ในลิสต์ก่อนเช่นกัน จากนั้นก็มาปล่อยให้ทำงานพร้อมกันด้วย asyncio.gather อีกที
พอทำแบบนี้ก็จะเกิดการโหลดและอ่านข้อมูลอย่างรวดเร็ว
ลองเปลี่ยนโดยเพิ่มจำนวนหน้าที่โหลดให้มากขึ้น เช่นเพิ่มจาก 0 ถึง 4 เป็นถึง 9 แทนแล้วทำแบบเดิมก็จะพบว่าเวลาแทบไม่ต่างจากเดิม
แต่วิธีที่ดีกว่าก็คือให้รวมขั้นตอนทั้งหมดที่ต้องการทำแยกกันไว้สร้างเป็นฟังก์ชันโครูทีนแยกไว้ต่างหาก
เช่นลองเขียนฟังก์ชันที่ดึงข้อมูลหน้าตัวเลขจากวิกิพีเดียเช่นเดียวกับตัวอย่างที่แล้ว แต่คราวนี้แยกฟังก์ชัน
async def loadwiki(ses,url):
lek = url.split('/')[-1]
print('[หน้า %s เริ่มโหลด] เวลาผ่านไป %.6f'%(lek,time.time()-t0))
r = await ses.get(url)
print('[หน้า %s โหลดเสร็จ] เวลาผ่านไป %.6f'%(lek,time.time()-t0))
html = await r.text()
print('หน้า %s ยาว %d มี %d บรรทัด'%(url,len(html),len(html.split('\n'))))
print('[หน้า %s อ่านเสร็จ] เวลาผ่านไป %.6f'%(lek,time.time()-t0))
async def aioioio():
async with aiohttp.ClientSession() as ses:
coruru = [loadwiki(ses,'https://nl.wikipedia.org/wiki/%d'%i) for i in range(5)]
await asyncio.gather(*coruru)
t0 = time.time()
asyncio.run(aioioio())ได้
[หน้า 0 เริ่มโหลด] เวลาผ่านไป 0.000671
[หน้า 1 เริ่มโหลด] เวลาผ่านไป 0.023000
[หน้า 2 เริ่มโหลด] เวลาผ่านไป 0.023533
[หน้า 3 เริ่มโหลด] เวลาผ่านไป 0.023896
[หน้า 4 เริ่มโหลด] เวลาผ่านไป 0.024206
[หน้า 0 โหลดเสร็จ] เวลาผ่านไป 0.276355
หน้า https://nl.wikipedia.org/wiki/0 ยาว 25283 มี 272 บรรทัด
[หน้า 0 อ่านเสร็จ] เวลาผ่านไป 0.276677
[หน้า 2 โหลดเสร็จ] เวลาผ่านไป 0.277732
[หน้า 4 โหลดเสร็จ] เวลาผ่านไป 0.279316
[หน้า 3 โหลดเสร็จ] เวลาผ่านไป 0.281153
หน้า https://nl.wikipedia.org/wiki/2 ยาว 64762 มี 382 บรรทัด
[หน้า 2 อ่านเสร็จ] เวลาผ่านไป 0.284768
หน้า https://nl.wikipedia.org/wiki/4 ยาว 66476 มี 392 บรรทัด
[หน้า 4 อ่านเสร็จ] เวลาผ่านไป 0.288138
หน้า https://nl.wikipedia.org/wiki/3 ยาว 62396 มี 374 บรรทัด
[หน้า 3 อ่านเสร็จ] เวลาผ่านไป 0.288892
[หน้า 1 โหลดเสร็จ] เวลาผ่านไป 0.294034
หน้า https://nl.wikipedia.org/wiki/1 ยาว 67829 มี 393 บรรทัด
[หน้า 1 อ่านเสร็จ] เวลาผ่านไป 0.302973เนื่องจากแยกไว้อีกฟังก์ชัน ดังนั้นจำเป็นต้องใส่ตัวออบเจ็กต์เซสชันลงไปในฟังก์ชันนั้นด้วย พร้อมกับ url ของแต่ละหน้าที่ต้องการโหลด
พอเขียนแบบนี้แล้วจะดูเป็นระเบียบและเข้าใจง่ายขึ้นกว่า
การโหลดเว็บหรือข้อมูลมาเก็บไว้
ตอนนี้รู้วิธีอ่านหน้าเว็บแล้ว และเมื่อจะโหลดข้อมูลหน้าเว็บมาลงใส่ไฟล์ในเครื่องก็แค่เพิ่มส่วนบันทึกข้อมูลลงไป อาจใช้ with open() เพียงแต่ว่า open() ไม่ใช่โครูทีน ในที่นี้จึงเขียน with เฉยๆ ไม่ต้องใช้เป็น async with
ตัวอย่าง
async def loadwiki(ses,url):
lek = url.split('/')[-1]
r = await ses.get(url)
with open(lek+'.html','wb') as f:
f.write(await r.read())
async def aioioio():
async with aiohttp.ClientSession() as ses:
coruru = [loadwiki(ses,'https://ko.wikipedia.org/wiki/%d'%i) for i in range(5)]
await asyncio.gather(*coruru)
asyncio.run(aioioio())กรณีที่ต้องการโหลดข้อมูลทั้งหน้าเว็บอยู่แล้วแบบนี้ไม่จำเป็นต้องอ่านแบบถอดโค้ดด้วยเมธอด .text() แต่ใช้ .read() ซึ่งอ่านเป็นข้อมูลดิบไปเลยจะเร็วกว่า ในเปิดไฟล์ก็ให้เปิดในโหมด wb (คือ write binary)
การโหลดไฟล์เป็นก้อนๆ
สำหรับไฟล์ที่มีขนาดใหญ่มากเช่นพวกรูปภาพแทนที่จะโหลดทีเดียวควรใช้วิธีการโหลดเป็นก้อนๆมากกว่า
ปกติถ้าใช้เมธอด .read() ไฟล์จะถูกอ่านหมดในทีเดียว แต่ก็มีวิธีที่จะทำให้ไฟล์ค่อยๆอ่านออกมา นั่นคือใช้ .content.read() โดยระบุขนาดก้อนที่ต้องการโหลดไว้ในวงเล็บ
ตัวอย่าง ให้โหลดทีละ 1 กิโลไบต์ (1024 ไบต์)
async def loadhina(ses,url):
chue_file = url.split('/')[-1]
r = await ses.get(url)
with open(chue_file,'wb') as f:
while(1):
c = await r.content.read(1024)
if(c):
f.write(c)
else:
break
async def aioioio():
async with aiohttp.ClientSession() as ses:
lis_lek = [2357144827637608,1570268969658535,2666957966656291]
coruru = [loadhina(ses,'https://hinaboshi.com/rup/rupprakopwalidet/%d.jpg'%i) for i in lis_lek]
await asyncio.gather(*coruru)
asyncio.run(aioioio())แล้วก็จะโหลดได้ภาพมาได้

การเติม .content เข้ามาจะทำให้ข้อมูลถูกอ่านในรูปแบบสตรีม
การใส่พารามิเตอร์ลงใน get
ปกติเวลาเชื่อมต่อเว็บด้วย get นั้นหลังจาก url แล้วสามารถเติมเครื่องหมายคำถาม ? แล้วเติมข้อมูลพารามิเตอร์เข้าไปด้านหลัง url ได้
สำหรับการใช้งานใน asyncio นี้เราจะพิมพ์ต่อจาก url ลงไปโดยตรงเลยก็ได้ หรือจะใส่พารามิเตอร์ลงไปในคีย์เวิร์ด params เมื่อใช้ .get() ก็ได้
พารามิเตอร์ให้ใส่ในรูปของลิสต์ของทูเพิลคู่ของชื่อและค่า
ตัวอย่างเช่น หน้าวิกิพีเดียภาษาไทยหากพิมพ์ชื่อภาษาอังกฤษไปมันจะโยงตรงไปยังหน้าที่เป็นชื่อภาษาไทย แต่เมื่อใส่ ?redirect=no ลงไปก็จะไม่ถูกโยง
ตัวอย่าง
async def aioioio():
async with aiohttp.ClientSession() as ses:
url = 'https://th.wikipedia.org/wiki/bangkok'
coru0 = ses.get(url)
coru1 = ses.get(url,params=[('redirect','no')])
coru2 = ses.get(url,params=[('redirect','yes')])
for coru in asyncio.as_completed([coru0,coru1,coru2]):
r = await coru
html = await r.text()
print('%s\nยาว %d มี %d บรรทัด'%(r.url,len(html),len(html.split('\n'))))
asyncio.run(aioioio())ได้
https://th.wikipedia.org/wiki/Bangkok
ยาว 693396 มี 2039 บรรทัด
https://th.wikipedia.org/wiki/bangkok?redirect=no
ยาว 23838 มี 237 บรรทัด
https://th.wikipedia.org/wiki/bangkok?redirect=yes
ยาว 693510 มี 2039 บรรทัดการใช้ post
ในตัวอย่างที่ผ่านมาล้วนใช้ get แต่หากจะใช้ post ก็สามารถทำได้คล้ายๆกัน ทำโดยใช้เมธอด .post
ข้อมูลที่จะป้อนให้ขณะที่ post ให้ใส่ไว้ในคีย์เวิร์ด data ในรูปของดิกชันนารี
ตัวอย่างเช่น ปกติแล้วเวลาที่ทำการค้นข้อความอะไรในวิกิพีเดียจะเป็นการส่ง post เข้า https://th.wikipedia.org/w/index.php พร้อมส่งข้อมูลคำที่ต้องการค้นไว้ใน search จากนั้นวิกิก็จะพาโยงไปยังหน้าที่ค้น
async def aioioio():
async with aiohttp.ClientSession() as ses:
url = 'https://th.wikipedia.org/w/index.php'
kham = ['python','java','ruby']
coruru = [ses.post(url,data={'search':x}) for x in kham]
rr = await asyncio.gather(*coruru)
for r in rr:
print('%s\n-> %s'%(r.history[0].url,r.url))
asyncio.run(aioioio())ได้
https://th.wikipedia.org/w/index.php
-> https://th.wikipedia.org/wiki/Python
https://th.wikipedia.org/w/index.php
-> https://th.wikipedia.org/wiki/Java
https://th.wikipedia.org/w/index.php
-> https://th.wikipedia.org/wiki/Rubyในที่นี้มีการใช้แอตทริบิวต์ .history คือโดยปกติหากมีการโยงเปลี่ยนหน้า ประวัติจะถูกเก็บเอาไว้ในแอตทริบิวต์ .history ดังที่เห็น เป็นออบเจ็กต์ของการเชื่อมต่อครั้งก่อนหน้า เอามาดูข้อมูลได้เช่นกัน เมื่อดู url ก็จะพบว่าเป็น url ที่ใส่ไปตอนแรก แต่ถ้าดู url ของตัวออบเจ็กต์ปัจจุบันจะพบว่าเป็นอีกหน้าซึ่งเปลี่ยนตามคำที่เราค้นไป
นอกจากนี้ก็ยังมี patch, delete, ฯลฯ ก็ใช้ได้เช่นกัน ซึ่งจะไม่ได้เขียนถึงในที่นี้
การอ่าน json
หากข้อมูลเป็น json สามารถใช้เมธอด .json เพื่อแปลงข้อมูลเป็นดิกชันนารีได้ทันที สามารถนำมาใช้ได้สะดวก
ขอใช้ qiita api เป็นตัวอย่าง รายละเอียดอ่านได้ใน https://phyblas.hinaboshi.com/20190627
async def aioioio():
async with aiohttp.ClientSession() as ses:
url = 'https://qiita.com/api/v2/tags/'
tagtag = ['c','c++','csharp']
coruru = [ses.get(url+tag) for tag in tagtag]
for coru in asyncio.as_completed(coruru):
r = await coru
qjson = await r.json()
print('\n==%s=='%r.url)
for k in qjson:
print('%s = %s'%(k,qjson[k]))
asyncio.run(aioioio())ได้
==https://qiita.com/api/v2/tags/c==
followers_count = 26303
icon_url = https://s3-ap-northeast-1.amazonaws.com/qiita-tag-image/ceb54fec6cccd1711edeeccfca306a16ecf08834/medium.jpg?1481808976
id = C
items_count = 3057
==https://qiita.com/api/v2/tags/csharp==
followers_count = 29041
icon_url = https://s3-ap-northeast-1.amazonaws.com/qiita-tag-image/5d80f1647ab8e9f5dde2fd4164c24cd26bfcc672/medium.jpg?1558927763
id = C#
items_count = 9190
==https://qiita.com/api/v2/tags/c++==
followers_count = 30485
icon_url = https://s3-ap-northeast-1.amazonaws.com/qiita-tag-image/fe7df47710bdae8b8565b323841a6b89e2f66b89/medium.jpg?1515774066
id = C++
items_count = 7144เปรียบเทียบความเร็วกับมัลติโพรเซสซิง
เพื่อแสดงให้เห็นว่าอะซิงโครนัสเป็นวิธีที่มีประสิทธิภาพในการดึงข้อมูลมากจริงๆ ลองเปรียบเทียบกับมัลติโพรเซสซิงดู
เกี่ยวกับมัลติโพรเซสซิงอ่านได้ใน https://phyblas.hinaboshi.com/20180317
ลองให้ไล่ดึงข้อมูลตัวเลขจากวิกิพีเดีย ลองเทียบความเปลี่ยนแปลงต่อจำนวนหน้าที่โหลด ตั้งแต่ ๑ หน้า ถึง ๙ หน้า
import multiprocessing as mp
import aiohttp,asyncio,time,requests
# ฟังก์ชันที่ใช้ multiprocessing
def load_mp(lek):
url = 'https://th.wikipedia.org/wiki/%d'%lek
r = requests.get(url)
with open('mp_%d.html'%lek,'wb') as f:
f.write(r.content)
# ฟังก์ชันที่ใช้ async
async def load_asy(ses,lek):
url = 'https://th.wikipedia.org/wiki/%d'%lek
r = await ses.get(url)
with open('asy_%d.html'%lek,'wb') as f:
f.write(await r.read())
async def main(n):
async with aiohttp.ClientSession() as ses:
coruru = [load_asy(ses,i) for i in range(n)]
await asyncio.gather(*coruru)
if(__name__=='__main__'):
t_ml = []
t_asy = []
for n in range(1,10):
# เริ่มโหลดด้วย multiprocessing
t0 = time.time()
mp.Pool(processes=n).map(load_mp,range(n))
t_ml.append(time.time()-t0) # ได้ 0.5492181777954102
# เริ่มโหลดด้วย async
t0 = time.time()
asyncio.run(main(n))
t_asy.append(time.time()-t0) # ได้ 0.35967516899108887
print(t_ml)
print(t_asy)ได้
[0.37029385566711426, 0.36657190322875977, 0.3823528289794922, 0.39493608474731445, 0.3996908664703369, 0.4152510166168213, 0.4314148426055908, 0.44281506538391113, 0.4738590717315674]
[0.3343980312347412, 0.31613683700561523, 0.31936192512512207, 0.32141804695129395, 0.3262810707092285, 0.3238258361816406, 0.32375288009643555, 0.3356812000274658, 0.3322031497955322]หากนำมาวาดกราฟก็จะได้ดังนี้
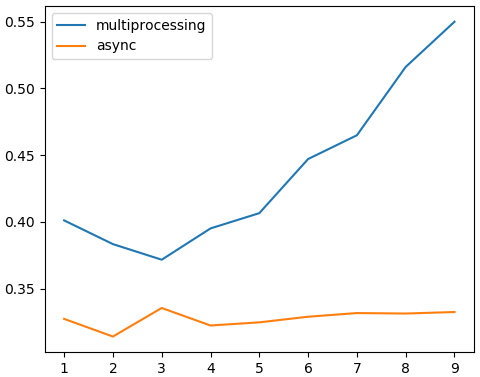
จะเห็นได้ว่าเมื่อใช้มัลติโพรเซสซิงพอจำนวนงานเพิ่มขึ้นก็จะค่อยๆกินเวลามากขึ้น เพราะต่อให้แยกงานกันทำคู่ขนานไป แต่ CPU ก็มีจำกัด ยิ่งงานมากก็ดึงกันเองไปด้วย
ในขณะที่เมื่อใช้อะซิงโครนัสจะใช้เวลาน้อยกว่า และจะโหลดกี่หน้าก็แทบไม่เห็นผลว่าต่างกันมาก ยังคงเสร็จอย่างรวดเร็ว
ดังนั้นถ้าใช้ aiohttp เป็นก็จะสามารถดึงข้อมูลจากเว็บมาได้อย่างรวดเร็ว
อ้างอิง