ภาษา python เบื้องต้น บทที่ ๑๗: การอ่านข้อมูลจากไฟล์
เขียนเมื่อ 2016/03/05 22:41
แก้ไขล่าสุด 2024/02/22 11:04
การอ่านและเขียนไฟล์เป็นเรื่องสำคัญมากอย่างหนึ่งในการเขียนโปรแกรม เพราะบางทีเราอาจต้องการบันทึกข้อมูลเก็บเอาไว้หรือนำข้อมูลจากที่ไหนมาใช้
ไฟล์มีหลากหลายชนิดต่างกันไปตามแต่ว่าใช้ทำอะไร แต่โดยหลักๆแล้วก็จะประกอบไปด้วยตัวหนังสือ หากเปิดด้วยโปรแกรมสำหรับอ่านเขียนข้อความเช่น notepad ก็จะเห็นเป็นโค้ดตัวหนังสือเรียงต่อๆกัน
ไฟล์ยังแบ่งเป็นไฟล์ข้อความ ที่มนุษย์อ่านรู้เรื่องได้ กับไฟล์ที่มีแต่โค้ดเลขฐานสองที่คอมเท่านั้นที่อ่านได้ ซึ่งเรียกว่าไฟล์ชนิดไบนารี (binary) อย่างไรก็ตามในบทนี้จะพูดถึงการจัดการกับไฟล์ที่เป็นตัวหนังสือที่สามารถ อ่านได้ จะไม่พูดถึงไฟล์แบบไบนารี
การจัดการไฟล์นั้นโดยรวมๆแล้วประกอบไปด้วย
- นำข้อมูลจากไฟล์มาอ่าน
- เขียนไฟล์ขึ้นมาใหม่
- แก้ไขไฟล์ที่มีอยู่เดิม
ขั้นตอนการจัดการไฟล์นั้นมีหลักๆ ๓ ขั้น คือ
- เปิดไฟล์
- ใช้ไฟล์ (เพื่ออ่านหรือเขียน)
- ปิดไฟล์
ในที่นี้ขอยกข้อความสำหรับเป็นไฟล์ตัวอย่าง เป็นเนื้อเพลงของเพลง nishikaze no okurimono
(ที่มา)
ไฟล์ตัวอย่าง nishikaze.txt
Quando Zefiro danza prendendo Flora per mano,
il mar Tirreno si muta in azzurro e giunge la primavera.
Finisce il cupo inverno il porto è pieno di barche tornate a casa.
Quel ragazzo che cammina lungo il molo con
le guance tinte tornerà dal suo amor.
Per il gentile vento che soffia da est il ciel si fa via via sereno,
i pesci risvegliatisi dal lungo sonno
sporgon furtivamente la testa tra le onde.
Quando Zefiro sussurra a Flora parole d'amore,
i boccioli dei fiori si gonfian di rosa e giunge la primavera.
I fischi a vapore giungono alla banchina
il porto è pieno di gente che va in paesi lontani.
Con la speranza e l'inquietudine nel cuore,
i pionieri raggiungeranno terre mai viste.
Il vento dell'est insieme ai fiori
si dirige verso nuove città,
le rondini, cantando la canzone appena imparata,
gioiscono della nuova stagion.
il mar Tirreno si muta in azzurro e giunge la primavera.
Finisce il cupo inverno il porto è pieno di barche tornate a casa.
Quel ragazzo che cammina lungo il molo con
le guance tinte tornerà dal suo amor.
Per il gentile vento che soffia da est il ciel si fa via via sereno,
i pesci risvegliatisi dal lungo sonno
sporgon furtivamente la testa tra le onde.
Quando Zefiro sussurra a Flora parole d'amore,
i boccioli dei fiori si gonfian di rosa e giunge la primavera.
I fischi a vapore giungono alla banchina
il porto è pieno di gente che va in paesi lontani.
Con la speranza e l'inquietudine nel cuore,
i pionieri raggiungeranno terre mai viste.
Il vento dell'est insieme ai fiori
si dirige verso nuove città,
le rondini, cantando la canzone appena imparata,
gioiscono della nuova stagion.
คัดลอกข้อความลงไปเซฟ ให้เซฟลงไว้ที่โฟลเดอร์เดียวกับไฟล์โปรแกรม เวลาเซฟนั้นให้ดูด้วยว่าเอนโค้ดเป็นอะไร ในที่นี้ขอให้เลือกเป็น utf-8 (ใน notepad หากเลือกเป็น unicode จะหมายถึง utf-16)
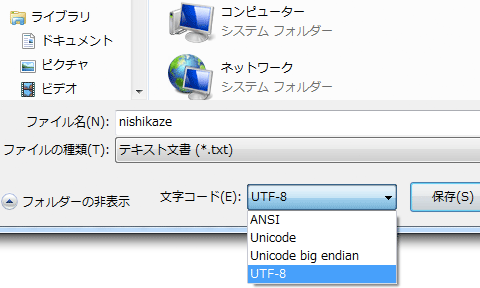
เพื่อให้เห็นภาพรวมก่อนขอเริ่มด้วยโค้ดตั้งแต่เปิดไฟล์ ใช้ไฟล์ แล้วก็ปิดไฟล์
f = open('nishikaze.txt','r',encoding='utf-8') # เปิดไฟล์
print(f.read()) # อ่านไฟล์
f.close() # ปิดไฟล์ จบ ๓ ขั้นตอนสั้นๆ ผลที่ได้ก็คือข้อความจากภายในไฟล์นั้นทั้งหมดถูกแสดงผลออกมา
ต่อไปจะเริ่มอธิบายทีละส่วนอย่างละเอียด
การเปิดไฟล์
ขั้นตอนแรกในการจัดการไฟล์ก็คือเปิดไฟล์ โดยใช้ฟังก์ชัน open
f = open('nishikaze.txt','r',encoding='utf-8')อาร์กิวเมนต์ ตัวแรกคือชื่อไฟล์ สามารถใส่แค่ชื่อไฟล์ถ้าหากอยู่ในโฟลเดอร์เดียวกับไฟล์โปรแกรมที่รัน แต่ถ้าไม่ใช่ก็ต้องใส่พาธไล่ตำแหน่งให้ถูก เช่นถ้าเก็บไว้ในโฟล์เดอร์ชื่อ xxx ซึ่งอยู่ที่เดียวกับไฟล์โปรแกรมก็ต้องใส่เป็น xxx/nishikaze.txt เป็นต้น สามารถใช้ได้ทั้งพาธสัมบูรณ์และพาธสัมพัทธ์
ส่วนอาร์กิวเมนต์ตัวที่สองซึ่งในที่นี้ใส่เป็น
'r' นี้คือโหมดของการเปิดไฟล์ ซึ่ง r หมายถึงว่าเราจะเปิดไฟล์นี้ขึ้นมาเพื่ออ่านโหมดในการเปิดไฟล์ซึ่งต้องระบุเป็นอาร์กิวเมนต์ตัวที่ ๒ ของฟังก์ชัน
open นั้นมีอยู่หลากหลาย สามารถเลือกได้ดังนี้r เปิดเพื่ออ่านอย่างเดียว หากไม่มีไฟล์ชื่อนี้อยู่จะเกิดขัดข้องขึ้น
r+ เปิดเพื่ออ่านและสามารถเขียนทับได้ หากไม่มีไฟล์ชื่อนี้อยู่จะเกิดขัดข้องขึ้น
w เปิดเพื่อเขียนไฟล์ทับ หากไม่มีไฟล์ชื่อนี้อยู่จะเป็นการสร้างไฟล์ใหม่หากมีไฟล์อยู่แล้วก็จะเขียนทับ
x เตรียมพื้นที่ว่างเพื่อจะเขียนไฟล์ เมื่อใช้โหมดนี้จะต้องไม่มีไฟล์ชื่อนี้อยู่ หากมีไฟล์ชื่อนี้อยู่แล้วจะเกิดขัดข้องขึ้น
a เปิดเพื่อเขียนไฟล์ต่อ หากไม่มีไฟล์ชื่อนี้อยู่จะเป็นการสร้างไฟล์ใหม่ หากมีอยู่แล้วจะเป็นการเขียนต่อ
สรุปเป็นตารางเพื่อให้เข้าใจง่ายขึ้น
| โหมด | อ่าน | เขียน | หากไม่มีไฟล์อยู่เดิม | หากมีไฟล์อยู่เดิม |
|---|---|---|---|---|
| r | ได้ | ไม่ได้ | เกิดขัดข้อง | เปิดอ่านได้ |
| w | ไม่ได้ | ได้ | สร้างไฟล์ใหม่ขึ้น | ลบข้อมูลเก่าแล้วเขียนใหม่ |
| a | ไม่ได้ | ได้ | สร้างไฟล์ใหม่ขึ้น | เขียนต่อจากที่มีอยู่เดิม |
| x | ไม่ได้ | ได้ | สร้างไฟล์ใหม่ขึ้น | เกิดขัดข้อง |
| r+ | ได้ | ได้ | เกิดขัดข้อง | เปิดอ่านได้ เมื่อเขียนจะเขียนต่อจากที่มีอยู่เดิม |
| w+ | ได้ | ได้ | สร้างไฟล์ใหม่ขึ้น | ลบข้อมูลเก่าแล้วเขียนใหม่ |
| a+ | ได้ | ได้ | สร้างไฟล์ใหม่ขึ้น | เขียนต่อจากที่มีอยู่เดิม |
นอกจากนี้ยังมีโหมดอื่นๆอีก เช่น
b ซึ่งเป็นโหมดสำหรับเปิดไฟล์ชนิดไบนารี ซึ่งในที่นี้จะไม่พูดถึงหากไม่ได้ระบุโหมดจะถูกกำหนดเป็นโหมด
r โดยอัตโนมัติ ดังนั้นหากจะเลือกโหมดอ่านไม่จำเป็นต้องใส่ ,'r' ก็ได้ ปล่อยว่างไว้เลยดังนั้นจะเขียนแบบนี้ก็ได้
f = open('/Users/patn/Desktop/nishikaze.txt',encoding='utf-8')ส่วนคีย์
encoding ที่ใส่ลงไปท้ายสุดนั้นเป็นการระบุว่าจะถอดรหัสแบบไหน ในที่นี้เลือก utf-8ที่จริงแล้วคีย์
encoding อาจไม่จำเป็นต้องใส่หากว่าเครื่องเรากำหนดรูปแบบการถอดรหัสมาตรฐานเป็น utf-8 อยู่แล้ว ก็จะใส่แค่
f = open('/Users/patn/Desktop/nishikaze.txt','r')อย่างไรก็ตามโดยทั่วไปอาจไม่เป็นแบบนั้น หากใส่ไปทั้งๆแบบนี้ไฟล์จะถูกอ่านโดยถอดรหัสเป็นแบบไหนก็ไม่รู้ ซึ่งก็ขึ้นอยู่กับเครื่องและระบบปฏิบัติการ มีปัจจัยมาเกี่ยวข้องด้วยมากมาย
โดยปกติระบบจะกำหนดรูปแบบการถอดรหัสมาตรฐานไว้ให้อยู่แล้ว หากไม่ได้แก้ไขเปลี่ยนแปลงอะไรไฟล์ก็จะถูกอ่านแบบนั้น
เช่นบางเครื่องอาจเป็น cp874, cp932, cp1252 หรือ US-ASCII หรือบางเครื่องอาจเป็น utf-8 ก็เป็นได้
หากบังเอิญรูปแบบการถอดรหัสมาตรฐานนี้ไปตรงกับไฟล์ที่จะเซฟก็จะสามารถอ่านไฟล์ ได้โดยไม่มีปัญหาอะไร แต่เพื่อความปลอดภัยเพื่อให้สามารถรันได้กับทุกเครื่องแล้วระบุ
encoding ไว้ตลอดดีที่สุดหากต้องการรู้ว่าเครื่องตัวเองรูปแบบการถอดรหัส มาตรฐานเป็นแบบไหนก็ทำได้โดยเรียกใช้ฟังก์ชัน
getpreferredencoding ซึ่งอยู่ในมอดูล locale
import locale
print(locale.getpreferredencoding())ไฟล์ที่เปิดขึ้นมานั้นจะอยู่ในรูปของออบเจ็กต์ชนิดหนึ่งซึ่งออบเจ็กต์นี้จะต้องเอาตัวแปรมารับเพื่อที่จะนำไปใช้งานต่อไป
ในที่นี้ใช้ตัวแปร
f มารับไฟล์ ต่อจากนี้ไปตัวแปร f ก็จะเป็นตัวแทนของไฟล์ที่เปิดขึ้นมา ซึ่งเราจะใช้เมธอดต่างๆเพื่อจัดการกับไฟล์ต่อไปการอ่านไฟล์
เมื่อเปิดมาแล้วขั้นตอนต่อไปก็คือการนำไฟล์มาอ่าน หรือก็คือการเอาข้อมูลภายในไฟล์มาใช้
คำสั่งที่ใช้ในการอ่านไฟล์มีอยู่หลายตัว ขอเริ่มจากวิธีที่ง่ายที่สุดก็คือใช้เมธอดที่ชื่อ
.readไฟล์ที่อ่านมานั้นโดยปกติจะเริ่มถูกอ่านจากข้อความแรกสุดไล่ไปเรื่อยๆจนจบ โดยระหว่างที่อ่านไปโปรแกรมจะมีการจำไว้ว่าอ่านถึงไหนแล้ว
.read เป็นเมธอดของออบเจ็กต์ของไฟล์ มีไว้สำหรับอ่านเอาข้อมูลที่มีอยู่ในไฟล์ตั้งแต่จุดที่อ่านไปถึงปัจจุบัน จนถึงสิ้นสุดไฟล์ โดยจะคืนค่าที่อ่านได้ออกมาในที่นี้เราใช้
.read ตั้งแต่เริ่ม จึงเป็นการอ่านไฟล์ตั้งแต่ต้นรวดเดียวไปจนจบทั้งหมดและในที่นี้เราใช้คำสั่ง
print เพื่อให้แสดงผลค่าที่อ่านได้ออกมาทันที ดังนั้นข้อความในไฟล์ทังหมดจึงถูกแสดงผลออกมาทันทีและหลังจากเปิดไฟล์ขึ้นมาแล้วจัดการทำอะไรเสร็จเรียบร้อยแล้ว ขั้นตอนสุดท้ายก็คือปิดไฟล์ ซึ่งทำได้โดยเมธอด
.closeการอ่านไฟล์ในตำแหน่งที่ต้องการ
.read นั้นถ้าไม่ได้ใส่อาร์กิวเมนต์อะไรลงไปจะเป็นการอ่านจนจบไฟล์ แต่ถ้าใส่ก็จะเป็นการอ่านจำนวนตัวอักษรเท่ากับจำนวนที่ระบุ
f = open('nishikaze.txt','r',encoding='utf-8')
print(f.read(44))
f.close()แบบนี้จะได้ข้อความเฉพาะในบรรทัดแรกออกมา
f = open('nishikaze.txt','r',encoding='utf-8')
while(1):
s = f.read(50)
if(s==''): break #ถ้า s ว่างเปล่าแสดงว่าสิ้นสุดไฟล์อ่านไม่ได้แล้ว ให้หยุดวนซ้ำ
print(s)
f.close()แบบนี้จะเป็นการอ่านไปทีละ ๕๐ ตัวจนกว่าจะจบ
และจะเห็นได้ว่าเมื่อไฟล์ถูกเมธอด
.read อ่านไปจนจบแล้ว หากลองใช้คำสั่ง .read อีกรอบผลที่ได้ก็คือจะได้สายอักขระเปล่า จะอ่านซ้ำอีกกี่รอบก็ยังคงว่างเปล่าแต่ก็ไม่ได้หมายความว่าไฟล์นี้จะไม่สามารถใช้อะไรได้แล้ว เราสามารถย้ายตำแหน่งที่อ่านได้อย่างอิสระด้วยเมธอด
.seek
f.seek(0)แบบนี้จะเป็นการย้ายตำแหน่งที่อ่านไปยังจุดเริ่มต้นของไฟล์ พอทำแบบนี้แล้วก็สามารถใช้คำสั่ง
.read อ่านข้อความทั้งหมดได้อีกครั้งเลข
0 ที่อยู่ในวงเล็บคือตำแหน่งของไฟล์ที่ต้องการอ่าน จะย้ายไปยังส่วนไหนของไฟล์ก็ได้แต่ที่ต้องระวังก็คือหน่วยในการนับตำแหน่งภายในไฟล์ด้วย
.seek นั้นใช้เป็นหน่วยไบต์ไม่ใช่หน่วยตัวอักษรเหมือนอย่าง .read และโดยทั่วไปแล้วตัวอักษรที่เป็น utf-8 นั้นจะมีจำนวนบิตในแต่ละอักษรไม่เท่ากัน อักษรที่ตรงกับ ASCII จะเป็น 1 ไบต์ แต่อักษรอื่นอาจเป็น 2 หรือ 3 ไบต์ ดังนั้นจึงนับจำนวนอักษรไปโดยตรงไม่ได้สำหรับอักษรไทยนั้นเป็นอักษรที่ใช้ 3 ไบต์ ดังนั้นตัวหนึ่งจะคิดเป็น 3 หน่วย
ลองดูตัวอย่างอีกไฟล์
(ที่มา)
ไฟล์ตัวอย่าง
riki.txt บันทึกเป็น utf-8 เหมือนเดิม
หากเปรียบโลกนี้เป็นนาฬิกาเรือนใหญ่ยักษ์
จะประกอบขึ้นจากฟันเฟืองไร้ชื่อจำนวนมหาศาลเพียงใดกัน
ถึงกระนั้น แม้เพียงฟันเฟืองอันเล็กๆก็ตาม หากสั่งสมไปเรื่อยๆ ก็ย่อมทำให้โลกเปลี่ยนแปลงไปได้ทีละน้อย
จะประกอบขึ้นจากฟันเฟืองไร้ชื่อจำนวนมหาศาลเพียงใดกัน
ถึงกระนั้น แม้เพียงฟันเฟืองอันเล็กๆก็ตาม หากสั่งสมไปเรื่อยๆ ก็ย่อมทำให้โลกเปลี่ยนแปลงไปได้ทีละน้อย
ลองพิมพ์
f = open('riki.txt','r',encoding='utf-8')
f.seek(3)
print(f.read())
f.close()ผลที่ได้ก็คือข้อความที่เหมือนที่อยู่ในไฟล์ยกเว้นแค่ตัดอักษรตัวแรกออกไป นั่นเพราะ
f.seek(3) หมายความว่าเลื่อนตำแหน่งไป 3 ไบต์ ซึ่งหมายถึง 1 ตัวอักษรไทยและหากลองรันเหมือนเดิมโดยเพิ่มเลขเป็น 6, 9, 12 หรืออะไรที่หาร 3 ลงตัวไปเรื่อยๆก็จะพบว่าอักษรค่อยๆหายไปทีละตัว
แต่หากเปลี่ยนตัวเลขเป็นอะไรที่หาร 3 ไม่ลงตัวเมื่อไหร่ก็จะขึ้นว่า
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xb8 in position 0: invalid start byteนั่นเพราะอักษรไทยประกอบด้วย 3 ไบต์ ถ้าหากไปอ่านในตำแหน่งครึ่งๆกลางๆมันก็จะไม่สามารถอ่านได้
แต่ปัญหายังมีอีก หากลอง
f.seek(120) ก็จะพบว่ามีปัญหาเช่นกันแม้ว่าจะหาร 3 ลงตัว ที่เป็นแบบนี้เพราะบรรทัดแรกมีอักษรเพียง 39 ตัว ซึ่งคิดเป็นไบต์ที่ 117 และรหัสขึ้นบรรทัดใหม่นั้นคิดเป็น 1 ไบต์ดังนั้นไบต์ที่ 117 จึงเป็นรหัสขึ้นบรรทัดใหม่ และอักษรตั้งแต่บรรทัดใหม่ก็จะเริ่มจาก 118 แล้วก็ตามด้วย 121, 124 ไปเรื่อยๆ
ดังนั้นจะเห็นว่าการใช้
.seek กับ utf-8 ในกรณีที่ไม่ใช่อักษร ASCII นั้นค่อนข้างลำบากทีเดียวดังนั้นแทนที่จะใช้
.seek เพื่อไปยังตำแหน่งต่างๆในไฟล์ น่าจะใช้ .seek แค่เพื่อกลับมายังจุดเริ่มต้น จากนั้นใช้ .read เพื่ออ่านไล่ไปจนถึงข้อความตำแหน่งที่ต้องการจะดีกว่า เพราะ .read นับจำนวนตามตัวอักษรหรือบางครั้งอาจเป็นการสะดวกกว่าหาก
.read ทั้งหมดเก็บไว้ในสายอักขระแล้วค่อยมาวิเคราะห์ภายในโปรแกรม เพราะสายอักขระในโปรแกรมจะนับลำดับตามตัวอักษรอยู่แล้ว ทำให้จัดการง่ายกว่าf = open('riki.txt','r',encoding='utf-8')
s = f.read()
print(s[0:2]) # หา
print(s[34:39]) # ยักษ์
print(s[122:126]) # เล็ก
f.close()หากต้องการรู้ตำแหน่งว่าอ่านไปถึงไหนแล้วสามารถใช้เมธอด
.tell ซึ่งจะคืนค่าตำแหน่งที่อ่านไฟล์กลับมา แต่ก็เป็นหน่วยไบต์เช่นเดียวกับ seekการอ่านไฟล์แยกทีละบรรทัด
โดยปกติแล้วการอ่านไฟล์นั้นจะนิยมอ่านแยกทีละบรรทัด เพราะข้อมูลก็มักจะเก็บแยกเป็นบรรทัดเพื่อความเป็นระเบียบเช่นกัน
เมธอดที่ใช้ในการอ่านแยกบรรทัดมีอยู่ ๒ ตัวคือ
.readlines กับ .readline.readlines เป็นการอ่านไฟล์ทั้งหมดเช่นเดียวกับ .read แต่จะเก็บแยกเป็นบรรทัดลอง
f = open('nishikaze.txt','r',encoding='utf-8')
r = f.readlines()
print(r)
f.close()แบบนี้จะได้ว่าตัวแปร r เก็บข้อความจากไฟล์โดยแยกเป็นบรรทัด หากต้องการเข้าถึงบรรทัดไหนก็แค่ใส่ [ ] เช่น
print(r[1])จะได้ข้อความบรรทัดที่ ๒ (เพราะบรรทัดแรกนับเป็น 0) โดยจะเห็นว่านบรรทัดถูกเว้น เครื่องหมายขึ้นบรรทัดใหม่
\n ถูกรวมอยู่ในนี้ด้วยส่วนอีกวิธีคือเมธอด
.readline เมธอดนี้คล้ายกับ .readlines ชื่อก็คล้ายกัน ต่างกันแค่ s หายไปตัวเดียวเท่านั้น.readline เป็นการอ่านข้อความทีละบรรทัด โดยการใช้ครั้งหนึ่งจะเป็นการอ่านบรรทัดหนึ่ง และพอใช้อีกครั้งก็จะอ่านซ้ำ และอ่านไปจนจบลอง
f = open('nishikaze.txt','r',encoding='utf-8')
for i in range(5):
r = f.readline()
print(r)
f.close()แบบนี้ก็จะได้ข้อความ ๕ บรรทัดแรก
และหาก
f.readline() อีกครั้งก็จะได้ข้อความบรรทัดที่ ๖ ออกมาการอ่านไฟล์ด้วย for
นอกจากการอ่านไฟล์ด้วยเมธอดต่างๆแล้วมีอีกวิธีหนึ่งที่สามารถอ่านไฟล์ได้โดยไม่ จำเป็นต้องใช้เมธอดใดๆเลย นั่นคือใช้ for วนภายในออบเจ็กต์ตัวไฟล์
f = open('nishikaze.txt','r',encoding='utf-8')
for r in f:
print('~~ '+r,end='')
f.close()ผลที่ได้ก็คือไฟล์ถูกอ่านทีละบรรทัดและถูก
print ในแต่ละรอบที่วนมองดูโค้ดแล้วอาจจะรู้สึกงงๆว่า f ซึ่งเป็นออบเจ็กต์ของไฟล์ถูกนำมาใช้เป็นตัววนภายในคำสั่ง for โดยตรงเลย แบบนี้ได้ด้วยหรือ ทั้งๆที่ปกติแล้วคำสั่ง for จะถูกใช้กับออบเจ็กต์ชนิดลำดับเช่นลิสต์, ทูเพิล, ดิกชันนารี
ความจริงแล้วโค้ดนี้มีค่าเท่ากับ
f = open('nishikaze.txt','r',encoding='utf-8')
for r in f.readlines(): # ต่างกันตรงบรรทัดนี้
print('~~ '+r,end='')
f.close() นั่นคือเมื่อออบเจ็กต์ของไฟล์ถูกใช้กับ
for มันจะถูกตัดแบ่งเป็นบรรทัด แล้วถูกดึงข้อมูลมาอ่านทีละบรรทัด เหมือนการใช้เมธอด .readlinesการใช้ with จัดการไฟล์
ปกติแล้วหากใช้ฟังก์ชัน
open จะต้องตามด้วยเมธอด .close เพื่อปิดไฟล์แต่ก็มีอีกวิธีที่สามารถทำได้แทนที่จะใช้
.close นั่นคือใช้ with เพื่อกำหนดขอบเขตที่ไฟล์จะถูกเปิดใช้งานตัวอย่างที่แล้วหากเขียนด้วย
with จะได้แบบนี้
with open('nishikaze.txt','r',encoding='utf-8') as f:
for r in f.readlines():
print('~~ '+r,end='')จะเห็นว่าต่างกันแค่บรรทัดแรกตรง
open ใช้ with แล้วบรรทัดต่อมาก็ต้องมีการร่นเข้ามา และไม่ต้องปิดท้ายด้วย .close แล้วส่วนตรงที่ประกาศตัวแปรที่จะใช้แทนออบเจ็กต์ของไฟล์นั้น แทนที่จะใช้
f= ก็ใช้ as f แทนโครงสร้างโดยทั่วไปของการใช้
with กับ open คือ
with open() as ชื่อตัวแปรที่จะเก็บออบเจ็กต์ของไฟล์:
เนื้อหาส่วนที่จะใช้ไฟล์การใช้โครงสร้างแบบนี้มีความหมายว่าไฟล์จะถูกเปิดอยู่เฉพาะในขอบเขตภายใน โครงสร้าง
with นี้เท่านั้น พอหลุดจากตรงนี้ไปไฟล์จะถูกปิดไปโดยอัตโนมัติจึงไม่ต้อง .closeจะใช้วิธีไหนก็ไม่ต่างกันแต่บางคนชอบใช้วิธีนี้มากกว่าเพราะรับรองได้ว่าไฟล์จะ ถูกปิดหลังจากใช้เสร็จแน่นอน ไม่ต้องพะวงว่าจะลืมปิดท้ายด้วย
.closeหรือในกรณีที่เกิดข้อผิดพลาดระหว่างดำเนินโปรแกรมจนทำให้หยุดทำงานไปก่อนที่จะไปถึง
.close แบบนี้ไฟล์ก็จะไม่ถูกปิด แต่หากใช้ with ต่อให้มีข้อผิดพลาดขึ้นมากลางคันไฟล์ก็จะถูกปิดแน่นอน ดังนั้นจึงปลอดภัยสบายใจกว่าจะเห็นว่าการเปิดไฟล์อ่านมีอยู่หลากหลายวิธี นอกจากที่กล่าวถึงไปนี้ก็ยังมีวิธีอื่นอีกด้วย เช่นใช้มอดูล
linecache เป็นต้นสรุปเนื้อหา
- การอ่านไฟล์ทำได้โดยการใช้คำสั่ง
open เพื่อสร้างออบเจ็กต์ที่แทนตัวไฟล์ขึ้นมา จากนั้นใช้เมธอดต่างๆเพื่อจัดการกับไฟล์ แล้วก็ลงท้ายด้วยเมธอด close เพื่อปิด- การเปิดไฟล์จำเป็นต้องกำหนดโหมดว่าจะอ่านหรือเขียน และควรระบุรูปแบบการเอนโค้ดตัวหนังสือ
- เมธอดที่ใช้อ่านดึงข้อมูลคือ
.read .readline .readlines หรืออาจใช้คำสั่ง for โดยไม่ใช้เมธอดก็ได้- ไฟล์จะถูกอ่านไล่ตั้งแต่ต้นจนจบ โดยมีการนับจำนวนตำแหน่งไปเรื่อยๆ
- เมธอด
.seek มีไว้ย้ายตำแหน่งที่อ่านไฟล์ไปยังจุดที่ต้องการ แต่ต้องระวังว่าหน่วยเป็นไบต์- สามารถใช้โครงสร้าง
with เพื่อจัดการกับไฟล์ได้ ซึ่งจะไม่ต้องใช้ .close เมื่อปิดไฟล์สำหรับการเขียนไฟล์จะพูดถึงในบทต่อไป
อ้างอิง
十七