pytorch เบื้องต้น บทที่ ๑๔: การใช้ GPU
เขียนเมื่อ 2018/09/22 15:13
แก้ไขล่าสุด 2022/07/09 19:02
>> ต่อจาก บทที่ ๑๓
การเรียนรู้ของโครงข่ายประสาทเทียม โดยเฉพาะแบบคอนโวลูชันนั้นกินเวลาค่อนข้างนาน ยิ่งถ้าจำนวนชั้นมากๆเข้า โดยทั่วไปแล้วจึงมักจะใช้ GPU ในการรันแทน CPU เพื่อเร่งความเร็ว GPU มีความสามารถในการคำนวณอะไรต่างๆเป็นแบบคู่ขนานเป็นอย่างดีจึงเหมาะกับงานนี้
การปรับโค้ดใน pytorch ให้ใช้ GPU แทนนั้นทำได้ไม่ยาก แค่แก้โค้ดบางส่วน เพียงแต่กรณีที่จะใช้ GPU มากกว่าหนึ่งตัวทำงานคู่ขนานกันไปความยุ่งยากจะเพิ่มอีกเล็กน้อย
ในที่นี้จะพูดถึงแค่วิธีการใช้ GPU แค่ตัวเดียว
การติดตั้ง
ถ้าจะใช้ GPU ตอนที่ลงโดยพิมพ์ตามในเว็บหลัก https://pytorch.org ให้เลือกว่าจะติดตั้ง CUDA ด้วย
หลังจากลงเสร็จอาจลองมาดูว่า GPU พร้อมใช้หรือเปล่าโดยพิมพ์
นอกจากนี้ cuDNN ซึ่งเป็นไลบรารีที่ถูกใช้เวลาคำนวณภายในโครงข่ายประสาทเทียมด้วย GPU ก็จะถูกติดตั้งด้วย ดูว่าพร้อมใช้หรือเปล่าได้
เทนเซอร์ใน GPU
ปกติถ้าเราสร้างเทนเซอร์ขึ้นมาแบบธรรมดาจะเป็นเทนเซอร์ใน CPU ใช้คำนวณได้ภายใน CPU เท่านั้น
แต่ถ้าต้องการคำนวณใน GPU จะต้องสร้างเทนเซอร์ใน GPU ซึ่งมีอยู่หลายวิธีด้วยกัน
อย่างแรกคือ ใช้คำสั่งสร้างเทนเซอร์ชนิดต่างๆแบบเดิมแต่เติม .cuda ไปข้างหน้า เช่น
เพียงแต่ว่าสำหรับ FloatTensor ให้ใช้ torch.cuda.FloatTensor ไม่ใช่ torch.cuda.Tensor
เทนเซอร์ที่ได้มาจะมีเขียนว่า device='cuda:0' ต่อท้ายเพื่อให้รู้ว่าข้อมูลเก็บอยู่ที่ GPU
อีกวิธีที่ง่ายกว่านั้นคือ สร้างเทนเซอร์แบบธรรมดาไป แล้วพิมพ์ .cuda() ต่อท้ายก็จะเปลี่ยนชนิดเป็นเทนเซอร์ใน GPU ได้ วิธีนี้ใช้ได้กับเทนเซอร์ทุกชนิด
เทนเซอร์ใน GPU ถ้าเติม .cpu() ต่อท้ายก็จะกลับมาเป็นเทนเซอร์ใน CPU เพียงแต่ว่าเทนเซอร์ที่อยู่ใน CPU อยู่แล้วก็เติมได้ แต่จะไม่เกิดอะไรขึ้น ส่วนเทนเซอร์ใน GPU ก็เติม .cuda() ต่อได้แต่ไม่เกิดอะไรขึ้นเหมือนกัน
เวลาใช้งานจริง เพื่อความสะดวกอาจทำการกำหนดตั้งแต่แรกว่าเราจะใช้ CPU หรือ GPU โดยสร้างตัวแปร device ขึ้นมา แล้วก็ใช้เมธอด to ที่ตัวเทนเซอร์
แบบนี้เท่ากับว่าแค่กำหนด device ครั้งเดียว แล้วเขียนแบบนี้ในทุกส่วนที่ทำอะไรที่ต้องแยกระหว่าง GPU กับ CPU ก็จะสับเปลี่ยนไปมาได้อย่างง่ายดาย
สำหรับออบเจ็กต์ Module ต่างๆ ถ้าใช้ .cuda() หรือ .to() ก็จะมีผลให้พารามิเตอร์ข้างในทั้งหมดย้ายไปอยู่ใน GPU
ได้
ข้อควรระวัง
หน่วยความจำของ GPU มักจะเล็ก ดังนั้นถ้าสร้างเทนเซอร์ขนาดใหญ่ความจำอาจไม่พอและ error
ดังนั้นเวลาใช้ GPU การบริหารหน่วยความจำจึงเป็นเรื่องจำเป็น ถ้าข้อมูลไหนใหญ่มากให้สร้างใน CPU แล้วค่อยๆส่งไปคำนวณใน GPU
บางครั้งตัวแปรที่สร้างใน GPU แม้ลบทิ้งไปแล้วก็ยังกินที่ GPU อยู่ อาจสั่งเคลียร์ทิ้งได้ด้วย empty_cache()
เพียงแต่ว่าปกติแล้วตัวแปรที่ไม่ถูกใช้จะโดนล้างทิ้งเมื่อจำเป็นต้องใช้พื้นที่ ดังนั้นจริงๆแล้วคำสั่งนี้ไม่จำเป็นนัก
อีกเรื่องที่ต้องระวังคือเทนเซอร์ใน GPU จะนำมาทำอะไรกับเทนเซอร์ใน CPU ไม่ได้ถ้าไม่แปลงกลับก่อน หรือจะแปลงเป็น numpy โดยตรงก็ไม่ได้ ต้องส่งมาทาง CPU ก่อน
การสร้างแบบจำลองโครงข่ายประสาทเทียมที่ใช้ GPU ได้
กรณีที่ใช้ GPU แค่ตัวเดียว สิ่งที่ต้องเพิ่มขึ้นมาในโค้ดเมื่อเทียบกับตอนไม่ใช้ ก็มีแค่เพิ่ม .to(dev) เข้ามาในส่วนที่ต้องการคำนวณเท่านั้น
ตัวอย่าง ลองสร้างโครงข่ายแบบเพอร์เซปตรอนสองชั้นง่ายๆขึ้นมาเพื่อแก้ปัญหาจำแนกประเภท
ตรง dev = torch.device('cuda') ถ้าแก้เป็น dev = torch.device('cpu') ก็จะเป็นการรันใน CPU ลองเทียบความเร็วกันดูได้
ต่อไปเป็นตัวอย่างการสร้างโครงข่ายประสาทแบบคอนโวลูชันคล้ายกับในบทที่ ๑๒ แต่ปรับให้ใช้ GPU ได้
ข้อแตกต่างที่สำคัญคือ ในการคำนวณคะแนนด้วยข้อมูลตรวจสอบในแต่ละขั้นก็ใช้วิธีมินิแบตช์เพื่อแบ่งก้อนคำนวณด้วย เนื่องจากหน่วยความจำของ GPU มีจำกัด หากคำนวณทั้งหมดทีเดียวก็จะเจอปัญหาเรื่องหน่วยความจำไม่พอได้
คราวนี้ลองมาใช้กับข้อมูลCIFAR10 ดู ข้อมูลชุดนี้ไม่ได้ง่ายเหมือนอย่างของ MNIST เพราะเป็นภาพถ่ายที่มีทั้งสิ่งของและฉากหลังปนกันมีความหลากหลายสูงมาก ดังนั้นจึงต้องใช้โครงข่ายที่ค่อนข้างซับซ้อนกว่าในการวิเคราะห์ จึงทำให้ต้องใช้เวลามาก จึงควรใช้ GPU
โหลดข้อมูล CIFAR10 โดยให้มีการสุ่มกลับด้านซ้ายขวาของภาพด้วย แล้วสร้างโครงข่าย ๗ ชั้น ประกอบด้วย Conv ๔ ชั้น และ Linear ๓ ชั้น
เมื่อใช้ GPU จะประหยัดเวลาได้มาก โดยทั่วไปจะเร็วกว่า CPU พอสมควร และยิ่ง GPU ดีมากก็ยิ่งเร็ว
สุดท้ายได้ผลออกมาแบบนี้
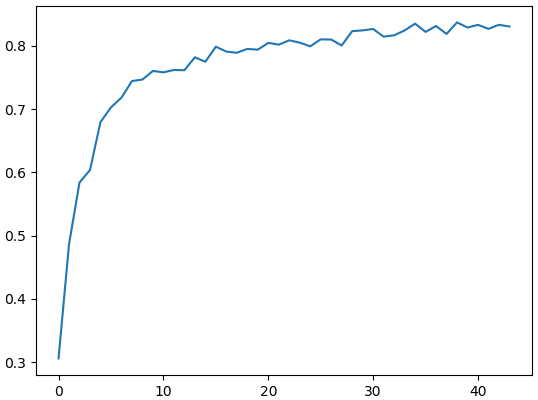
ความแม่นสูงสุดอยู่ที่ 83% ซึ่งอาจดูเหมือนว่าจะไม่มาก แต่สำหรับข้อมูล CIFAR10 ทำได้เกิน 80% แบบนี้ก็ถือว่าใช้ได้แล้ว
การเรียนรู้ของโครงข่ายประสาทเทียม โดยเฉพาะแบบคอนโวลูชันนั้นกินเวลาค่อนข้างนาน ยิ่งถ้าจำนวนชั้นมากๆเข้า โดยทั่วไปแล้วจึงมักจะใช้ GPU ในการรันแทน CPU เพื่อเร่งความเร็ว GPU มีความสามารถในการคำนวณอะไรต่างๆเป็นแบบคู่ขนานเป็นอย่างดีจึงเหมาะกับงานนี้
การปรับโค้ดใน pytorch ให้ใช้ GPU แทนนั้นทำได้ไม่ยาก แค่แก้โค้ดบางส่วน เพียงแต่กรณีที่จะใช้ GPU มากกว่าหนึ่งตัวทำงานคู่ขนานกันไปความยุ่งยากจะเพิ่มอีกเล็กน้อย
ในที่นี้จะพูดถึงแค่วิธีการใช้ GPU แค่ตัวเดียว
การติดตั้ง
ถ้าจะใช้ GPU ตอนที่ลงโดยพิมพ์ตามในเว็บหลัก https://pytorch.org ให้เลือกว่าจะติดตั้ง CUDA ด้วย
หลังจากลงเสร็จอาจลองมาดูว่า GPU พร้อมใช้หรือเปล่าโดยพิมพ์
print(torch.cuda.is_available()) # ได้ Trueนอกจากนี้ cuDNN ซึ่งเป็นไลบรารีที่ถูกใช้เวลาคำนวณภายในโครงข่ายประสาทเทียมด้วย GPU ก็จะถูกติดตั้งด้วย ดูว่าพร้อมใช้หรือเปล่าได้
torch.backends.cudnn.is_available() # ได้ Trueเทนเซอร์ใน GPU
ปกติถ้าเราสร้างเทนเซอร์ขึ้นมาแบบธรรมดาจะเป็นเทนเซอร์ใน CPU ใช้คำนวณได้ภายใน CPU เท่านั้น
แต่ถ้าต้องการคำนวณใน GPU จะต้องสร้างเทนเซอร์ใน GPU ซึ่งมีอยู่หลายวิธีด้วยกัน
อย่างแรกคือ ใช้คำสั่งสร้างเทนเซอร์ชนิดต่างๆแบบเดิมแต่เติม .cuda ไปข้างหน้า เช่น
t = torch.cuda.LongTensor([1])
print(t) # ได้ tensor([1], device='cuda:0')เพียงแต่ว่าสำหรับ FloatTensor ให้ใช้ torch.cuda.FloatTensor ไม่ใช่ torch.cuda.Tensor
เทนเซอร์ที่ได้มาจะมีเขียนว่า device='cuda:0' ต่อท้ายเพื่อให้รู้ว่าข้อมูลเก็บอยู่ที่ GPU
อีกวิธีที่ง่ายกว่านั้นคือ สร้างเทนเซอร์แบบธรรมดาไป แล้วพิมพ์ .cuda() ต่อท้ายก็จะเปลี่ยนชนิดเป็นเทนเซอร์ใน GPU ได้ วิธีนี้ใช้ได้กับเทนเซอร์ทุกชนิด
t = torch.randn(3)
print(t) # ได้ tensor([ 0.9278, -0.4722, -0.7108])
print(t.cuda()) # ได้ tensor([ 0.9278, -0.4722, -0.7108], device='cuda:0')เทนเซอร์ใน GPU ถ้าเติม .cpu() ต่อท้ายก็จะกลับมาเป็นเทนเซอร์ใน CPU เพียงแต่ว่าเทนเซอร์ที่อยู่ใน CPU อยู่แล้วก็เติมได้ แต่จะไม่เกิดอะไรขึ้น ส่วนเทนเซอร์ใน GPU ก็เติม .cuda() ต่อได้แต่ไม่เกิดอะไรขึ้นเหมือนกัน
print(t.cuda().cpu()) # ได้ tensor([ 0.9278, -0.4722, -0.7108])
print(t.cpu()) # ได้ tensor([ 0.9278, -0.4722, -0.7108])
print(t.cuda().cuda()) # ได้ tensor([ 0.9278, -0.4722, -0.7108], device='cuda:0')เวลาใช้งานจริง เพื่อความสะดวกอาจทำการกำหนดตั้งแต่แรกว่าเราจะใช้ CPU หรือ GPU โดยสร้างตัวแปร device ขึ้นมา แล้วก็ใช้เมธอด to ที่ตัวเทนเซอร์
t = torch.rand(4)
dev = torch.device('cuda')
print(t.to(dev)) # tensor([0.1237, 0.5063, 0.2424, 0.6088], device='cuda:0')
dev = torch.device('cpu')
print(t.to(dev)) # tensor([0.1237, 0.5063, 0.2424, 0.6088])แบบนี้เท่ากับว่าแค่กำหนด device ครั้งเดียว แล้วเขียนแบบนี้ในทุกส่วนที่ทำอะไรที่ต้องแยกระหว่าง GPU กับ CPU ก็จะสับเปลี่ยนไปมาได้อย่างง่ายดาย
สำหรับออบเจ็กต์ Module ต่างๆ ถ้าใช้ .cuda() หรือ .to() ก็จะมีผลให้พารามิเตอร์ข้างในทั้งหมดย้ายไปอยู่ใน GPU
lin = torch.nn.Linear(3,2)
lin.cuda()
print(lin.weight)ได้
Parameter containing:
tensor([[ 0.0067, -0.5206, 0.4279],
[-0.5000, 0.1692, 0.2832]], device='cuda:0', requires_grad=True)ข้อควรระวัง
หน่วยความจำของ GPU มักจะเล็ก ดังนั้นถ้าสร้างเทนเซอร์ขนาดใหญ่ความจำอาจไม่พอและ error
t = torch.randn([10000,50000]).cuda() # RuntimeError: CUDA error: out of memoryดังนั้นเวลาใช้ GPU การบริหารหน่วยความจำจึงเป็นเรื่องจำเป็น ถ้าข้อมูลไหนใหญ่มากให้สร้างใน CPU แล้วค่อยๆส่งไปคำนวณใน GPU
บางครั้งตัวแปรที่สร้างใน GPU แม้ลบทิ้งไปแล้วก็ยังกินที่ GPU อยู่ อาจสั่งเคลียร์ทิ้งได้ด้วย empty_cache()
t = torch.randn([10000,20000]).cuda()
t = t.cpu() # หรือแค่พิมพ์ del t ลบทิ้ง
torch.cuda.empty_cache()เพียงแต่ว่าปกติแล้วตัวแปรที่ไม่ถูกใช้จะโดนล้างทิ้งเมื่อจำเป็นต้องใช้พื้นที่ ดังนั้นจริงๆแล้วคำสั่งนี้ไม่จำเป็นนัก
อีกเรื่องที่ต้องระวังคือเทนเซอร์ใน GPU จะนำมาทำอะไรกับเทนเซอร์ใน CPU ไม่ได้ถ้าไม่แปลงกลับก่อน หรือจะแปลงเป็น numpy โดยตรงก็ไม่ได้ ต้องส่งมาทาง CPU ก่อน
torch.Tensor([1])+torch.Tensor([2]).cuda() # RuntimeError
torch.cuda.LongTensor([2]).numpy() # RuntimeErrorการสร้างแบบจำลองโครงข่ายประสาทเทียมที่ใช้ GPU ได้
กรณีที่ใช้ GPU แค่ตัวเดียว สิ่งที่ต้องเพิ่มขึ้นมาในโค้ดเมื่อเทียบกับตอนไม่ใช้ ก็มีแค่เพิ่ม .to(dev) เข้ามาในส่วนที่ต้องการคำนวณเท่านั้น
ตัวอย่าง ลองสร้างโครงข่ายแบบเพอร์เซปตรอนสองชั้นง่ายๆขึ้นมาเพื่อแก้ปัญหาจำแนกประเภท
import numpy as np
import matplotlib.pyplot as plt
import torch
import time
dev = torch.device('cuda')
relu = torch.nn.ReLU()
ha_entropy = torch.nn.CrossEntropyLoss()
khrongkhai = torch.nn.Sequential(
torch.nn.Linear(2,64),
relu,
torch.nn.Linear(64,5))
khrongkhai.to(dev)
x = np.random.uniform(0,12,20000)
y = np.random.uniform(0,4,20000)
X = np.array([x,y]).T
z = (y+np.sin(x)).astype(int)
plt.scatter(x,y,c=z,edgecolor='k',cmap='rainbow',alpha=0.05)
plt.figure()
opt = torch.optim.Adam(khrongkhai.parameters(),lr=0.002)
lis_khanaen = []
X = torch.Tensor(X).to(dev)
z = torch.LongTensor(z).to(dev)
t_roem = time.time()
for o in range(10000):
a = khrongkhai(X)
J = ha_entropy(a,z)
J.backward()
opt.step()
opt.zero_grad()
khanaen = (a.argmax(1)==z).cpu().numpy().mean()
lis_khanaen.append(khanaen)
if(o%500==499):
print('%d ครั้งผ่านไป ใช้เวลาไป %.1f วินาที ทำนายแม่น %.4f'%(o+1,time.time()-t_roem,khanaen))
plt.plot(lis_khanaen)
plt.show()ตรง dev = torch.device('cuda') ถ้าแก้เป็น dev = torch.device('cpu') ก็จะเป็นการรันใน CPU ลองเทียบความเร็วกันดูได้
ต่อไปเป็นตัวอย่างการสร้างโครงข่ายประสาทแบบคอนโวลูชันคล้ายกับในบทที่ ๑๒ แต่ปรับให้ใช้ GPU ได้
from torch.utils.data import DataLoader as Dalo
import torchvision.datasets as ds
import torchvision.transforms as tf
relu = torch.nn.ReLU()
ha_entropy = torch.nn.CrossEntropyLoss()
class Plianrup(torch.nn.Module):
def __init__(self,*k):
super(Plianrup,self).__init__()
self.k = k
def forward(self,x):
return x.reshape(x.size()[0],*self.k)
class Prasat(torch.nn.Sequential):
def __init__(self,kwang,m_cnn,m_lin,eta=0.001,dropout=0,bn=0,gpu=0):
super(Prasat,self).__init__()
'''
kwang: ความกว้างของภาพ
m_cnn:
m[0]: จำนวนขาเข้า
m[1]: จำนวนขาออก
m[2]: ขนาดตัวกรอง
m[3]: stride
m[4]: pad
m[5]: ขนาด maxpool
m_lin: ขนาดขาออกของชั้นเชิงเส้นแต่ละชั้น
eta: อัตราการเรียนรู้
dropout: อัตราดรอปเอาต์ในแต่ละชั้น
bn: แทรกแบตช์นอร์มระหว่างแต่ละชั้นหรือไม่
'''
for i,m in enumerate(m_cnn,1):
kwang = np.floor((kwang-m[2]+m[4]*2.)/m[3])+1
c = torch.nn.Conv2d(m[0],m[1],m[2],m[3],m[4])
torch.nn.init.kaiming_normal_(c.weight)
c.bias.data.fill_(0)
self.add_module('c%d'%i,c)
self.add_module('relu_c%d'%i,relu)
if(bn):
self.add_module('bano_c%d'%i,torch.nn.BatchNorm2d(m[1]))
if(m[5]>1):
self.add_module('maxp_c%d'%i,torch.nn.MaxPool2d(m[5]))
kwang = np.floor(kwang/m[5])
if(dropout):
self.add_module('droa_c%d'%i,torch.nn.Dropout(dropout))
self.add_module('o',Plianrup(-1))
m_lin = [int(kwang)**2*m_cnn[-1][1]]+m_lin
nm = len(m_lin)
for i in range(1,nm):
c = torch.nn.Linear(m_lin[i-1],m_lin[i])
torch.nn.init.kaiming_normal_(c.weight)
c.bias.data.fill_(0)
self.add_module('l%d'%i,c)
if(i<nm-1):
if(bn):
self.add_module('bano_l%d'%i,torch.nn.BatchNorm1d(m_lin[i]))
if(dropout):
self.add_module('droa_l%d'%i,torch.nn.Dropout(dropout))
self.add_module('relu_l%d'%i,relu)
# กำหนดว่าจะใช้ GPU หรือ CPU
if(gpu):
self.dev = torch.device('cuda')
self.cuda()
else:
self.dev = torch.device('cpu')
self.opt = torch.optim.Adam(self.parameters(),lr=eta)
def rianru(self,rup_fuek,rup_truat,n_thamsam=500,n_batch=64,n_batch_truat=512,ro=10):
self.khanaen = []
khanaen_sungsut = 0
t_roem = time.time()
for o in range(n_thamsam):
self.train()
for Xb,zb in rup_fuek:
a = self(Xb.to(self.dev))
J = ha_entropy(a,zb.to(self.dev))
J.backward()
self.opt.step()
self.opt.zero_grad()
self.eval()
khanaen = []
for Xb,zb in rup_truat:
khanaen.append(self.thamnai_(Xb.to(self.dev)).cpu()==zb)
khanaen = torch.cat(khanaen).numpy().mean()
self.khanaen.append(khanaen)
print('%d ครั้งผ่านไป ใช้เวลาไป %.1f นาที ทำนายแม่น %.4f'%(o+1,(time.time()-t_roem)/60,khanaen))
if(khanaen>khanaen_sungsut):
khanaen_sungsut = khanaen
maiphoem = 0
else:
maiphoem += 1
if(ro>0 and maiphoem>=ro):
break
def thamnai_(self,X):
return self(X).argmax(1)ข้อแตกต่างที่สำคัญคือ ในการคำนวณคะแนนด้วยข้อมูลตรวจสอบในแต่ละขั้นก็ใช้วิธีมินิแบตช์เพื่อแบ่งก้อนคำนวณด้วย เนื่องจากหน่วยความจำของ GPU มีจำกัด หากคำนวณทั้งหมดทีเดียวก็จะเจอปัญหาเรื่องหน่วยความจำไม่พอได้
คราวนี้ลองมาใช้กับข้อมูลCIFAR10 ดู ข้อมูลชุดนี้ไม่ได้ง่ายเหมือนอย่างของ MNIST เพราะเป็นภาพถ่ายที่มีทั้งสิ่งของและฉากหลังปนกันมีความหลากหลายสูงมาก ดังนั้นจึงต้องใช้โครงข่ายที่ค่อนข้างซับซ้อนกว่าในการวิเคราะห์ จึงทำให้ต้องใช้เวลามาก จึงควรใช้ GPU
โหลดข้อมูล CIFAR10 โดยให้มีการสุ่มกลับด้านซ้ายขวาของภาพด้วย แล้วสร้างโครงข่าย ๗ ชั้น ประกอบด้วย Conv ๔ ชั้น และ Linear ๓ ชั้น
folder_cifar10 = 'pytorchdata/cifar'
tran = tf.Compose([
tf.RandomHorizontalFlip(),
tf.ToTensor(),
tf.Normalize((0.5,0.5,0.5),(0.5,0.5,0.5))])
rup_fuek = ds.CIFAR10(folder_cifar10,transform=tran,train=1,download=1)
rup_fuek = Dalo(rup_fuek,batch_size=32,shuffle=True)
tran = tf.Compose([
tf.ToTensor(),
tf.Normalize((0.5,0.5,0.5),(0.5,0.5,0.5))])
rup_truat = ds.CIFAR10(folder_cifar10,transform=tran,train=0)
rup_truat = Dalo(rup_truat,batch_size=32)
m_cnn = [
[3,64,3,1,1,2],
[64,128,3,1,1,2],
[128,256,3,1,1,2],
[256,512,3,1,1,2],
]
m_lin = [512,64,10]
prasat = Prasat(32,m_cnn,m_lin,eta=0.001,dropout=0.5,bn=1,gpu=1)
prasat.rianru(rup_fuek,rup_truat,ro=5)
plt.plot(prasat.khanaen)
plt.show()เมื่อใช้ GPU จะประหยัดเวลาได้มาก โดยทั่วไปจะเร็วกว่า CPU พอสมควร และยิ่ง GPU ดีมากก็ยิ่งเร็ว
สุดท้ายได้ผลออกมาแบบนี้
ความแม่นสูงสุดอยู่ที่ 83% ซึ่งอาจดูเหมือนว่าจะไม่มาก แต่สำหรับข้อมูล CIFAR10 ทำได้เกิน 80% แบบนี้ก็ถือว่าใช้ได้แล้ว
-----------------------------------------
囧囧囧囧囧囧囧囧囧囧囧囧囧囧囧囧囧囧囧囧囧囧囧囧囧
หมวดหมู่
-- คอมพิวเตอร์ >> ปัญญาประดิษฐ์ >> โครงข่ายประสาทเทียม-- คอมพิวเตอร์ >> เขียนโปรแกรม >> python >> pytorch