จัดการข้อมูลด้วย pandas เบื้องต้น บทที่ ๗: การจัดเรียงข้อมูล
เขียนเมื่อ 2016/09/25 14:10
แก้ไขล่าสุด 2021/09/28 16:42
ข้อมูลภายในซีรีส์หรือเดตาเฟรมจะมีลำดับตายตัวซึ่งสามารถกำหนดขึ้นมาได้ตั้งแต่ตอนที่สร้างขึ้น แต่ว่าหลังสร้างขึ้นมาแล้วก็สามารถที่จะเรียงลำดับใหม่ได้
ตอนที่สร้างซีรีส์หรือเดตาเฟรมขึ้นมาหากสร้างขึ้นจากลิสต์ลำดับของดัชนีก็จะเป็นไปตามนั้น แต่หากสร้างขึ้นจากดิกชันนารี ข้อมูลจะถูกเรียงใหม่ตามใจชอบ ดังนั้นจึงต้องมาทำการเรียงใหม่เองอีกที
การเรียงใหม่ตามลำดับที่ต้องการ
วิธีที่ง่ายที่สุดในการเรียงข้อมูลใหม่นั้นไม่จำเป็นต้องใช้เมธอดอะไรเลย แค่ใช้ลิสต์ของชื่อแถวที่ต้องการมาเป็นดัชนีเท่านั้น
โดยกรณีที่จะเรียงคอลัมน์ใหม่ก็ใส่ดัชนีไปโดยตรง
ตัวอย่าง สร้างตารางข้อมูลโปเกมอน
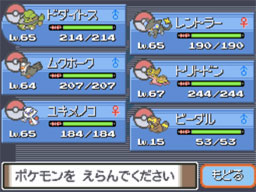
ได้
จัดเรียงคอลัมน์ใหม่
ได้
แต่ถ้าจะเรียงแถวใหม่ให้ใส่ .loc
ได้





แต่ก็มีเมธอดที่ใช้เพื่อเรียงโดยเฉพาะ นั่นคือ reindex เป็นเมธอดสำหรับจัดเรียงแถวหรือคอลัมน์ใหม่
โดยถ้าจะเรียงแถวใหม่ให้ใส่ลิสต์ของดัชนีของแถวที่เรียงลำดับตามที่ต้องการ เช่นเขียนแบบนี้
ก็จะได้ผลเหมือนตัวอย่างข้างต้น
แต่กรณีที่จะเรียงคอลัมน์ใหม่ให้ใส่ลิสต์ของคอลัมน์ที่เรียงไว้เป็นอาร์กิวเมนต์ตัวที่ ๒ แล้วตัวแรกอาจใส่ None ไปถ้าไม่ได้ต้องการเรียงแถวด้วย
เช่นตัวอย่างข้างต้นที่เรียงคอลัมน์ใหม่อาจเขียนใหม่เป็น
หรืออาจใส่ในลิสต์ของคอลัมน์รูปของคีย์เวิร์ดก็ได้ โดยเขียนเป็น
ผลที่ได้ก็เหมือนเดิม แต่น่าจะดูแล้วเข้าใจง่ายกว่า
ส่วนการเรียงแถวจะเขียน index= ไปด้วยเป็น
แบบนี้ก็ได้ แม้ว่าจะไม่จำเป็น
ไม่ว่าจะใช้ reindex หรือใส่ [] ไปโดยตรงก็ตาม ไม่จำเป็นต้องใส่สมาชิกให้ครบทุกตัว แต่ถ้าตัวไหนไม่ใส่ก็จะเป็นการตัดตัวนั้นทิ้งไปเหลือแค่ตัวที่ใส่
การใช้ reindex มีข้อดีมากกว่าคือสามารถใส่คีย์เวิร์ดเพิ่มเติมเพื่อปรับแต่งอะไรได้ยืดหยุ่นกว่า
ยกตัวอย่างเช่นกรณีที่ดัชนีที่ใส่ไปนั้นไม่มีอยู่
ได้


จะเห็นว่าแถวที่ไม่มีข้อมูลจะเป็น NaN ทั้งแถบ กรณีนี้จะใช้ reindex ก็ให้ผลเหมือนกัน แต่ reindex สามารถใส่คีย์เวิร์ด fill_value ลงไปเพื่อเติมค่าที่ไม่มีได้
ตัวอย่าง
ได้
การจัดเรียงตามค่า
หากต้องการจัดเรียงข้อมูลตามค่าของข้อมูลในตารางสามารถทำได้โดยใช้เมธอด sort_values
เมธอดนี้ใช้ได้ทั้งกับซีรีส์และกับเดตาเฟรม แต่ต่างกันตรงที่ว่าถ้าใช้กับซีรีส์จะไม่ต้องใส่อาร์กิวเมนต์ใดๆเพราะมีคอลัมน์เดียวอยู่แล้วเป็นการเรียงค่าตามคอลัมน์นั้น
แต่ถ้าเป็นเดตาเฟรมจะมีหลายคอลัมน์ ดังนั้นต้องใส่ชื่อคอลัมน์เพื่อระบุว่าจะเรียงตามคอลัมน์ไหน โดยอาจจะใส่หลายคอลัมน์ก็ได้ โดยจะเรียงตามอันแรกก่อน ถ้าเหมือนกันค่อยเทียบอันถัดมา
ตัวอย่าง ข้อมูลท่าชนิดน้ำของโปเกมอน
ได้
เรียงตามพลังโจมตีและความแม่นยำ
ได้
กรณีที่ใส่ชื่อคอลัมน์เพียงอันเดียวจะไม่ต้องใส่เป็นลิสต์ก็ได้เช่นหากเรียงแค่ตามพลังโจมตีก็เขียนเป็น pokemon.sort_values('พลังโจมตี')
สำหรับข้อมูลที่เป็น NaN ปกติจะถูกเรียงไว้ท้าย แต่ถ้าอยากให้เรียงไว้ต้นแทนก็ใส่เพิ่มคีย์เวิร์ด na_position='first' เช่น
ได้
สำหรับลำดับการเรียงนั้นโดยทั่วไปแล้วจะเรียงค่าจากน้อยไปมาก แต่ถ้าต้องการเรียงจากมากไปน้อยให้เพิ่มคีย์เวิร์ด ascending ไป โดยใส่ค่าเป็น 0 จะหมายถึงเรียงจากมากมาน้อย กรณีที่ใส่ชื่อคอลัมน์ที่จะเรียงมากกว่าหนึ่งอันค่า ascending ก็ต้องใส่เป็นลิสต์ที่มีจำนวนตามนั้นด้วย เช่น
ได้
แบบนี้จะเห็นว่าพลังโจมตีจะเรียงจากมากไปน้อย แต่ความแม่นยำจะยังเรียงจากน้อยไปมาก
ตัวอย่างที่ผ่านมาเป็นการเรียงตามข้อมูลในคอลัมน์ธรรมดา แต่หากต้องการให้เรียงตามดัชนีของแถวให้ใช้ sort_index
ได้
ทั้ง sort_values และ sort_index จะทำการสร้างเดตาเฟรมใหม่โดยไม่ทับตัวเก่า หากต้องการให้ทับตัวเก่าก็อาจใส่คีย์เวิร์ด inplace=True
อ้างอิง
ตอนที่สร้างซีรีส์หรือเดตาเฟรมขึ้นมาหากสร้างขึ้นจากลิสต์ลำดับของดัชนีก็จะเป็นไปตามนั้น แต่หากสร้างขึ้นจากดิกชันนารี ข้อมูลจะถูกเรียงใหม่ตามใจชอบ ดังนั้นจึงต้องมาทำการเรียงใหม่เองอีกที
การเรียงใหม่ตามลำดับที่ต้องการ
วิธีที่ง่ายที่สุดในการเรียงข้อมูลใหม่นั้นไม่จำเป็นต้องใช้เมธอดอะไรเลย แค่ใช้ลิสต์ของชื่อแถวที่ต้องการมาเป็นดัชนีเท่านั้น
โดยกรณีที่จะเรียงคอลัมน์ใหม่ก็ใส่ดัชนีไปโดยตรง
ตัวอย่าง สร้างตารางข้อมูลโปเกมอน
import pandas as pd
pokemon = pd.DataFrame([
[65,170,169],
[65,206,117],
[64,198,111],
[67,135,132],
[65,140,126],
[15,33,26]],
columns=['เลเวล','พลังโจมตี','พลังป้องกัน'],
index=['โดไดโทส','เรินโทราร์','มุกุฮอว์ก','ทริโทดอน','ยุกิเมะโนะโกะ','บีดารุ'])
print(pokemon)
pokemon = pd.DataFrame([
[65,170,169],
[65,206,117],
[64,198,111],
[67,135,132],
[65,140,126],
[15,33,26]],
columns=['เลเวล','พลังโจมตี','พลังป้องกัน'],
index=['โดไดโทส','เรินโทราร์','มุกุฮอว์ก','ทริโทดอน','ยุกิเมะโนะโกะ','บีดารุ'])
print(pokemon)
ได้
| เลเวล | พลังโจมตี | พลังป้องกัน | |
|---|---|---|---|
| โดไดโทส | 65 | 170 | 169 |
| เรินโทราร์ | 65 | 206 | 117 |
| มุกุฮอว์ก | 64 | 198 | 111 |
| ทริโทดอน | 67 | 135 | 132 |
| ยุกิเมะโนะโกะ | 65 | 140 | 126 |
| บีดารุ | 15 | 33 | 26 |
จัดเรียงคอลัมน์ใหม่
print(pokemon[['พลังโจมตี','พลังป้องกัน','เลเวล']])
ได้
| พลังโจมตี | พลังป้องกัน | เลเวล | |
|---|---|---|---|
| โดไดโทส | 170 | 169 | 65 |
| เรินโทราร์ | 206 | 117 | 65 |
| มุกุฮอว์ก | 198 | 111 | 64 |
| ทริโทดอน | 135 | 132 | 67 |
| ยุกิเมะโนะโกะ | 140 | 126 | 65 |
| บีดารุ | 33 | 26 | 15 |
แต่ถ้าจะเรียงแถวใหม่ให้ใส่ .loc
print(pokemon.loc[['ยุกิเมะโนะโกะ','มุกุฮอว์ก','ทริโทดอน','เรินโทราร์','บีดารุ','โดไดโทส']])
ได้
| เลเวล | พลังโจมตี | พลังป้องกัน | |
|---|---|---|---|
| ยุกิเมะโนะโกะ | 65 | 140 | 126 |
| มุกุฮอว์ก | 64 | 198 | 111 |
| ทริโทดอน | 67 | 135 | 132 |
| เรินโทราร์ | 65 | 206 | 117 |
| บีดารุ | 15 | 33 | 26 |
| โดไดโทส | 65 | 170 | 169 |
แต่ก็มีเมธอดที่ใช้เพื่อเรียงโดยเฉพาะ นั่นคือ reindex เป็นเมธอดสำหรับจัดเรียงแถวหรือคอลัมน์ใหม่
โดยถ้าจะเรียงแถวใหม่ให้ใส่ลิสต์ของดัชนีของแถวที่เรียงลำดับตามที่ต้องการ เช่นเขียนแบบนี้
print(pokemon.reindex(['ยุกิเมะโนะโกะ','มุกุฮอว์ก','ทริโทดอน','เรินโทราร์','บีดารุ','โดไดโทส']))
ก็จะได้ผลเหมือนตัวอย่างข้างต้น
แต่กรณีที่จะเรียงคอลัมน์ใหม่ให้ใส่ลิสต์ของคอลัมน์ที่เรียงไว้เป็นอาร์กิวเมนต์ตัวที่ ๒ แล้วตัวแรกอาจใส่ None ไปถ้าไม่ได้ต้องการเรียงแถวด้วย
เช่นตัวอย่างข้างต้นที่เรียงคอลัมน์ใหม่อาจเขียนใหม่เป็น
print(pokemon.reindex(None,['พลังโจมตี','พลังป้องกัน','เลเวล']))
หรืออาจใส่ในลิสต์ของคอลัมน์รูปของคีย์เวิร์ดก็ได้ โดยเขียนเป็น
print(pokemon.reindex(columns=['พลังโจมตี','พลังป้องกัน','เลเวล']))
ผลที่ได้ก็เหมือนเดิม แต่น่าจะดูแล้วเข้าใจง่ายกว่า
ส่วนการเรียงแถวจะเขียน index= ไปด้วยเป็น
print(pokemon.reindex(index=['ยุกิเมะโนะโกะ','มุกุฮอว์ก','ทริโทดอน','เรินโทราร์','บีดารุ','โดไดโทส']))
แบบนี้ก็ได้ แม้ว่าจะไม่จำเป็น
ไม่ว่าจะใช้ reindex หรือใส่ [] ไปโดยตรงก็ตาม ไม่จำเป็นต้องใส่สมาชิกให้ครบทุกตัว แต่ถ้าตัวไหนไม่ใส่ก็จะเป็นการตัดตัวนั้นทิ้งไปเหลือแค่ตัวที่ใส่
การใช้ reindex มีข้อดีมากกว่าคือสามารถใส่คีย์เวิร์ดเพิ่มเติมเพื่อปรับแต่งอะไรได้ยืดหยุ่นกว่า
ยกตัวอย่างเช่นกรณีที่ดัชนีที่ใส่ไปนั้นไม่มีอยู่
print(pokemon.loc[['ทริโทดอน','เรินโทราร์','กิราทีนา','โดไดโทส']])
ได้
| เลเวล | พลังโจมตี | พลังป้องกัน | |
|---|---|---|---|
| ทริโทดอน | 67.0 | 135.0 | 132.0 |
| เรินโทราร์ | 65.0 | 206.0 | 117.0 |
| กิราทีนา | NaN | NaN | NaN |
| โดไดโทส | 65.0 | 170.0 | 169.0 |
จะเห็นว่าแถวที่ไม่มีข้อมูลจะเป็น NaN ทั้งแถบ กรณีนี้จะใช้ reindex ก็ให้ผลเหมือนกัน แต่ reindex สามารถใส่คีย์เวิร์ด fill_value ลงไปเพื่อเติมค่าที่ไม่มีได้
ตัวอย่าง
print(pokemon.reindex(['ทริโทดอน','เรินโทราร์','กิราทีนา','โดไดโทส'],fill_value=99))
ได้
| เลเวล | พลังโจมตี | พลังป้องกัน | |
|---|---|---|---|
| ทริโทดอน | 67 | 135 | 132 |
| เรินโทราร์ | 65 | 206 | 117 |
| กิราทีนา | 99 | 99 | 99 |
| โดไดโทส | 65 | 170 | 169 |
การจัดเรียงตามค่า
หากต้องการจัดเรียงข้อมูลตามค่าของข้อมูลในตารางสามารถทำได้โดยใช้เมธอด sort_values
เมธอดนี้ใช้ได้ทั้งกับซีรีส์และกับเดตาเฟรม แต่ต่างกันตรงที่ว่าถ้าใช้กับซีรีส์จะไม่ต้องใส่อาร์กิวเมนต์ใดๆเพราะมีคอลัมน์เดียวอยู่แล้วเป็นการเรียงค่าตามคอลัมน์นั้น
แต่ถ้าเป็นเดตาเฟรมจะมีหลายคอลัมน์ ดังนั้นต้องใส่ชื่อคอลัมน์เพื่อระบุว่าจะเรียงตามคอลัมน์ไหน โดยอาจจะใส่หลายคอลัมน์ก็ได้ โดยจะเรียงตามอันแรกก่อน ถ้าเหมือนกันค่อยเทียบอันถัดมา
ตัวอย่าง ข้อมูลท่าชนิดน้ำของโปเกมอน
import numpy as np
pokemon = pd.DataFrame([
[95,100,15],
[15,70,15],
[95,85,10],
[np.NaN,np.NaN,5],
[120,80,5],
[65,100,20]],
columns=['พลังโจมตี','ความแม่นยำ','PP'],
index=['โต้คลื่น','กระแสน้ำวน','สายน้ำโคลน','ขอฝน','ไฮโดรปัมป์','ลำแสงฟองสบู่'])
print(pokemon)
pokemon = pd.DataFrame([
[95,100,15],
[15,70,15],
[95,85,10],
[np.NaN,np.NaN,5],
[120,80,5],
[65,100,20]],
columns=['พลังโจมตี','ความแม่นยำ','PP'],
index=['โต้คลื่น','กระแสน้ำวน','สายน้ำโคลน','ขอฝน','ไฮโดรปัมป์','ลำแสงฟองสบู่'])
print(pokemon)
ได้
| พลังโจมตี | ความแม่นยำ | PP | |
|---|---|---|---|
| โต้คลื่น | 95.0 | 100.0 | 15 |
| กระแสน้ำวน | 15.0 | 70.0 | 15 |
| สายน้ำโคลน | 95.0 | 85.0 | 10 |
| ขอฝน | NaN | NaN | 5 |
| ไฮโดรปัมป์ | 120.0 | 80.0 | 5 |
| ลำแสงฟองสบู่ | 65.0 | 100.0 | 20 |
เรียงตามพลังโจมตีและความแม่นยำ
print(pokemon.sort_values(['พลังโจมตี','ความแม่นยำ']))
ได้
| พลังโจมตี | ความแม่นยำ | PP | |
|---|---|---|---|
| กระแสน้ำวน | 15.0 | 70.0 | 15 |
| ลำแสงฟองสบู่ | 65.0 | 100.0 | 20 |
| สายน้ำโคลน | 95.0 | 85.0 | 10 |
| โต้คลื่น | 95.0 | 100.0 | 15 |
| ไฮโดรปัมป์ | 120.0 | 80.0 | 5 |
| ขอฝน | NaN | NaN | 5 |
กรณีที่ใส่ชื่อคอลัมน์เพียงอันเดียวจะไม่ต้องใส่เป็นลิสต์ก็ได้เช่นหากเรียงแค่ตามพลังโจมตีก็เขียนเป็น pokemon.sort_values('พลังโจมตี')
สำหรับข้อมูลที่เป็น NaN ปกติจะถูกเรียงไว้ท้าย แต่ถ้าอยากให้เรียงไว้ต้นแทนก็ใส่เพิ่มคีย์เวิร์ด na_position='first' เช่น
print(pokemon.sort_values(['พลังโจมตี','ความแม่นยำ'],na_position='first'))
ได้
| พลังโจมตี | ความแม่นยำ | PP | |
|---|---|---|---|
| ขอฝน | NaN | NaN | 5 |
| กระแสน้ำวน | 15.0 | 70.0 | 15 |
| ลำแสงฟองสบู่ | 65.0 | 100.0 | 20 |
| สายน้ำโคลน | 95.0 | 85.0 | 10 |
| โต้คลื่น | 95.0 | 100.0 | 15 |
| ไฮโดรปัมป์ | 120.0 | 80.0 | 5 |
สำหรับลำดับการเรียงนั้นโดยทั่วไปแล้วจะเรียงค่าจากน้อยไปมาก แต่ถ้าต้องการเรียงจากมากไปน้อยให้เพิ่มคีย์เวิร์ด ascending ไป โดยใส่ค่าเป็น 0 จะหมายถึงเรียงจากมากมาน้อย กรณีที่ใส่ชื่อคอลัมน์ที่จะเรียงมากกว่าหนึ่งอันค่า ascending ก็ต้องใส่เป็นลิสต์ที่มีจำนวนตามนั้นด้วย เช่น
print(pokemon.sort_values(['พลังโจมตี','ความแม่นยำ'],ascending=[0,1]))
ได้
| พลังโจมตี | ความแม่นยำ | PP | |
|---|---|---|---|
| ไฮโดรปัมป์ | 120.0 | 80.0 | 5 |
| สายน้ำโคลน | 95.0 | 85.0 | 10 |
| โต้คลื่น | 95.0 | 100.0 | 15 |
| ลำแสงฟองสบู่ | 65.0 | 100.0 | 20 |
| กระแสน้ำวน | 15.0 | 70.0 | 15 |
| ขอฝน | NaN | NaN | 5 |
แบบนี้จะเห็นว่าพลังโจมตีจะเรียงจากมากไปน้อย แต่ความแม่นยำจะยังเรียงจากน้อยไปมาก
ตัวอย่างที่ผ่านมาเป็นการเรียงตามข้อมูลในคอลัมน์ธรรมดา แต่หากต้องการให้เรียงตามดัชนีของแถวให้ใช้ sort_index
print(pokemon.sort_index(ascending=0))
ได้
| พลังโจมตี | ความแม่นยำ | PP | |
|---|---|---|---|
| ไฮโดรปัมป์ | 120.0 | 80.0 | 5 |
| โต้คลื่น | 95.0 | 100.0 | 15 |
| สายน้ำโคลน | 95.0 | 85.0 | 10 |
| ลำแสงฟองสบู่ | 65.0 | 100.0 | 20 |
| ขอฝน | NaN | NaN | 5 |
| กระแสน้ำวน | 15.0 | 70.0 | 15 |
ทั้ง sort_values และ sort_index จะทำการสร้างเดตาเฟรมใหม่โดยไม่ทับตัวเก่า หากต้องการให้ทับตัวเก่าก็อาจใส่คีย์เวิร์ด inplace=True
อ้างอิง
http://ameblo.jp/hitochan007/entry-12000149850.html
http://qiita.com/hik0107/items/d991cc44c2d1778bb82e
http://ameblo.jp/hitochan007/entry-12003794147.html
http://sinhrks.hatenablog.com/entry/2014/11/15/230705
http://pythondatascience.plavox.info/pandas/データフレームをソートする
http://qiita.com/hik0107/items/d991cc44c2d1778bb82e
http://ameblo.jp/hitochan007/entry-12003794147.html
http://sinhrks.hatenablog.com/entry/2014/11/15/230705
http://pythondatascience.plavox.info/pandas/データフレームをソートする