[python] การคัดเลือกค่าแทนลักษณะโดยวิธีการคัดเลือกย้อนกลับหลังตามลำดับ
เขียนเมื่อ 2017/12/11 17:22
แก้ไขล่าสุด 2024/10/12 09:24
ในการวิเคราะห์ปัญหาด้วยแบบจำลองการเรียนรู้ของเครื่องนั้น สิ่งสำคัญอย่างหนึ่งที่ต้องเลือกว่าตัวแปรอะไรที่จะนำมาใช้พิจารณาปัญหา
ตัวแปรของปัญหาในที่นี้บางครั้งก็เรียกว่า ค่าแทนลักษณะ (特征, feature)
เริ่มแรกเราอาจจะพิจารณาปัจจัยตัวแปรต่างๆเต็มไปหมดซึ่งไม่รู้ว่ามันจะเชื่อมโยงไปถึงคำตอบที่เราต้องการได้หรือเปล่า แล้วพอพิจารณาปัญหาไปก็จะเริ่มรู้ขึ้นมาได้ว่าตัวแปรไหนสำคัญหรือไม่ ก็ตัดส่วนที่ไม่สำคัญทิ้งไป
จริงอยู่ว่าตัวแปรเยอะไว้ก่อนก็ดี แต่หากไปพิจารณาตัวแปรที่ไม่เกี่ยวข้องด้วยแล้วเผลอให้ความสำคัญกับมันมากเกินไปกลับจะทำให้เกิดการเรียนรู้เกิน (过学习, overlearning) ได้
อีกทั้งตัวแปรเยอะก็ใช้เวลาคำนวณนาน ดังนั้นการลดจำนวนตัวแปรลงจึงเป็นสิ่งจำเป็น
การคัดเลือกหยิบเอาแค่ตัวแปรบางส่วนมาจากกลุ่มตัวแปรที่พิจารณาในเริ่มแรกนั้นเรียกว่า การคัดเลือกค่าแทนลักษณะ (特征选择, feature selection)
วิธีการคัดเลือกค่าแทนลักษณะนั้นมีอยู่หลากหลายวิธีมากจนไม่อาจกล่าวถึงได้หมดง่ายๆ
อย่างเช่นวิธีหนึ่งคือไม่ต้องคิดอะไรมากให้ทดลองวิธีหยิบเลือกเอาค่าแทนลักษณะทุกวิถีทาง แล้วดูว่าเลือกเอาแบบไหนแล้วได้ผลออกมาดีที่สุด เช่น ถ้ามีตัวแปร a กับ b ก็อาจเลือก a เลือก b เลือกทั้ง a และ b มีวิธีเลือกอยู่ 3 แบบ ถ้ามี abc เป็น 3 ตัวแปรก็จะมีวิธีการเลือก 7 แบบ
หากใช้วิธีแบบนี้จำนวนรูปแบบที่เลือกได้จะเท่ากับ 2 ยกกำลังจำนวนค่าแทนลักษณะ 2n-1 ในทางปฏิบัติแล้วจึงไม่มีทางทำได้หากตัวแปรมีจำนวนมาก
วิธีที่สะดวกกว่านั้นที่สามารถคิดได้ก็คือให้ลองพิจารณาโดยเริ่มจากใช้ตัวแปรทั้งหมดที่มีก่อน จากนั้นก็ค่อยลองตัดตัวแปรไปสักตัวนึง แล้วดูว่าตัดตัวแปรไหนไปแล้วยังให้ผลดีที่สุดอยู่ ก็ให้ตัดตัวแปรนั้น
จากนั้นก็พิจาณาแบบเดิม คือลองตัดตัวแปรไปอีกตัวแล้วดูว่าตัดตัวไหนแล้วยังให้ผลดีสุดอยู่ ก็ทำการตัดตัวนั้นไปอีก
ทำอย่างนี้ไปเรื่อยๆ ตัดไปเรื่อยๆจนเหลือตัวแปรแค่ตัวเดียว สุดท้ายก็มาพิจารณาว่าตอนที่ใช้ตัวแปรกี่ตัวผลที่ได้ออกมาดูดีที่สุด
แบบนี้จำนวนครั้งที่คำนวณจะเท่ากับ (n-1)+(n-2)+...1 = n(n-1)/2 ถือว่าประหยัดแรงไปได้มาก
วิธีการแบบนี้มีชื่อเรียกว่า การคัดเลือกย้อนกลับหลังตามลำดับ (序列后向选择, sequential backward selection) หรือเรียกย่อๆว่า SBS
นอกจากนี้ยังมีวิธีการในลักษณะคล้ายๆกันแต่ตรงกันข้ามคือ การคัดเลือกไปข้างหน้าตามลำดับ (序列前向选择, sequential forward selection)
คือเริ่มไล่จากตัวแปรตัวเดียวก่อนแล้วค่อยไล่เพิ่มไปเรื่อยๆจนใช้ตัวแปรครบทั้งหมด
นอกจากนี้ยังมีอีกหลายวิธีที่สามารถคิดได้ เช่นการใช้ป่าสุ่ม ซึ่งได้แนะนำไปในบทความที่แล้ว โดยใช้ชุดข้อมูลไวน์เป็นตัวอย่าง https://phyblas.hinaboshi.com/20171207
สำหรับครั้งนี้ก็จะใช้ชุดข้อมูลไวน์อันเดิมนี้เป็นตัวอย่างอีก โดยจะทำโดยใช้วิธีการคัดเลือกย้อนกลับหลังตามลำดับ

แบบจำลองที่จะใช้วัดลองเลือกใช้วิธีการเพื่อนบ้านใกล้สุด k ตัว (รายละเอียด https://phyblas.hinaboshi.com/20171031)
ส่วนการให้คะแนนแบบจำลองก็จะใช้ cross_val_score (รายละเอียด https://phyblas.hinaboshi.com/20171020)
เพื่อความสะดวกในการหยิบตัวแปรในแต่ละรอบในที่นี้จะฟังก์ชัน combinations ใน itertools (รายละเอียด https://phyblas.hinaboshi.com/tsuchinoko28)
โค้ดเขียนได้ดังนี้
ได้
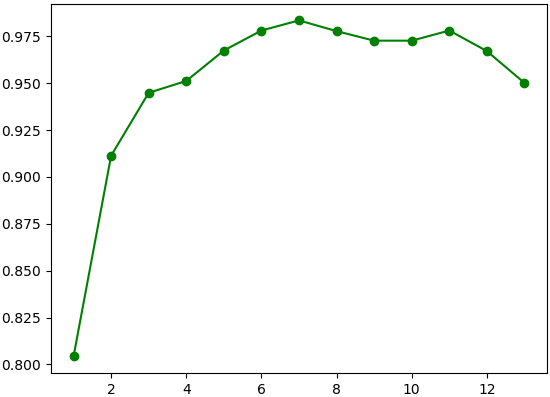
ตัวเลขที่พิมพ์ออกมาในแต่ละขั้นแสดงถึงว่าตัวแปรโดนคัดเหลือตัวไหนบ้างจนถึงผู้เหลือรอดสุดท้าย
และในกราฟพอลองเทียบผลของการใช้ตัวแปรที่เหลืออยู่ในจำนวนต่างๆจะเห็นว่าจะได้คะแนนสูงสุดเมื่อใช้ค่า ๗ ตัวดังที่พิมพ์ออกมาในบรรทัดสุดท้าย
ต่อมาลองทำให้อยู่ในรูปแบบของคลาสเพื่อให้สะดวกในการใช้งาน
วิธีการใช้จะเริ่มจากสร้างออบเจ็กต์ของคลาสขึ้นมา โดยกำหนดแบบจำลองที่จะใช้ทดสอบ จากนั้นจึงใช้เมธอด rianru() เพื่อป้อนข้อมูลเข้าไปให้ทำการเรียนรู้ประเมินคะแนน
ทดลองใช้ดู ทดสอบกับข้อมูลไวน์ชุดเดิม แต่คราวนี้จะลองใช้กับแบบจำลองการถดถอยโลจิสติก (รายละเอียด https://phyblas.hinaboshi.com/20171010)
จากนั้นคะแนนจะเก็บอยู่ใน .khanaen และในที่นี้ยังให้มีการเก็บส่วนเบี่ยงเบนมาตรฐานไว้ใน .std ลองเอามาวาดกราฟดูได้
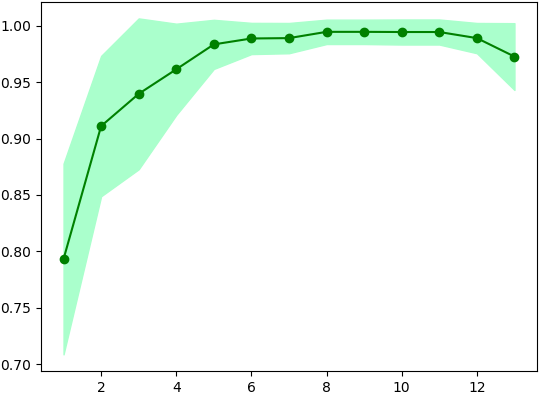
นอกจากนี้ยังได้มีการสร้างเมธอด .plaeng() เอาไว้สำหรับแปลงข้อมูลให้เหลือแค่ตัวแปรที่ถูกคัดไว้ว่าให้ผลดีที่สุด
เช่น ในที่นี้ใช้ตัวแปร 9 ตัวให้ผลดีสุด ดังนั้นหากลองทำการแปลงดูจะได้แบบนี้
แต่จะแปลงโดยระบุจำนวนตัวแปรที่ต้องการเหลือก็ได้
จะเห็นว่าวิธีการคัดเลือกย้อนกลับหลังตามลำดับนั้นสามารถเขียนได้ไม่ยากนัก
นอกจากนี้ใน sklearn ยังได้เตรียมวิธีการคัดเลือกค่าแทนลักษณะแบบอื่นๆไว้อีกมากมาย สามารถลองเลือกใช้ตามความเหมาะสมได้
อ้างอิง
ตัวแปรของปัญหาในที่นี้บางครั้งก็เรียกว่า ค่าแทนลักษณะ (特征, feature)
เริ่มแรกเราอาจจะพิจารณาปัจจัยตัวแปรต่างๆเต็มไปหมดซึ่งไม่รู้ว่ามันจะเชื่อมโยงไปถึงคำตอบที่เราต้องการได้หรือเปล่า แล้วพอพิจารณาปัญหาไปก็จะเริ่มรู้ขึ้นมาได้ว่าตัวแปรไหนสำคัญหรือไม่ ก็ตัดส่วนที่ไม่สำคัญทิ้งไป
จริงอยู่ว่าตัวแปรเยอะไว้ก่อนก็ดี แต่หากไปพิจารณาตัวแปรที่ไม่เกี่ยวข้องด้วยแล้วเผลอให้ความสำคัญกับมันมากเกินไปกลับจะทำให้เกิดการเรียนรู้เกิน (过学习, overlearning) ได้
อีกทั้งตัวแปรเยอะก็ใช้เวลาคำนวณนาน ดังนั้นการลดจำนวนตัวแปรลงจึงเป็นสิ่งจำเป็น
การคัดเลือกหยิบเอาแค่ตัวแปรบางส่วนมาจากกลุ่มตัวแปรที่พิจารณาในเริ่มแรกนั้นเรียกว่า การคัดเลือกค่าแทนลักษณะ (特征选择, feature selection)
วิธีการคัดเลือกค่าแทนลักษณะนั้นมีอยู่หลากหลายวิธีมากจนไม่อาจกล่าวถึงได้หมดง่ายๆ
อย่างเช่นวิธีหนึ่งคือไม่ต้องคิดอะไรมากให้ทดลองวิธีหยิบเลือกเอาค่าแทนลักษณะทุกวิถีทาง แล้วดูว่าเลือกเอาแบบไหนแล้วได้ผลออกมาดีที่สุด เช่น ถ้ามีตัวแปร a กับ b ก็อาจเลือก a เลือก b เลือกทั้ง a และ b มีวิธีเลือกอยู่ 3 แบบ ถ้ามี abc เป็น 3 ตัวแปรก็จะมีวิธีการเลือก 7 แบบ
หากใช้วิธีแบบนี้จำนวนรูปแบบที่เลือกได้จะเท่ากับ 2 ยกกำลังจำนวนค่าแทนลักษณะ 2n-1 ในทางปฏิบัติแล้วจึงไม่มีทางทำได้หากตัวแปรมีจำนวนมาก
วิธีที่สะดวกกว่านั้นที่สามารถคิดได้ก็คือให้ลองพิจารณาโดยเริ่มจากใช้ตัวแปรทั้งหมดที่มีก่อน จากนั้นก็ค่อยลองตัดตัวแปรไปสักตัวนึง แล้วดูว่าตัดตัวแปรไหนไปแล้วยังให้ผลดีที่สุดอยู่ ก็ให้ตัดตัวแปรนั้น
จากนั้นก็พิจาณาแบบเดิม คือลองตัดตัวแปรไปอีกตัวแล้วดูว่าตัดตัวไหนแล้วยังให้ผลดีสุดอยู่ ก็ทำการตัดตัวนั้นไปอีก
ทำอย่างนี้ไปเรื่อยๆ ตัดไปเรื่อยๆจนเหลือตัวแปรแค่ตัวเดียว สุดท้ายก็มาพิจารณาว่าตอนที่ใช้ตัวแปรกี่ตัวผลที่ได้ออกมาดูดีที่สุด
แบบนี้จำนวนครั้งที่คำนวณจะเท่ากับ (n-1)+(n-2)+...1 = n(n-1)/2 ถือว่าประหยัดแรงไปได้มาก
วิธีการแบบนี้มีชื่อเรียกว่า การคัดเลือกย้อนกลับหลังตามลำดับ (序列后向选择, sequential backward selection) หรือเรียกย่อๆว่า SBS
นอกจากนี้ยังมีวิธีการในลักษณะคล้ายๆกันแต่ตรงกันข้ามคือ การคัดเลือกไปข้างหน้าตามลำดับ (序列前向选择, sequential forward selection)
คือเริ่มไล่จากตัวแปรตัวเดียวก่อนแล้วค่อยไล่เพิ่มไปเรื่อยๆจนใช้ตัวแปรครบทั้งหมด
นอกจากนี้ยังมีอีกหลายวิธีที่สามารถคิดได้ เช่นการใช้ป่าสุ่ม ซึ่งได้แนะนำไปในบทความที่แล้ว โดยใช้ชุดข้อมูลไวน์เป็นตัวอย่าง https://phyblas.hinaboshi.com/20171207
สำหรับครั้งนี้ก็จะใช้ชุดข้อมูลไวน์อันเดิมนี้เป็นตัวอย่างอีก โดยจะทำโดยใช้วิธีการคัดเลือกย้อนกลับหลังตามลำดับ
แบบจำลองที่จะใช้วัดลองเลือกใช้วิธีการเพื่อนบ้านใกล้สุด k ตัว (รายละเอียด https://phyblas.hinaboshi.com/20171031)
ส่วนการให้คะแนนแบบจำลองก็จะใช้ cross_val_score (รายละเอียด https://phyblas.hinaboshi.com/20171020)
เพื่อความสะดวกในการหยิบตัวแปรในแต่ละรอบในที่นี้จะฟังก์ชัน combinations ใน itertools (รายละเอียด https://phyblas.hinaboshi.com/tsuchinoko28)
โค้ดเขียนได้ดังนี้
import numpy as np
import matplotlib.pyplot as plt
from sklearn.neighbors import KNeighborsClassifier as Knn
from sklearn import datasets
from sklearn.model_selection import cross_val_score as crovasco
from itertools import combinations as combi
wine = datasets.load_wine() # ดึงข้อมูลไวน์
X,z = wine.data,wine.target
X = (X-X.mean(0))/X.std(0) # ทำให้เป็นมาตรฐาน
model = Knn(9) # เพื่อนบ้านใกล้สุด 9 ตัว
n = X.shape[1] # จำนวนตัวแปร
ind = tuple(range(n)) # ดัชนีของตัวแปร ไล่จาก 0 จนถึง n-1
khanaen = []
index = []
# วนซ้ำโดยไล่จำนวนตัวแปร (k) จาก =n ไปจนถึง 1
for k in range(n,0,-1):
khanaen_disut = 0 # คะแนนดีสุดในแต่ละรอบ
ii_disut = 0 # รูปแบบการเลือกกลุ่มตัวแปรที่ดีที่สุด
# ใช้ combinations เพื่อหยิบตัวแปรจำนวน k ตัวจากตัวแปรที่เหลืออยู่ในแต่ละรอบ
for ii in combi(ind,k):
khanaen_ii = crovasco(model,X[:,ii],z,cv=5).mean() # หาคะแนนแล้วเฉลี่ย
# หากได้คะแนนสูงกว่าเดิมก็ให้เก็บค่า
if(khanaen_ii>khanaen_disut):
khanaen_disut = khanaen_ii
ii_disut = ii
ind = ii_disut # รูปแบบกลุ่มตัวแปรที่ดีที่สุดจะนำมาใช้เป็นกลุ่มตั้งต้นในรอบถัดไป
khanaen.append(khanaen_disut)
index.append(ind)
print(ind)
print([wine.feature_names[i] for i in index[np.array(khanaen).argmax()]])
plt.plot(range(n,0,-1),khanaen,'o-g')
plt.show()ได้
(0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12)
(0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 11, 12)
(0, 1, 2, 3, 4, 5, 6, 7, 9, 11, 12)
(0, 1, 2, 3, 4, 5, 6, 9, 11, 12)
(0, 1, 2, 3, 4, 6, 9, 11, 12)
(0, 1, 2, 3, 6, 9, 11, 12)
(0, 2, 3, 6, 9, 11, 12)
(0, 3, 6, 9, 11, 12)
(0, 6, 9, 11, 12)
(0, 6, 9, 12)
(6, 9, 12)
(6, 9)
(6,)
['alcohol', 'ash', 'alcalinity_of_ash', 'flavanoids', 'color_intensity', 'od280/od315_of_diluted_wines', 'proline']
ตัวเลขที่พิมพ์ออกมาในแต่ละขั้นแสดงถึงว่าตัวแปรโดนคัดเหลือตัวไหนบ้างจนถึงผู้เหลือรอดสุดท้าย
และในกราฟพอลองเทียบผลของการใช้ตัวแปรที่เหลืออยู่ในจำนวนต่างๆจะเห็นว่าจะได้คะแนนสูงสุดเมื่อใช้ค่า ๗ ตัวดังที่พิมพ์ออกมาในบรรทัดสุดท้าย
ต่อมาลองทำให้อยู่ในรูปแบบของคลาสเพื่อให้สะดวกในการใช้งาน
import numpy as np
from sklearn.model_selection import cross_val_score as crovasco
from itertools import combinations as combi
class KhatLueakYonKlapLangTamLamdap:
def __init__(self,model,k0=1,cv=5):
self.model = model
self.k0 = max(k0,1)
self.cv = max(cv,2)
def rianru(self,X,z):
self.n = X.shape[1]
if(self.n<=self.k0):
print('จำนวนมิติข้อมูลต้องมากกว่ามิติต่ำสุดที่ต้องการ')
raise
ind = tuple(range(self.n))
self.index = []
self.khanaen = []
self.std = []
for k in range(self.n,self.k0-1,-1):
khanaen_disut = 0
for ii in combi(ind,k):
cvc = crovasco(self.model,X[:,ii],z,cv=self.cv)
khanaen_ii = cvc.mean()
if(khanaen_ii>khanaen_disut):
ii_disut = ii
khanaen_disut = khanaen_ii
std_disut = cvc.std()
ind = ii_disut
self.index.append(ind)
self.khanaen.append(khanaen_disut)
self.std.append(std_disut)
self.khanaen = np.array(self.khanaen)
self.std = np.array(self.std)
def plaeng(self,X,k=0):
if(k):
return X[:,self.index[self.n-k]]
else:
i = self.khanaen.argmax()
return X[:,self.index[i]]วิธีการใช้จะเริ่มจากสร้างออบเจ็กต์ของคลาสขึ้นมา โดยกำหนดแบบจำลองที่จะใช้ทดสอบ จากนั้นจึงใช้เมธอด rianru() เพื่อป้อนข้อมูลเข้าไปให้ทำการเรียนรู้ประเมินคะแนน
ทดลองใช้ดู ทดสอบกับข้อมูลไวน์ชุดเดิม แต่คราวนี้จะลองใช้กับแบบจำลองการถดถอยโลจิสติก (รายละเอียด https://phyblas.hinaboshi.com/20171010)
from sklearn.linear_model import LogisticRegression as Lori
sbs = KhatLueakYonKlapLangTamLamdap(Lori(),k0=1)
sbs.rianru(X,z)จากนั้นคะแนนจะเก็บอยู่ใน .khanaen และในที่นี้ยังให้มีการเก็บส่วนเบี่ยงเบนมาตรฐานไว้ใน .std ลองเอามาวาดกราฟดูได้
plt.plot(range(13,0,-1),sbs.khanaen,'o-g')
plt.fill_between(range(13,0,-1),sbs.khanaen-sbs.std,sbs.khanaen+sbs.std,color='#AAFFCC')
plt.show()นอกจากนี้ยังได้มีการสร้างเมธอด .plaeng() เอาไว้สำหรับแปลงข้อมูลให้เหลือแค่ตัวแปรที่ถูกคัดไว้ว่าให้ผลดีที่สุด
เช่น ในที่นี้ใช้ตัวแปร 9 ตัวให้ผลดีสุด ดังนั้นหากลองทำการแปลงดูจะได้แบบนี้
print(sbs.plaeng(X).shape) # ได้ (178, 9)แต่จะแปลงโดยระบุจำนวนตัวแปรที่ต้องการเหลือก็ได้
print(sbs.plaeng(X,6).shape) # ได้ (178, 6)จะเห็นว่าวิธีการคัดเลือกย้อนกลับหลังตามลำดับนั้นสามารถเขียนได้ไม่ยากนัก
นอกจากนี้ใน sklearn ยังได้เตรียมวิธีการคัดเลือกค่าแทนลักษณะแบบอื่นๆไว้อีกมากมาย สามารถลองเลือกใช้ตามความเหมาะสมได้
อ้างอิง
-----------------------------------------
囧囧囧囧囧囧囧囧囧囧囧囧囧囧囧囧囧囧囧囧囧囧囧囧囧
หมวดหมู่
-- คอมพิวเตอร์ >> ปัญญาประดิษฐ์-- คอมพิวเตอร์ >> เขียนโปรแกรม >> python >> numpy
-- คอมพิวเตอร์ >> เขียนโปรแกรม >> python >> matplotlib