[python] แยกภาพตัวเลขที่เขียนด้วยลายมือด้วยต้นไม้ตัดสินใจและป่าสุ่ม
เขียนเมื่อ 2017/11/23 22:39
แก้ไขล่าสุด 2021/09/28 16:42

ก่อนหน้านี้ได้ทดสอบแยกภาพตัวเลขของ MNIST ด้วยวิธีการถดถอยโลจิสติกและวิธีการเพื่อนบ้านใกล้ที่สุดมาแล้ว ดูได้ที่
https://phyblas.hinaboshi.com/20170922
https://phyblas.hinaboshi.com/20171102
คราวนี้ลองมาใช้อีกวิธีคือต้นไม้ตัดสินใจ รายละเอียดของวิธีนี้ได้เขียนถึงไปแล้วใน https://phyblas.hinaboshi.com/20171105
แล้วก็อีกวิธีคือป่าสุ่ม ซึ่งได้เขียนไปใน https://phyblas.hinaboshi.com/20171111
เริ่มจากต้นไม้ตัดสินใจ ลองสร้างต้นไม้ตัดสินใจขึ้นโดยใช้ sklearn โดยลองทดลองหลายๆครั้งโดยเปลี่ยนจำนวนครั้งที่แตกกิ่งไปเรื่อยๆ
import matplotlib.pyplot as plt
from sklearn import datasets
from sklearn.tree import DecisionTreeClassifier as Ditri
from sklearn.model_selection import train_test_split
mnist = datasets.fetch_openml('mnist_784')
X,z = mnist.data,mnist.target
X_fuek,X_truat,z_fuek,z_truat = train_test_split(X,z,test_size=0.2)
khanaen_fuek = []
khanaen_truat = []
for i in range(1,21):
dt = Ditri(max_depth=i)
dt.fit(X_fuek,z_fuek)
khanaen_fuek.append(dt.score(X_fuek,z_fuek))
khanaen_truat.append(dt.score(X_truat,z_truat))
plt.plot(range(1,21),khanaen_fuek,'#771133')
plt.plot(range(1,21),khanaen_truat,'#117733')
plt.legend([u'ฝึกฝน',u'ตรวจสอบ'],prop={'family':'Tahoma'})
plt.show()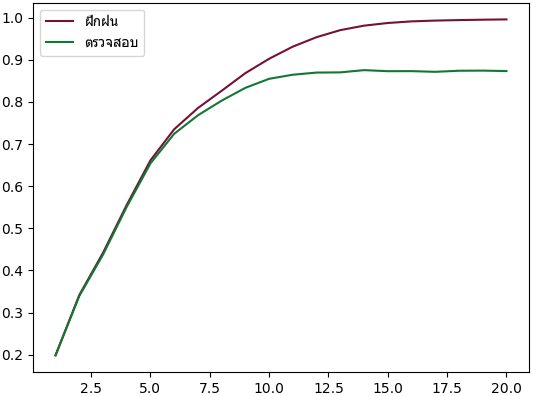
ผลที่ได้จะเห็นว่ายิ่งจำนวนครั้งที่แตกกิ่งมากก็จะได้เพิ่มขึ้น จนถึงจำนวนหนึ่งมากพอถึงเพิ่มก็เริ่มไม่มีผลแล้ว
ปกติหากแตกกิ่งมากพอ ความแม่นในการทายข้อมูลฝึกจะเป็น 100% แต่พอทายข้อมูลตรวจสอบจะไม่มีทางสูงขนาดนั้น ในที่นี้พบว่าความแม่นที่ได้ค่อนข้างต่ำ ไม่ถึง 90%
แล้วจะเห็นว่าตอนที่นำข้อมูลมาใช้ไม่จำเป็นต้องนำมาหาร 255 เหมือนอย่างตอนใช้การถดถอยโลจิสติก นั่นเพราะวิธีนี้ไม่สำคัญว่าสัดส่วนของข้อมูลจะเป็นอย่างไร ไม่จำเป็นต้องทำข้อมูลให้เป็นมาตรฐานก็ได้
ต่อมาลองดูป่าสุ่ม ทำแบบเดียวกัน
from sklearn.ensemble import RandomForestClassifier as Rafo
khanaen_fuek = []
khanaen_truat = []
for i in range(1,21):
rf = Rafo(max_depth=i)
rf.fit(X_fuek,z_fuek)
khanaen_fuek.append(rf.score(X_fuek,z_fuek))
khanaen_truat.append(rf.score(X_truat,z_truat))
plt.plot(range(1,21),khanaen_fuek,'#771133')
plt.plot(range(1,21),khanaen_truat,'#117733')
plt.legend([u'ฝึกฝน',u'ตรวจสอบ'],prop={'family':'Tahoma'})
plt.show()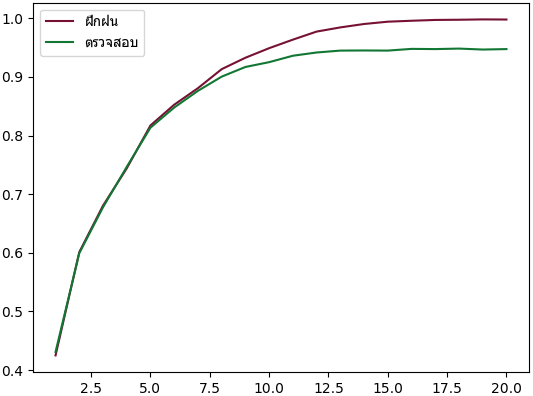
ผลจะเห็นได้ว่าความแม่นในการทายข้อมูลตรวจสอบได้สูงถึง 94% ซึ่งมากกว่าที่ใช้ต้นไม้ตัดสินใจต้นเดียวมาก
นอกจากนี้ประโยชน์อีกอย่างหนึ่งของต้นไม้ตัดสินใจและป่าสุ่มก็คือสามารถนำมาใช้พิจารณาความสำคัญของตัวแปรที่ป้อนเข้าไปได้
ค่าความสำคัญของตัวแปรทั้ง 784 ถูกเก็บอยู่ในแอตทริบิวต์ .feature_importances_ ลองนำมาเปลี่ยนรูปใหม่เป็น 28×28 แล้วแสดงผลออกมาได้เป็นดังนี้
plt.imshow(rf.feature_importances_.reshape(28,28),cmap='gray')
plt.show()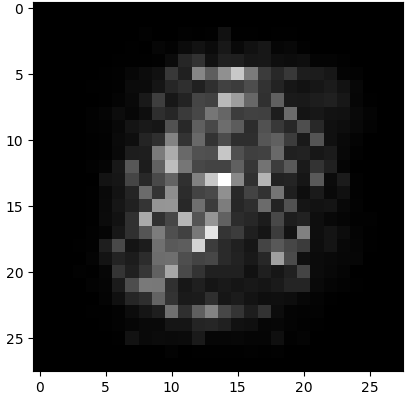
จะเห็นว่าจุดที่อยู่กลางๆจะสำคัญมาก ส่วนบริเวณขอบๆไม่สำคัญ ซึ่งก็ตรงกับที่ควรจะเป็น เพราะตรงกลางเป็นส่วนที่ดินสอไปโดนมากกว่า
-----------------------------------------
囧囧囧囧囧囧囧囧囧囧囧囧囧囧囧囧囧囧囧囧囧囧囧囧囧
หมวดหมู่
-- คอมพิวเตอร์ >> ปัญญาประดิษฐ์-- คอมพิวเตอร์ >> เขียนโปรแกรม >> python >> numpy
-- คอมพิวเตอร์ >> เขียนโปรแกรม >> python >> matplotlib