การใช้ selenium เพื่อควบคุมเบราเซอร์เปิดและใช้งานเว็บโดยอัตโนมัติ
เขียนเมื่อ 2023/02/06 20:34
แก้ไขล่าสุด 2024/08/06 05:19
selenium เป็นเฟรมเวิร์กที่ใช้สำหรับควบคุมเบราว์เซอร์ให้ทำงานอัตโนมัติเพื่อเปิดหน้าเว็บหรือดึงข้อมูล
ที่จริงแล้ว selenium สามารถใช้งานได้ในหลายภาษาไม่ใช่แค่ไพธอน แต่ในที่นี้จะเขียนถึงวิธีการใช้ในภาษาไพธอนเท่านั้น
สำหรับในภาษาไพธอนนั้นมีมอดูล
selenium ซึ่งเอาไว้ใช้งาน seleniumพูดถึงมอดูลที่ใช้ล้วงข้อมูลเว็บในภาษาไพธอนแล้วจริงๆมีอยู่หลายตัว ที่เป็นที่รู้จักกัดีก็เช่น
requests (อ่านรายละเอียดได้ที่ https://phyblas.hinaboshi.com/20180320) หรือ beautifulsoup (https://phyblas.hinaboshi.com/20180323)แต่ว่า requests และ beautifulsoup นั้นใช้การดึงโค้ด html จากเว็บโดยตรง ไม่ได้เข้าเว็บผ่านเบราว์เซอร์ ดังนั้นแม้จะรวดเร็วกว่าแต่ก็จะมีข้อจำกัด ไม่สามารถทำอะไรที่จำเป็นต้องเปิดหน้าเว็บโดยตรงได้
ดังนั้น selenium จึงจำเป็นเพื่อทำในสิ่งที่ requests และ beautifulsoup ทำไม่ได้
ในบทความนี้จะอธิบายวิธีการใช้ selenium เบื้องต้น
การติดตั้งเพื่อใช้งาน
การติดตั้ง selenium ในไพธอนทำได้ง่ายโดยใช้ pip เช่นเดียวกับมอดูลอื่นๆในไพธอน
pip install selenium
selenium ในแต่ละเวอร์ชันนั้นมีความแตกต่างกันอยู่พอสมควร โดยเฉพาะความแตกต่างระหว่างรุ่น 3.x และ 4.x ดังนั้นให้ดูให้ดีว่าที่ติดตั้งลงมานั้นเป็นเวอร์ชันไหน
หลังจากติดตั้งลงมาแล้วก็ลองเรียกใช้ selenium แล้วตรวจสอบเวอร์ชันดูได้
import selenium
print(selenium.__version__)สำหรับเนื้อหาวิธีการใช้ที่จะอธิบายต่อจากนี้ไปจะใช้เวอร์ชัน 4.8 ถ้าใครใช้เวอร์ชันต่างออกไป ผลลัพธ์ที่ได้ก็อาจต่างกันไป
นอกจากนี้แล้วยังจำเป็นต้องมีการติดตั้งเบราว์เซอร์ที่ต้องการใช้เอาไว้ในเครื่องด้วย ในที่นี้จะใช้ google chrome เป็นตัวอย่าง ดังนั้นจำเป็นต้องติดตั้ง google chrome ไว้ แต่ถ้าใครไม่มีก็อาจใช้ firefox, safari, edge แทนก็ได้ การใช้งานไม่ได้ต่างกันนัก
การเปิดหน้าต่างเบราว์เซอร์
เมื่อติดตั้ง selenium ในไพธอนเสร็จแล้วก็สามารถลองเริ่มใช้งานได้เลย ก่อนอื่นเริ่มจากนั่งเปิดหน้าต่างเบราว์เซอร์ขึ้นมาแล้วให้เข้าเว็บ google ดู ซึ่งทำได้โดยเขียนโค้ดดังนี้
from selenium import webdriver
driver = webdriver.Chrome()
driver.get('https://www.google.co.th')แล้วก็มีหน้าต่างเปิดขึ้นแสดงหน้าเว็บแบบนี้
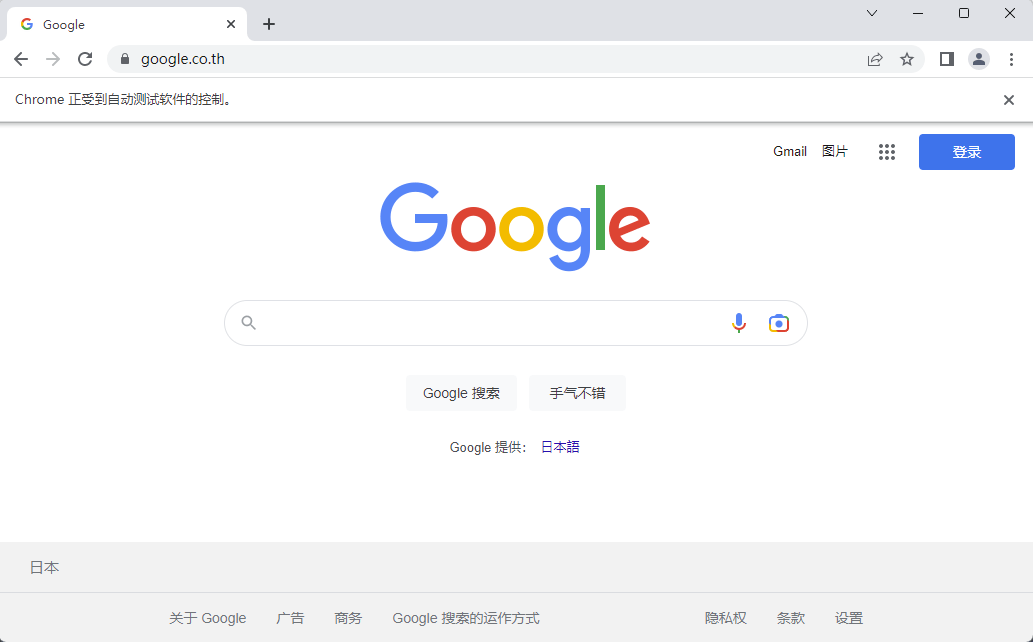
โค้ดเริ่มจากสร้างออบเจ็กต์ตัวไดรเวอร์ขึ้นมา โดยในที่นี้ใช้ google chrome จึงเป็น
webdriver.Chrome แต่ถ้าใช้ firefox ก็จะเป็น webdriver.Firefox ถ้าใช้ edge ก็จะเป็น webdriver.Edge เป็นต้น จะใช้เบราว์เซอร์ตัวไหนก็ได้ที่มีการติดตั้งอยู่ในเครื่องไว้แล้วแต่ถ้าไม่มีอยู่ก็จะเกิดข้อผิดพลาดขึ้นจากนั้นก็ใช้เมธอด
.get() เพื่อเปิดหน้าเว็บที่ต้องการจะเข้าหน้าต่างที่ขึ้นมาแล้วจะกดปิดไปเองก็ได้ หรือถ้าอยากจะใช้โค้ดสั่งให้ปิดก็ใช้เมธอด
.quit() ได้driver.quit()การดึงเอาข้อมูลต่างๆจากหน้าเว็บ
หลังจากเปิดหน้าเว็บขึ้นมาแล้ว ข้อมูลต่างๆของตัวเว็บก็จะอยู่ในออบเจ็กต์ไดรเวอร์ สามารถเอาข้อมูลต่างๆได้จากแอตทริบิวต์ของออบเจ็กต์
from selenium import webdriver
driver = webdriver.Chrome()
driver.get('https://th.wikipedia.org/wiki/กูเกิล')
print(driver.current_url) # url หน้าเว็บ
print(driver.title) # ชื่อหน้าเว็บ
print(len(driver.page_source)) # โค้ด html ของหน้าเว็บ (ในที่นี้ขอดูแค่ความยาวของหน้า)
driver.quit()ได้
https://th.wikipedia.org/wiki/%E0%B8%81%E0%B8%B9%E0%B9%80%E0%B8%81%E0%B8%B4%E0%B8%A5
กูเกิล - วิกิพีเดีย
507075การเปลี่ยนหน้าเว็บ
หลังจากที่เปิดหน้าต่างขึ้นมาแล้ว หากต้องการเปลี่ยนหน้าเว็บไปหน้าอื่นก็แค่ใช้เมธอด
.get() อีกที และหากต้องการย้อนกลับก็ใช้ .back() และถ้าจะย้อนไปข้างหน้าอีกก็ใช้ .forward() ได้ตัวอย่างเช่นลองเปิดหน้าเว็บไปๆมาๆระหว่างกูเกิลกับวิกิพีเดีย
from selenium import webdriver
driver = webdriver.Chrome()
driver.get('https://www.google.co.th')
print(driver.title)
driver.get('https://th.wikipedia.org')
print(driver.title)
driver.back()
print(driver.title)
driver.forward()
print(driver.title)
driver.quit()ได้
Google
วิกิพีเดีย สารานุกรมเสรี
Google
วิกิพีเดีย สารานุกรมเสรีนอกจากนี้ยังมีเมธอด
.refresh() เอาไว้ใช้รีเฟรชโหลดหน้าใหม่การบันทึกภาพหน้าจอ
สิ่งหนึ่งที่เห็นได้ชัดว่า selenium ทำได้แต่ requests ไม่สามารถทำได้ก็คือการบันทึกภาพหน้าจอเบราว์เซอร์นั่นเอง เนื่องจาก selenium ได้เปิดหน้าต่างเบราว์เซอร์ขึ้นมาจริงๆจึงเห็นหน้าตาของเว็บ และสามารถบันทึกภาพไว้ได้
การบันทึกภาพหน้าจอทำได้โดยเมธอด
.save_screenshot()from selenium import webdriver
driver = webdriver.Chrome()
driver.get('https://th.wikipedia.org/wiki/ราเม็ง')
driver.save_screenshot('phapnacho.png')ก็จะได้ภาพนี้

ภาพที่ได้มานั้นจะเป็นสกุล .png เท่านั้น ต่อให้ตั้งชื่อไฟล์เป็นสกุลอื่นก็ได้ภาพ .png อยู่ดี
หรือนอกจากจะบันทึกเป็นไฟล์ทันทีแล้ว อาจใช้เมธอด
.get_screenshot_as_png() เพื่อเก็บภาพไว้ในหน่วยความจำ แล้วอาจใช้ io.BytesIO กับ PIL.Image เพื่อเปิดขึ้นมาfrom selenium import webdriver
from PIL import Image
import io
driver = webdriver.Chrome()
driver.get('https://th.wikipedia.org/wiki/อูดง')
png = driver.get_screenshot_as_png()
Image.open(io.BytesIO(png)).show()การเปิดเว็บโดยไม่ต้องแสดงหน้าต่างให้เห็น (headless)
ในโหมดปกตินั้นเวลาเปิดเบราว์เซอร์ขึ้นมาก็จะมีหน้าต่างขึ้นมาให้เห็น ดังตัวอย่างที่ยกมาข้างต้นแล้ว
แต่เราสามารถให้เบราว์เซอร์ถูกเปิดอยู่เบื้องหลังโดยไม่ปรากฏหน้าต่างขึ้นมาให้เห็น ซึ่งสามารทำได้โดยเปิดเป็นโหมด headless
การเปิดโหมด headless ทำได้โดยการใช้
webdriver.ChromeOptions() โดยใช้เมธอด .add_argument() ใส่ --headless ลงไป แล้วใส่คีย์เวิร์ด options ไปใน webdriver.Chrome()ตัวอย่างเช่น ลองให้เบราว์เซอร์ทำงานอยู่เบื้องหลังไปถ่ายภาพหน้าเว็บวิกิมา
from selenium import webdriver
options = webdriver.ChromeOptions()
options.add_argument('--headless')
driver = webdriver.Chrome(options=options)
driver.get('https://th.wikipedia.org/wiki/โซบะ')
driver.save_screenshot('phapnacho.png')
driver.quit()ก็จะได้ภาพนี้
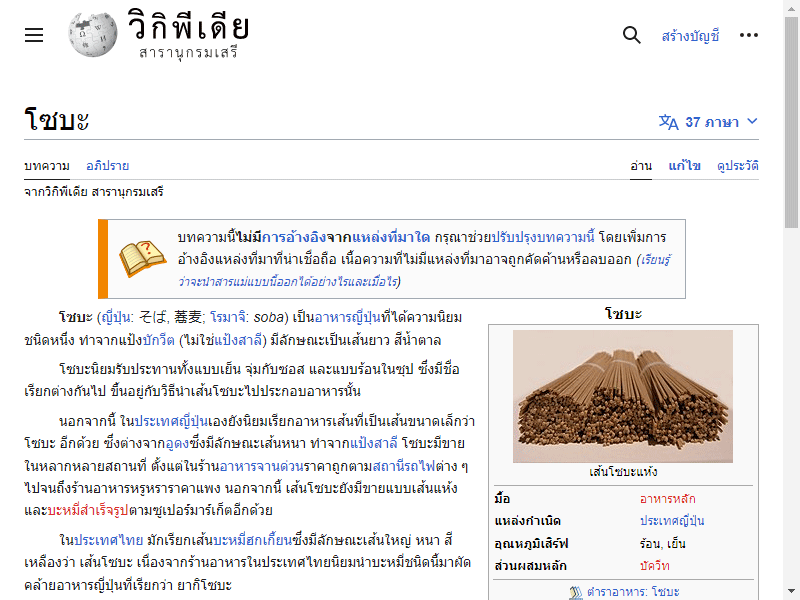
โหมดนี้จะทำงานเบื้องหลังโดยไม่ได้ขึ้นมาให้เห็นในจอ ดังนั้นระหว่างที่รันอยู่เราก็ไม่ต้องไปสนมัน ทำงานอย่างอื่นไปแล้วรอแค่ผลลัพธ์ก็พอ สะดวกเวลาที่ต้องการทำอย่างอื่นไปด้วย
เพียงแต่ว่าเมื่อไม่เห็นหน้าจอ ถ้าเกิดมีการทำงานอะไรผิดพลาดเราก็อาจไม่สามารถเห็นได้ ดังนั้นถ้าอยากจะตรวจสอบการทำงานอาจให้โปรแกรมบันทึกภาพบนหน้าต่าง หรือสั่ง print ไว้ก็ได้
เมื่อใช้งานโหมดนี้หน้าต่างจะไม่ปรากฏขึ้นมาให้เห็น แบบนั้นเราจะมากดปิดเองก็ไม่ได้ ดังนั้นถ้าใช้งานโหมดนี้ก็อย่าลืมใส่
driver.quit() ตอนท้ายสุดเพื่อปิดด้วยการกำหนดความกว้างและความสูงของหน้าต่าง
ขนาดของหน้าต่างตอนเริ่มต้นสามารถกำหนดได้โดยใช้
.add_argument() ลงใน options โดยใส่เป็น --window-size=ความกว้าง,ความสูงตัวอย่างเช่น
from selenium import webdriver
options = webdriver.ChromeOptions()
options.add_argument('--headless')
options.add_argument('--window-size=500,400')
driver = webdriver.Chrome(options=options)
driver.get('https://th.wikipedia.org/wiki/เทริยากิ')
driver.save_screenshot('phapnacho.png')
driver.quit()ก็จะได้ภาพหน้าจอที่มีขนาดหน้าต่างตามที่กำหนดไว้
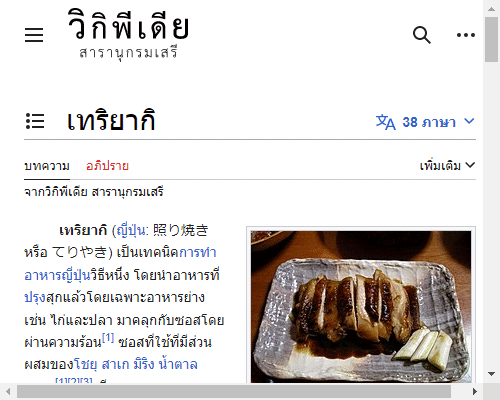
นอกจากนี้ยังอาจกำหนดขนาดหน้าต่างภายหลังได้โดยใช้เมธอด
.set_window_size() เช่นfrom selenium import webdriver
options = webdriver.ChromeOptions()
options.add_argument('--headless')
driver = webdriver.Chrome(options=options)
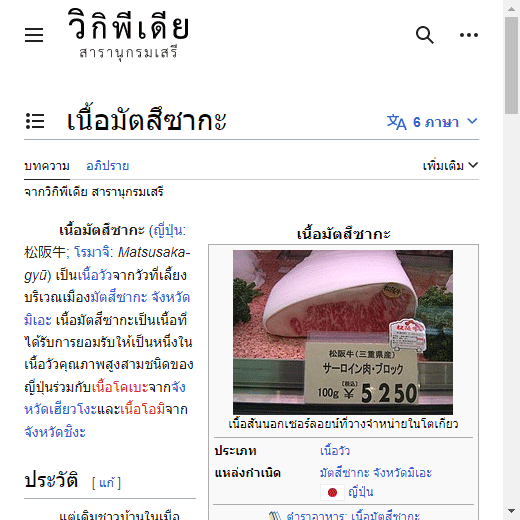
driver.get('https://th.wikipedia.org/wiki/เนื้อมัตสึซากะ')
driver.set_window_size(520,520)
driver.save_screenshot('phapnacho.png')
driver.quit()ก็จะได้ภาพหน้าจอที่มีขนาดตามที่กำหนดไว้เช่นกัน
การสั่งรันจาวาสคริปต์ในหน้าต่าง
เราสามารถส่งคำสั่งจาวาสคริปต์เพื่อเข้าไปควบคุมหรือทำอะไรต่างๆในหน้าต่างได้โดยใช้เมธอด
.execute_script()เช่นถ้าต้องการจะรู้ขนาดของหน้าต่างก็อาจพิมพ์
return window.outerWidth; และ return window.outerHeight; หรือถ้าต้องการให้ขึ้นกล่องข้อความก็สั่งด้วยฟังก์ชัน alert();ตัวอย่างเช่นลองทำให้ขึ้นกล่องข้อความที่แสดงขนาดหน้าจอ
from selenium import webdriver
driver = webdriver.Chrome()
driver.get('https://google.co.th?hl=th')
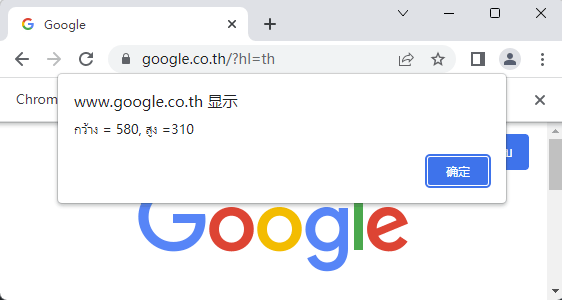
driver.set_window_size(580,310)
kwang = driver.execute_script("return window.outerWidth;")
sung = driver.execute_script("return window.outerHeight;")
driver.execute_script('alert("กว้าง = %d, สูง =%d");'%(kwang,sung))ก็จะได้หน้าจอที่มีกล่องข้อความแสดงความกว้างและความสูงของหน้าต่างขึ้นมา
หากจะซ่อนแถบลูกศรเลื่อนหน้าบนหน้าต่างก็อาจเขียนโค้ดแบบนี้
driver.execute_script("document.body.style.overflow = 'hidden';")นอกจากนี้ก็ยังใช้ทำอะไรต่างๆได้อีกมากมาย เป็นเวิธีการที่สะดวกดีสำหรับคนที่รู้วิธีการใช้จาวาสคริปต์ในเบราว์เซอร์
การบันทึกภาพหน้าจอทั้งหน้า
หนึ่งในการประยุกต์ใช้คำสั่งจาวาสคริปต์ คือเราสามารถรู้ความกว้างและสูงทั้งหมดของหน้าแล้วเอามาปรับขนาดของหน้าต่างให้ใหญ่เท่ากันได้ จากนั้นถ้าเราบันทึกภาพหน้าจอก็จะได้ภาพที่หน้าเว็บนั้นเต็มทั้งหน้า
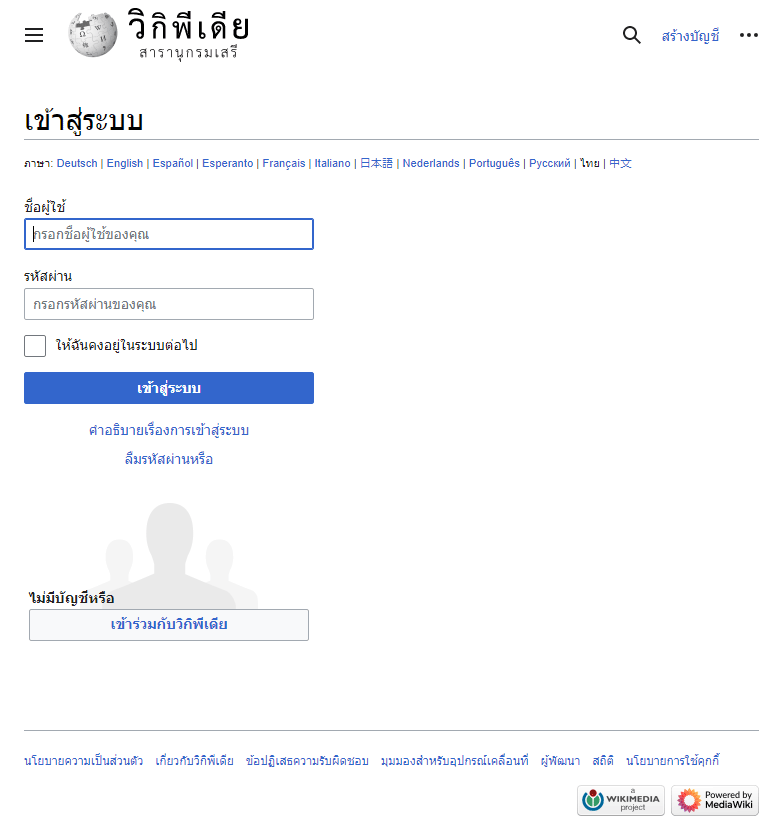
เช่นลองบันทึกหน้าจอหน้าล็อกอินของวิกิพีเดียดู
from selenium import webdriver
options = webdriver.ChromeOptions()
options.add_argument('--headless')
driver = webdriver.Chrome(options=options)
driver.get('https://th.wikipedia.org/w/index.php?title=พิเศษ:ล็อกอิน')
width = driver.execute_script("return document.body.scrollWidth;")
height = driver.execute_script("return document.body.scrollHeight;")
driver.set_window_size(width,height)
driver.execute_script("document.body.style.overflow = 'hidden';")
driver.save_screenshot('phapnacho.png')
driver.quit()ก็จะได้ภาพแบบนี้ออกมา
การค้นหาส่วนที่ต้องการจาก ID ของแท็ก
โครงสร้างของหน้าเว็บนั้นถูกสร้างขึ้นมาจากแท็กต่างๆมากมายมาประกอบรวมกัน ในการใช้ selenium นั้นโดยทั่วไปแล้วจะทำโดยการค้นเอาแท็กในหน้านั้นมาแล้วจัดการควบคุมที่ตัวแท็กนั้น
selenium มีคำสั่งที่ใช้สำหรับค้นหาแท็กที่ต้องการอยู่หลายวิธี เช่นค้นจาก ID ของแท็ก เป็นต้น
การจะค้นแท็กจาก ID ได้นั้นเราจำเป็นต้องเข้าใจองค์ประกอบของหน้าเว็บก่อน เช่นสมมุติว่าต้องการค้นหาปุ่มสำหรับกดเพื่อล็อกอินของหน้าล็อกอินวิกิพีเดีย อาจลองใช้เครื่องมือวิเคราะห์องค์ประกอบ โดยกด F12 ในเบราว์เซอร์ เลือกหน้าต่าง "องค์ประกอบ" แล้วค้นหาไปเรื่อยๆ ก็เจอส่วนที่ต้องการ ดังภาพ (คลิกเพื่อดูภาพใหญ่)
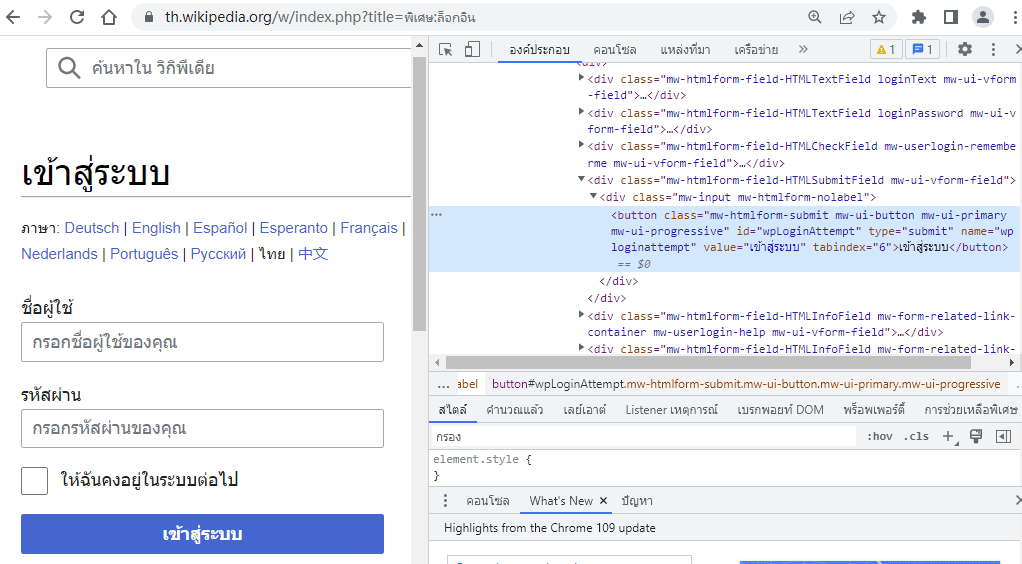
จากภาพจะเห็นว่า ID ของแท็กนี้คือ wpLoginAttempt
การค้นจาก ID ทำได้โดยใช้เมธอด
.find_element() แล้วใส่อาร์กิวเมนต์ตัวแรกเป็น id แล้วตามด้วยตัวที่ ๑ เป็นชื่อ id ที่ต้องการค้น เมื่อใช้แล้วก็จะได้ออบเจ็กต์ของตัวแท็กนี้มา สามารถเอามาใช้ทำอะไรต่างๆได้ตัวอย่าง ลองค้นเอาแท็กนี้มาดูค่าอะไรต่างๆ
from selenium import webdriver
driver = webdriver.Chrome()
driver.get('https://th.wikipedia.org/w/index.php?title=พิเศษ:ล็อกอิน')
pum = driver.find_element('id','wpLoginAttempt')
print(pum.size) # ขนาดของแท็ก
print(pum.location) # ตำแหน่งของแท็ก
print(pum.tag_name) # ชนิดแท็ก
print(pum.text) # ข้อความในแท็กก็จะได้ค่าต่างๆของแท็กนั้นออกมาดังนี้
{'height': 32, 'width': 290}
{'x': 44, 'y': 375}
button
เข้าสู่ระบบการค้นหาส่วนที่ต้องการในหน้าต่างจากแอตทริบิวต์ name ของแท็ก
นอกจากหาด้วย ID แล้วก็อาจจะหาจากแอตทริบิวต์ name ของแท็กได้ โดยใช้เมธอด
.find_element() เช่นเดียวกัน แต่ใส่อาร์กิวเมนต์ตัวแรกเป็น name แทนเช่นในหน้าล็อกอินวิกิพีเดียในตัวอย่างที่แล้วถ้าใช้ name ค้นก็จะเขียนป็น
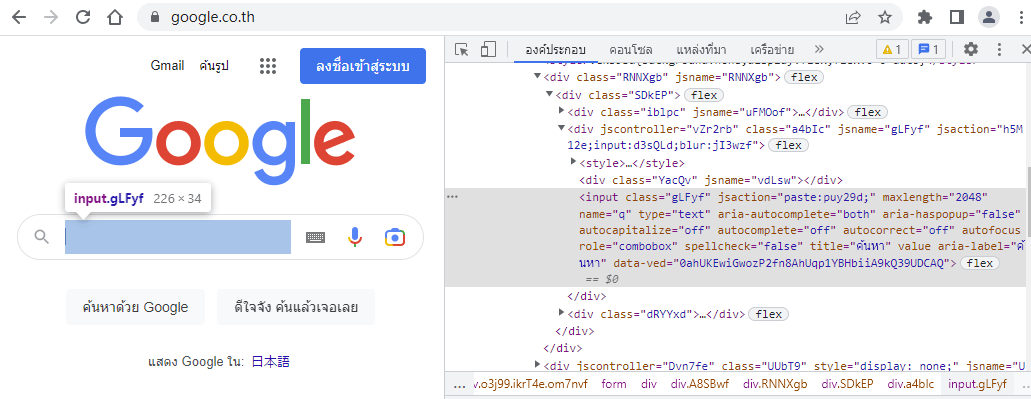
driver.find_element('name','wploginattempt') ผลที่ได้ก็เหมือนตอนที่ใช้ ID ค้นตัวอย่างต่อไปนี้จะลองใช้กับหน้าค้นของของกูเกิลดู โดยส่วนแท็กของช่องค้นจะเป็นดังในภาพนี้ (คลิกเพื่อดูภาพใหญ่) จะเห็นว่าแท็กนี้ไม่มีกำหนด ID แต่มี name คือ q
โค้ดสำหรับค้นหาแท็กของช่องข้อความค้นหาเขียนได้ดังนี้
from selenium import webdriver
driver = webdriver.Chrome()
driver.get('https://www.google.co.th?hl=th')
q = driver.find_element('name','q')
print(q.size)
print(q.location)
print(q.tag_name)ได้
{'height': 34, 'width': 403}
{'x': 273, 'y': 184}
inputการดูค่าแอตทริบิวต์ของแท็ก
ค่าแอตทริบิวต์ของแท็กสามารถดูได้โดยใช้เมธอด
.get_attribute() โดยใส่ชื่อแอตทริบิวต์ที่ต้องการ เช่นสำหรับช่องค้นหาของกูเกิลในตัวอย่างที่แล้วลองเพิ่มโค้ดนี้ลงไปดูprint(q.get_attribute('class'))
print(q.get_attribute('type'))
print(q.get_attribute('title'))จะได้
gLFyf
text
ค้นหาการพิมพ์ข้อความในช่องกรอกข้อความ
เมื่อเราหาเจอแท็กที่เป็นช่องกรอกข้อความแล้ว สิ่งต่อไปที่น่าจะอยากทำก็คือการพิมพ์ข้อความลงในนั้น การกรอกข้อความลงไปนั้นทำได้โดยใช้เมธอด
.send_keys()ตัวอย่างเช่น ลองกรอกข้อความลงในช่องชื่อผู้ใช้ในหน้าล็อกอินของวิกิพีเดียดู
from selenium import webdriver
options = webdriver.ChromeOptions()
options.add_argument('--headless')
options.add_argument('--window-size=400,400')
driver = webdriver.Chrome(options=options)
driver.get('https://th.wikipedia.org/w/index.php?title=พิเศษ:ล็อกอิน')
wpname = driver.find_element('id','wpName1')
wpname.send_keys('ฉันเองไงล่ะ')
driver.save_screenshot('phapnacho.png')
driver.quit()ข้อความที่เราใส่ไปก็จะถูกกรอกลงในช่องดังภาพนี้
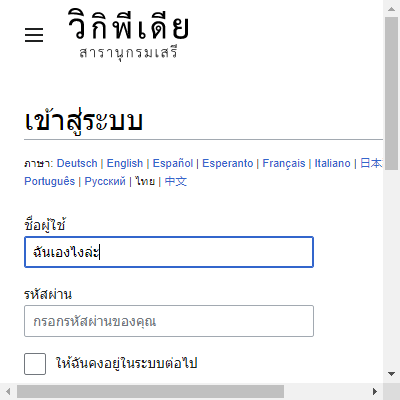
ส่วนการกดซับมิตช่องกรอกข้อความเหมือนกับที่ทำตอนกด enter นั้นทำได้โดยใช้
webdriver.common.keys.Keys.ENTERเช่นลองกรอกข้อความในช่องค้นหาของกูเกิลแล้วทำการซับมิต เขียนได้ดังนี้
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
options = webdriver.ChromeOptions()
options.add_argument('--headless')
options.add_argument('--window-size=500,300')
driver = webdriver.Chrome(options=options)
driver.get('https://www.google.co.th?hl=th')
q = driver.find_element('name','q')
q.send_keys('ไพธอน')
driver.save_screenshot('phapnacho1.png')
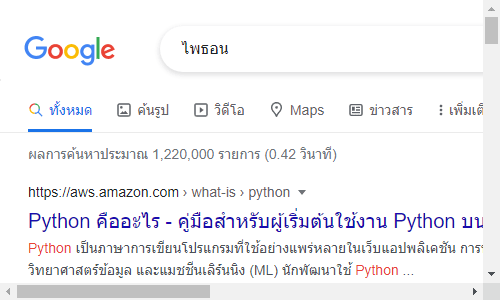
q.send_keys(Keys.ENTER)
driver.save_screenshot('phapnacho2.png')
driver.quit()ภาพหลังกรอกข้อความ ก่อนซับมิต
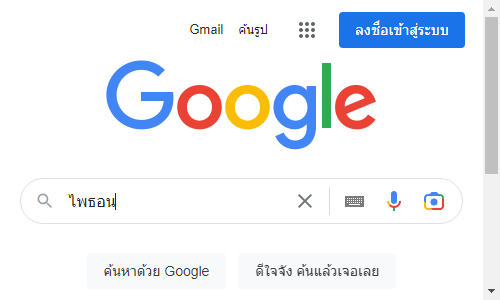
ภาพหลังจากซับมิตแล้ว ย้ายไปหน้าใหม่
นอกจากนี้แล้ว จริงๆอาจทำการซับมิตได้โดยใช้ใช้เมธอด
.submit() ก็ได้ เช่นโค้ดในส่วน q.submit() และนอกจากนี้แล้วเรายังสามารถผสมคีย์เพื่อทำอะไรต่างๆได้ เช่น
ctrl+c และ ctrl+v เพื่อคัดลอกและแปะข้อความ เป็นต้นตัวอย่างการใช้
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
driver = webdriver.Chrome()
driver.get('https://www.google.co.th?hl=th')
q = driver.find_element('name','q')
q.send_keys('ใครมา')
q.send_keys(Keys.SHIFT+Keys.LEFT+Keys.LEFT) # ลากคลุมไปทางซ้าย ๒ ช่อง
q.send_keys(Keys.CONTROL+'c') # คัดลอกข้อความที่ลากคลุม
q.send_keys(Keys.CONTROL+'a') # ลากคลุมข้อความทั้งหมด
q.send_keys(Keys.DELETE) # ลบข้อความทั้งหมด
q.send_keys('ไม่')
q.send_keys(Keys.CONTROL+'v') # แปะข้อความการจัดการช่องติ๊ก
สำหรับส่วนประกอบที่เป็นช่องติ๊กนั้นสามารถใช้เมธอด
.click() เพื่อกดติ๊กช่องได้ ส่วนสถานะว่าช่องติ๊กนั้นถูกติ๊กอยู่หรือเปล่าอาจดูได้ด้วยเมธอด .is_selected()ขอยกตัวอย่างด้วยการใช้ในหน้าล็อกอินของวิกิพีเดีย โดยในนี้มีช่องติ๊กสำหรับให้จดจำผู้ใช้ให้อยู่ในระบบต่อไป
from selenium import webdriver
import time
options = webdriver.ChromeOptions()
options.add_argument('--headless')
options.add_argument('--window-size=380,450')
driver = webdriver.Chrome(options=options)
driver.get('https://th.wikipedia.org/w/index.php?title=พิเศษ:ล็อกอิน')
chongtick = driver.find_element('name','wpRemember')
print(chongtick.is_selected()) # ได้ False
chongtick.click() # กดติ๊กช่อง
print(chongtick.is_selected()) # ได้ True
time.sleep(1) # รอเวลาสักพักให้ผลการติ๊กแสดงให้เห็นในหน้าจอ
driver.save_screenshot('phapnacho.png')
driver.quit()ในที่นี้ใช้
time.sleep() เข้าช่วยเพื่อถ่วงเวลาก่อนที่จะบันทึกภาพ เพราะช่องติ๊กนั้นเมื่อคลิกแล้วยังต้องรอสักพักหน้าจอจึงจะเห็นการติ๊กภาพที่ได้ก็จะออกมาเป็นแบบนี้
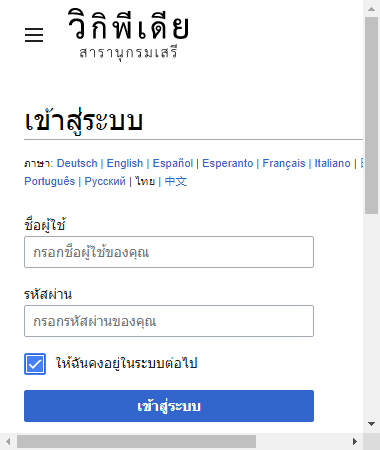
การค้นหาองค์ประกอบจากชื่อคลาส
นอกจากจะค้นหาแท็กจาก ID และ name แล้วก็ยังมีวิธีการค้นหาอีกหลายวิธี เช่นการค้นหาจากชื่อคลาส ในการค้นจากคลาสนั้นอาจทำได้โดยใช้เมธอด
find_element() เช่นกันโดยใส่เป็น class name เพียงแต่ว่าแท็กที่คลาสเหมือนกันนั้นอาจมีอยู่หลากหลาย ผลลัพธ์ที่ได้ในที่นี้จะเป็นแท็กที่ค้นเจอเป็นแท็กแรกแต่หากต้องการให้ค้นแท็กที่เป็นคลาสนั้นทั้งหมดให้ใช้เมธอด
find_elements() (ต่างกันตรงที่ elements เติม s แสดงให้เห็นว่ามีหลายตัว) แล้วผลที่ได้ก็จะออกมาเป็นลิสต์ของออบเจ็กต์ของทุกแท็กที่เป็นคลาสนั้นตัวอย่างเช่นในหน้าผลลัพธ์การค้นหาของกูเกิลนั้น หน้าเว็บที่ค้นเจอแต่ละหน้านั้นจะถูกใส่อยู่ในแท็กคลาส g เราอาจลองค้นแต่ละแท็กแล้วดูตำแหน่งในหน้าจอของแท็กนั้นได้ดังนี้
from selenium import webdriver
options = webdriver.ChromeOptions()
options.add_argument('--headless')
options.add_argument('--window-size=400,530')
driver = webdriver.Chrome(options=options)
driver.get('https://www.google.co.th/search?q=ง่วง&hl=th')
lis_g = driver.find_elements('class name','g')
print(len(lis_g))
for g in lis_g:
print(g.location)
driver.save_screenshot('phapnacho.png')
driver.quit()ภาพผลการค้นหาจะได้เป็นแบบนี้
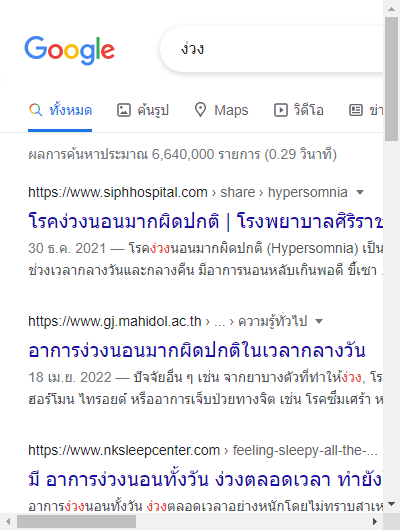
ส่วนข้อความที่ถูกพิมพ์ออกมาจะเป็นแบบนี้ แสดงให้เห็นว่าผลลัพธ์แต่ละอันถูกวางเรียงจากบนลงล่าง ตามที่เห็นในภาพ
9
{'x': 28, 'y': 182}
{'x': 28, 'y': 311}
{'x': 28, 'y': 440}
{'x': 28, 'y': 683}
{'x': 28, 'y': 811}
{'x': 28, 'y': 940}
{'x': 28, 'y': 1069}
{'x': 28, 'y': 1198}
{'x': 28, 'y': 1326}การค้นหาองค์ประกอบจากชื่อแท็ก
เช่นเดียวกับการตามหาด้วยคลาส เราอาจค้นหาโดยใช้ชื่อแท็กก็ได้ โดยใช้เมธอด
.find_element() เพื่อหาผลลัพธ์แรกอันเดียว หรือใช้ .find_elements() เพื่อค้นผลลัพธ์ทั้งหมดออกมาเป็นลิสต์ แค่ใส่เป็น tag nameเช่นลองค้นหาแท็ก h3 ในหน้าผลลัพธ์การค้นหากูเกิล ซึ่ง h3 นั้นในที่นี้ถูกใช้ใส่ชื่อเว็บที่ค้นเจอ
from selenium import webdriver
driver = webdriver.Chrome()
driver.get('https://www.google.co.th/search?q=กาแฟ&hl=th')
lis_h3 = driver.find_elements('tag name','h3')
for h3 in lis_h3:
print('~',h3.text)
driver.quit()ได้
~ กาแฟ - วิกิพีเดีย
~ 8 ประเภทกาแฟน่ารู้ - สบู่โยโล่ บาย ดร.มนตรี
~ มารู้จักกาแฟกันเถอะ
~ กาแฟ สรรพคุณและประโยชน์ของกาแฟ 40 ข้อ ! (Coffee)
~ กาแฟ ราคาพิเศษ | ซื้อออนไลน์ที่ Shopee ส่งฟรี*ทั่วไทย! อาหาร ...
~ สั่งซื้อ กาแฟ ราคาดี ลดราคา ออนไลน์ | เครื่องดื่ม อาหารและ ...
~ มารู้จักประเภทกาแฟชนิดต่างๆ กัน - Gather8.com
~ แผนที่
~ รายการตัวกรอง
~ กาแฟ ประโยชน์และโทษต่อสุขภาพที่ควรรู้ - Pobpad
~ เมนูกาแฟ กับเรื่องลับ ๆ ของกาแฟที่อาจไม่เคยรู้มาก่อน - เมนูอาหาร
~ กาแฟสำเร็จรูป กาแฟพร้อมดื่ม | สั่งเลย สั่งง่าย ส่งไว ครบตรงใจคุณ
~ คำอธิบายการค้นหาตามข้อความที่มีในลิงก์
เราอาจหาแท็กที่เป็นลิงก์ (แท็ก a) ที่มีข้อความตามที่กำหนดโดยใช้
.find_element() หรือ .find_elements โดยใส่เป็น link textเช่นลองเปิดวิกิพีเดียนหน้า "โตเกียว" หาลิงก์ที่เขียนว่า "ญี่ปุ่น" แล้วคลิกเพื่อเข้าหน้านั้น
from selenium import webdriver
driver = webdriver.Chrome()
driver.get('https://th.wikipedia.org/wiki/โตเกียว')
link = driver.find_element('link text','ญี่ปุ่น')
link.click()หรืออาจจะหาลิงก์ที่ครอบคลุมข้อความที่กำหนดอยู่ได้โดยใส่เป็น
partial link textตัวอย่างเช่น ลองเข้าเพจรายชื่อประเทศแล้วค้นหาประเทศที่ชื่อมีคำว่า "สถาน" อยู่
from selenium import webdriver
driver = webdriver.Chrome()
driver.get('https://th.wikipedia.org/wiki/รายชื่อประเทศ_ดินแดน_และเมืองหลวง')
lis_sathan = driver.find_elements('partial link text','สถาน')
for sathan in lis_sathan:
print(sathan.text)การค้นหาแท็กจาก css
สามารถค้นหาแท็กโดยระบุโค้ดเหมือนที่ใช้เวลาเขียน css ได้ โดยใช้
.find_element() หรือ .find_elements() โดยใส่เป็น css selectorตัวอย่างเช่น ค้นหาแท็ก h3 ที่อยู่ภายในแท็กที่เป็นคลาส g
from selenium import webdriver
driver = webdriver.Chrome()
driver.get('https://www.google.co.th/search?q=มังกร&hl=th')
lis_gh3 = driver.find_elements('css selector','.g h3')
for gh3 in lis_gh3:
print('~',gh3.text)
driver.quit()ได้
~ มังกร - วิกิพีเดีย
~ มังกรจีน - วิกิพีเดีย
~ 5,000+ ฟรี มังกร & แฟนตาซี รูปภาพ - Pixabay
~ รู้จัก "มังกร" แบบวิทย์ วิทย์!!! (ตุ้งแช่ ตุ้งแช่) - SciMath
~ มังกร - วิกิพจนานุกรม
~ เล่าสู่กันฟัง...เรื่อง “มังกร : สัตว์เทพหรือปีศาจ” - กรมส่งเสริมวัฒนธรรม
~ 10 มังกรทรงพลังที่สุดในตำนาน (ใหญ่มาก!) - YouTube
~ มังกรทรงพลังและแข็งแกร่งที่สุดในเทพนิยาย (อย่าไปแหยมเชียว)
~ ความเชื่อเรื่องมังกรของชาวจีน - Facebookการค้นหาแท็กย่อยภายในแท็ก
เมธอด
.find_element และ .find_elements นั้นนอกจากจะใช้กับตัวออบเจ็กต์ driver เพื่อจะค้นทั้งหน้าต่างแล้ว ก็ยังอาจใช้ที่ตัวออบเจ็กต์แท็กเพื่อใช้ค้นหาเฉพาะแท็กย่อยภายในแท็กนั้นได้เช่นลองให้ค้นแท็ก g ในหน้าผลลัพธ์การค้นหากูเกิลแล้วแสดงส่วน h3 และ span แรกที่ปรากฏในนั้น
from selenium import webdriver
driver = webdriver.Chrome()
driver.get('https://www.google.co.th/search?q=แมว&hl=th')
lis_g = driver.find_elements('class name','g')
for g in lis_g:
h3 = g.find_element('tag name','h3')
span1 = g.find_element('tag name','span')
print('[%s] %s'%(h3.text,span1.text))
driver.quit()ได้
[แมว - วิกิพีเดีย] › wiki › แมว
[มาทำความรู้จักมากกว่า 30 สายพันธุ์แมวทั้งหมดและลักษณะนิสัยของ ...] › สายพันธุ์แมว
[รวมให้แล้ว! 13 พันธุ์แมวยอดฮิต น่ารัก น่าเลี้ยง เยียวยาทาส ...] › friendly-cat-breeds
[มือใหม่เตรียมพร้อมรับเลี้ยงลูกแมวตัวแรก - Purina] › way-to-handle-new-kitten
[ซื้อ ขาย แมว ออนไลน์ ราคาถูก | Kaidee] › สัตว์เลี้ยง
[แมวบ้านต่างจากสัตว์เลี้ยงทั่วไป ไม่ยอมสนใจอาหาร หากต้องทำ ...] › thai › international-58214152
[7 สัญญาณเตือนว่าแมวกำลังป่วย - Thonglor Pet Hospital] › petdiary › 7-สัญญาณเตือนว...
[ค้นรูป]การค้นหาแท็กด้วย xpath
อีกวิธีการที่สะดวกที่ใช้ในการค้นหาแท็กที่ต้องการคือการเขียน xpath โดยใช้เมธอด
.find_element() หรือ .find_elements() โดยใส่ xpathการใช้ xpath นั้นอาจจะดูเข้าใจยากสักหน่อย แต่ถ้าเขียนเป็นจะใช้งานได้ยืดหยุ่นมากทีเดียว แต่ว่าเนื่องจากมีรายละเอียดการใช้งานที่ต้องอธิบายยาว ตรงส่วนนี้จะขอละไว้ ใครสนใจลองค้นหาในกูเกิลเองได้ ในที่นี้จะขอแสดงแค่แสดงให้เห็นว่าจะเอา xpath มาใช้ใน selenium ยังไงเท่านั้น
ตัวอย่างการใช้ เช่นค้นหาองค์ประกอบภายในแท็กแบบฟอร์มค้นหาหน้าเว็บ
from selenium import webdriver
driver = webdriver.Chrome()
driver.get('https://th.wikipedia.org')
lis_el = driver.find_elements('xpath','//*[@id="searchform"]//*')
print(len(lis_el))
for el in lis_el:
print('[%s] id:"%s", name: "%s", value: "%s"'%(el.tag_name,el.get_attribute('id'),el.get_attribute('name'),el.get_attribute('value')))ผลที่ได้จะเห็นว่ามี ๕ แท็กอยู่ภายในแบบฟอร์มนี้
5
[div] id:"simpleSearch", name: "None", value: "None"
[input] id:"searchInput", name: "search", value: ""
[input] id:"", name: "title", value: "พิเศษ:ค้นหา"
[input] id:"mw-searchButton", name: "fulltext", value: "ค้นหา"
[input] id:"searchButton", name: "go", value: "ไป"อย่างไรก็ตาม มีวิธีหา xpath ของแท็กที่ต้องการเพื่อนำมาใช้ได้โดยง่ายอยู่ นั่นคือเปิดเบราว์เซอร์ขึ้นมาแล้วไปดูที่องค์ประกอบ แล้วดูตรงส่วนที่เราต้องการ พอเจอแล้วก็คลิกขวาแล้วเลือก "คัดลอก XPath" ดังในรูปนี้ เท่านี้ก็ได้ xpath มาแล้ว
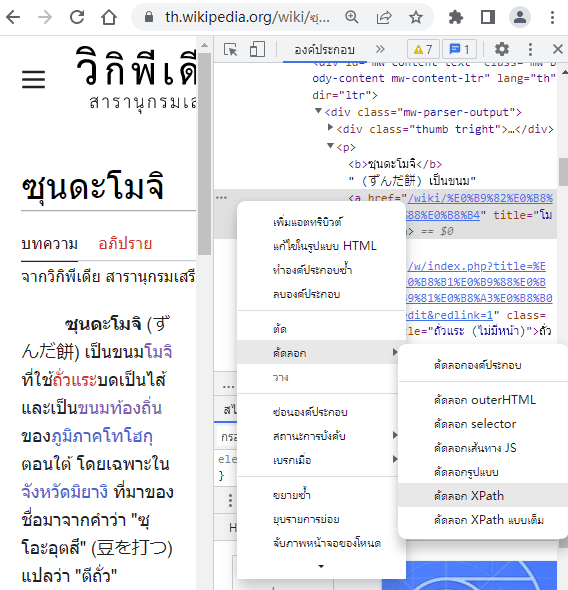
ลองเอา xpath ที่ได้จากตรงนี้มาใส่ในโค้ดเพื่อค้นหาส่วนประกอบนั้นๆได้
from selenium import webdriver
driver = webdriver.Chrome()
driver.get('https://th.wikipedia.org/wiki/ซุนดะโมจิ')
el = driver.find_element('xpath','//*[@id="mw-content-text"]/div[1]/p/a[1]')
print(el.get_attribute('href'))
print(el.text)
print(el.tag_name)ได้
https://th.wikipedia.org/wiki/%E0%B9%82%E0%B8%A1%E0%B8%88%E0%B8%B4
โมจิ
aการเปิดแท็บใหม่และเปลี่ยนแท็บไปมา
หากต้องการที่จะเปิดแท็บใหม่ขึ้นมาในหน้าต่างเบราว์เซอร์เดียวกันนั้นอาจทำได้โดยใช้เมธอด
.switch_to.new_window('tab')เช่นลองเปิดหน้ากูเกิลแล้วเปิดแท็บใหม่เป็นหน้าวิกิพีเดียขึ้นมา
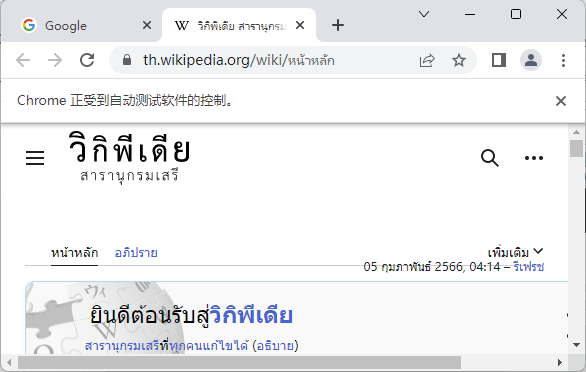
from selenium import webdriver
driver = webdriver.Chrome()
driver.get('https://www.google.co.th?hl=th') # หน้าเว็บในแท็บแรก
driver.switch_to.new_window('tab') # เปิดแท็บใหม่
driver.get('https://th.wikipedia.org') # หน้าเว็บในแท็บใหม่
print(driver.window_handles) # ได้ ['CDwindow-3A12304FDB753B8628A5EBCF6105A719', 'CDwindow-441F17D942BEFAA1AD2A2F044F24CC63']จะได้หน้าต่างแบบนี้
หรือหากต้องการสั่งให้เปิดแท็บใหม่แล้วเปิดหน้าเว็บในแท็บนั้นในทีเดียวเลยก็อาจทำได้โดยการใช้คำสั่งจาวาสคริปต์ผ่าน
.execute_script() ดังนี้driver.execute_script('window.open("https://th.wikipedia.org","_blank");')ออบเจ็กต์แท็บถูกเก็บอยู่ใน
driver.window_handles สามารถนำมาใช้ได้ เช่นในเวลาที่ต้องการสลับแท็บทำได้โดยใช้เมธอด .switch_to.window() โดยใส่ออบเจ็กต์ของแท็บที่ต้องการสลับเช่นอาจเปลี่ยนแท็บกลับมายังแท็บแรกได้โดย
driver.switch_to.window(driver.window_handles[0])หากต้องการปิดแท็บที่ดูอยู่ก็ทำได้โดยใช้เมธอด
.close()driver.close()เมธอด
.close() นั้นต่างจาก .quit() ตรงที่จะปิดแค่แท็บที่ดูอยู่เท่านั้น ในขณะที่ .quit() จะปิดทั้งหมดและยุติการทำงานของเบราว์เซอร์ลงนอกจากนี้แล้วหากต้องการจะเปิดหน้าต่างใหม่ไปเลย ไม่ใช่แค่เปิดแท็บใหม่ ก็ให้พิมพ์
'window' แทนที่จะเป็น 'tab'driver.switch_to.new_window('window')การเก็บค่าคุกกี้ค่าเซสชันของการล็อกอินเพื่อนำมาใช้ต่อเรื่อยๆ
หากใช้ selenium เราสามารถทำการล็อกอินเข้าเว็บได้โดยกรอกชื่อผู้ใช้และรหัสผ่านแล้วกดซับมิตแบบฟอร์ม เช่นในหน้าล็อกอินวิกิพีเดีย เป็นต้น
อย่างไรก็ตาม หากปิดเบราว์เซอร์ลงไปแล้วเข้ามาใหม่อีกรอบก็จะพบว่าต้องล็อกอินใหม่ นั่นเพราะว่าคุกกี้ของเซสชันของเบราว์เซอร์หลังจากล็อกอินไม่ได้ถูกบันทึกเก็บเอาไว้โดยอัตโนมัติเหมือนอย่างตอนที่ใช้เบราว์เซอร์เข้าเว็บตามปกติ
เพื่อที่จะให้เมื่อเปิดเบราว์เซอร์เข้าเว็บต่อไปสามารถใช้สถานะการล็อกอินจากครั้งที่แล้วได้โดยไม่ต้องล็อกอินใหม่เราจำเป็นจะต้องเขียนโค้ดเพื่อบันทึกเก็บคุกกี้ของค่าเซสชันที่ได้นั้นเอาไว้ ซึ่งสามารถทำได้โดยใช้เมธอด
.get_cookies() หลังจากที่ล็อกอินเสร็จแล้วเมื่อได้ค่าคุกกี้ทั้งหมดมาแล้วก็ให้บันทึกเก็บลงไฟล์ ซึ่งก็อาจมีทางเลือกหลายวิธีด้วยกันว่าจะเก็บในรูปแบบไหน
ในที่นี้จะเลือกเก็บเป็นไฟล์ pickle ซึ่งเป็นรูปแบบการเก็บออบเจ็กต์ที่ใช้ทั่วไปในไพธอน (รายละเอียดอ่านได้ที่ https://phyblas.hinaboshi.com/20190421)
ตัวอย่างโค้ดทำการล็อกอินเข้าวิกิพีเดียแล้วบันทึกคุกกี้ของเซสชันด้วย pickle
from selenium import webdriver
import pickle
driver = webdriver.Chrome()
driver.get('https://th.wikipedia.org/w/index.php?title=พิเศษ:ล็อกอิน')
# เติมชื่อผู้ใช้
name_box = driver.find_element('name','wpName')
name_box.send_keys('ชื่อผู้ใช้')
# เติมรหัสผ่าน
password_box = driver.find_element('name','wpPassword')
password_box.send_keys('รหัสผ่าน')
# กดติ๊กเพื่อให้อยู่ในระบบต่อไป
remember_box = driver.find_element('name','wpRemember')
remember_box.click()
name_box.submit() # ซับมิตแบบฟอร์มเพื่อล็อกอิน
cookies = driver.get_cookies() # ดึงคุ้กกี้หลังการล็อกอิน
pickle.dump(cookies,open('cookies.pkl','wb')) # บันทึกคุกกี้ลงไฟล์ด้วย pickle
driver.quit()เท่านี้ก็จะได้ไฟล์
cookies.pkl ซึ่งบรรจุคุกกี้ของเซสชันที่ล็อกอินไว้จากนั้นเราสามารถนำมาใช้ได้โดยโหลดคุกกี้จากไฟล์นี้มา แล้วทำการติดตั้งคุกกี้ลงบนเบราว์เซอร์โดยใช้เมธอด
.add_cookie()ตัวอย่างการใช้
from selenium import webdriver
import pickle
cookies = pickle.load(open('cookies.pkl','rb'))
driver = webdriver.Chrome()
driver.get('https://th.wikipedia.org/') # ให้เข้าเว็บก่อนครั้งนึง
for c in cookies: # ติดตั้งคุกกี้เข้าไป
driver.add_cookie(c)
driver.get('https://th.wikipedia.org/') # เปิดเว็บหลังจากที่ติดตั้งคุกกี้แล้วในที่นี้มีข้อควรระวังก็คือ ก่อนที่จะใช้
.add_cookie() นั้นจำเป็นต้องเข้าเว็บเดียวกันนั้นก่อน ไม่เช่นนั้นจะเกิดข้อผิดพลาดขึ้นมาเท่านี้เราก็จะสามารถเปิดเว็บในสภาพล็อกอินได้โดยไม่ต้องล็อกอินซ้ำไปมาทุกครั้งที่รัน selenium ใหม่
สรุปทิ้งท้าย
เมื่ออ่านมาถึงตรงนี้ก็คงจะช่วยให้เข้าใจวิธีการใช้ selenium ในเบื้องต้นและสามารถนำไปใช้งานอย่างง่ายๆกันได้แล้ว
ในที่นี้ขอสรุปเมธอดที่ใช้กับตัวออบเจ็กต์ driver ซึ่งได้กล่าวมาทั้งหมดไว้สักหน่อย
| .get() | เปิดหน้าเว็บที่ต้องการ |
| .quit() | ปิดเบราว์เซอร์ ยุติการใช้งาน |
| .close() | ปิดเฉพาะหน้าต่างหรือแท็กที่เลือกอยู่ |
| .switch_to.new_window() | เปิดหน้าต่างหรือแท็กใหม่ |
| .switch_to.window() | เปลี่ยนหน้าต่างหรือแท็ก |
| .back() | ย้อนกลับไปยังหน้าเก่า |
| .forward() | กลับไปยังหน้าก่อนที่จะย้อนมา |
| .refresh() | โหลดหน้าเว็บใหม่ |
| .save_screenshot() | บันทึกภาพหน้าจอเบราว์เซอร์เป็นไฟล .png |
| .get_screenshot_as_png() | ดึงเอาข้อมูลภาพหน้าจอเบราว์เซอร์ |
| .set_window_size() | ปรับขนาดหน้าต่าง |
| .execute_script() | รันโค้ดจาวาสคริปต์ในเบราว์เซอร์ |
| .find_element() | ค้นหาแท็กแรกที่หาเจอ |
| .find_elements() | ค้นหาแท็กทั้งหมดที่เจอ |
| .get_cookies() | ดูค่าคุกกี้ทั้งหมดใบเบราว์เซอร์ |
| .add_cookie() | ติดตั้งคุกกี้ลงในเบราว์เซอร์ |
และสุดท้ายนี้ขอเขียนตารางสรุปวิธีการค้นหาแท็กโดยใช้เมธอด
.find_element() และ .find_elements() ไว้| id | ค้นหาจาก ID ของแท็ก |
| name | ค้นหาจากแอตทริบิวต์ name ของแท็ก |
| class name | ค้นหาจากชื่อคลาสของแท็ก |
| tag name | ค้นหาจากชื่อแท็ก |
| css selector | ค้นหาจาก css ของแท็ก |
| link text | ค้นหาแท็กลิงก์ที่เป็นข้อความนั้น |
| partial link text | ค้นหาแท็กลิงก์ที่มีข้อความนั้นรวมอยู่ |
| xpath | ค้นหาโดยใช้ xpath |
อ้างอิง