pytorch เบื้องต้น บทที่ ๗: การสร้างเพอร์เซปตรอนหลายชั้น
เขียนเมื่อ 2018/09/08 10:13
แก้ไขล่าสุด 2022/07/09 15:42
>> ต่อจาก บทที่ ๖
บทที่ผ่านๆมาเป็นแค่การปูพื้นเพื่อให้เข้าใจหลักการทำงานคร่าวๆของ pytorch แต่ตั้งแต่บทนี้จะเป็นการนำมาสร้างเป็นโครงข่ายประสาทเทียมซึ่งประกอบด้วยหลายชั้นขึ้นจริงๆ
การสร้างโครงข่ายด้วยคลาส Module
โครงข่ายประสาทเทียมใน pytorch ปกติจะนิยามโดยสร้างคลาสขึ้นเป็นคลาสย่อยของคลาส torch.nn.Module
ภายในเมธอด __init__ จะมีการวางโครงสร้างว่าจะประกอบไปด้วยชั้นอะไรบ้าง
จากนั้นสร้างเมธอด forward เพื่อกำหนดลำดับการไหลของข้อมูลว่าจะให้มีการคำนวณยังไงในชั้นต่างๆ
ยกตัวอย่างเช่น หากต้องการสร้างโครงข่าย ๓ ชั้น ที่มีฟังก์ชันกระตุ้นเป็น ReLU จะเขียนได้ดังนี้
ฟังก์ชัน ReLU ในที่นี้สร้างขึ้นเตรียมไว้จากคลาส torch.nn.ReLU แต่จะใช้ฟังก์ชัน torch.nn.functional.relu() ก็ได้
คลาส Module ถูกสร้างขึ้นมาให้เวลาที่ถูกเรียกใช้โดยการเติม () ตามหลังจะไปเรียกเมธอดชื่อ forward ดังนั้นการที่ตั้งชื่อเมธอดว่า forward นี้เป็นการตั้งชื่อที่ตายตัว จะไปใช้ชื่ออื่นแทนไม่ได้
อันที่จริงตัว torch.nn.Linear เองก็เป็นคลาสย่อยของ torch.nn.Module
เมธอด .parameters() สำหรับคืนค่าของพารามิเตอร์ทุกตัวในชั้นก็เป็นเมธอดของคลาส Module
สำหรับ Module ทั่วไปที่นิยามขึ้นโดยบรรจุ Module อื่น (ในที่นี้คือ Linear) ไว้ภายในนั้น เมธอด .parameters() ซึ่งจะคืนค่าพารามิเตอร์ของทุก Module ภายในนั้น
__init__ ยังอาจนิยามโดยใช้เมธอด .add_module ได้ เช่นแก้เป็นแบบนี้
ผลที่ได้ไม่ต่างกัน แต่บางกรณีอาจสะดวกในการใช้มากกว่า เพราะชื่อของสายอักขระถูกป้อนในรูปของสายอักขระ
การใช้โครงข่ายที่นิยามขึ้นมา
ขอยกตัวอย่างเป็นปัญหาจำแนกข้อมูล ๔ กลุ่มที่แบ่งเป็นเชิงเส้นไม่ได้ แบบนี้
นำโครงข่ายที่สร้างไว้มาใช้ได้ดังนี้
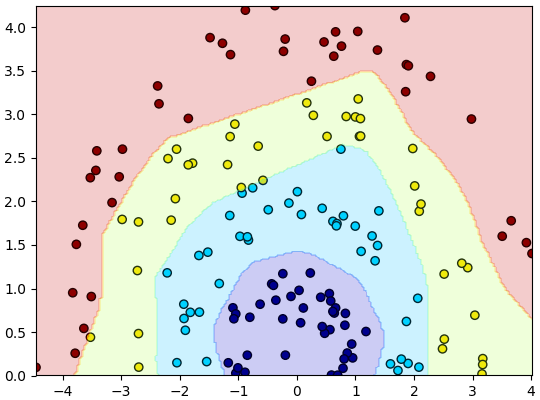
ถ้าเทียบกับตอนที่ใช้ lin แค่ตัวเดียวแล้ว วิธีการเขียนแทบจะเหมือนกัน แค่เปลี่ยนจาก lin ซึ่งเป็นแค่ชั้นคำนวณเชิงเส้นชั้นเดียวมาเป็น khrongkhai ซึ่งภายในประกอบด้วยหลายๆชั้น
เมธอด .parameters() นั้นทำการค้นหาพารามิเตอร์ที่อยู่ภายในชั้นย่อยทั้งหมดแล้วส่งให้กับออปทิไมเซอร์ พารามิเตอร์ทั้งหมดจึงถูกปรับค่า
การใช้ Sequential
การนิยามโครงข่ายตามตัวอย่างข้างต้นจะเห็นว่านอกจากกำหนดชั้นต่างๆขึ้นใน __init__ แล้วยังต้องกำหนดขั้นตอนการคำนวณใน forward อีก
แต่จะเห็นว่าขั้นตอนการคำนวณในที่นี้นั้นมีลักษณะค่อนข้างตายตัว นั่นคือเอาผลที่ได้จากการคำนวณแต่ละชั้นมาเข้าชั้นต่อไปคำนวณต่อไปเรื่อยๆ
กรณีแบบนี้มีวิธีที่สะดวกกว่านั้นเพื่อที่จะไม่ต้องมานิยาม forward นั่นคือใช้ torch.nn.Sequential
หากใช้แล้วจะสร้างโครงข่ายขึ้นได้ทันทีโดยไม่ต้องไปสร้างคลาสใหม่ ทำได้โดยแค่เขียนแบบนี้
กรณีนี้จำเป็นต้องป้อนทุกชั้นที่เป็นทางผ่าน แม้แต่ชั้นที่ไม่มีพารามิเตอร์อย่าง relu (ถ้าเป็นแบบเดิมแค่ใส่ตอน forward ก็พอ)
Sequential ก็เป็นคลาสย่อยของคลาส Module จึงมีคุณสมบัติต่างๆเหมือนกัน
พอเรียกใช้โครงข่ายก็จะเกิดการคำนวณตามลำดับที่ใส่ไป
ข้อดีคือไม่จำเป็นต้องไปตั้งชื่อให้กับแต่ละชั้น ถ้าดูข้อมูลภายในโครงข่ายจะเห็นว่าแต่ละตัวถูกแทนด้วยเลขตามลำดับ
ได้
เวลาจะเข้าถึงส่วนที่อยู่ด้านในก็ทำได้โดยใช้เลขลำดับเหมือนอาเรย์
นอกจากนี้ถ้าหากต้องการตั้งชื่อให้กับแต่ละชั้นเพื่อจะได้อ้างอิงได้สะดวก ก็อาจใช้คำสั่ง .add_module() ได้เช่นกัน
พอทำแบบนี้ก็จะมีชื่อติด เวลาจะเข้าถึงจะใช้เลขลำดับหรือชื่อก็ได้
ได้
Module ซ้อน Module
โครงข่ายถูกนิยามได้จากการนำออบเจ็กต์คลาส Module หลายตัวมาใส่รวมกัน แต่โครงข่ายที่นิยามขึ้นก็เป็นคลาส Module ดังนั้นจึงถูกนำมาใช้เป็นส่วนประกอบย่อยของโครงข่ายที่ใหญ่ขึ้นอีกได้เช่นกัน
เช่น
ได้
โครงข่ายแบบนี้ก็ทำการคำนวณตามลำดับได้เช่นกัน บางทีการแบ่งเป็นชั้นย่อยๆซ้อนกันอาจทำให้เข้าใจง่ายขึ้น
สร้างชั้นปรับรูปร่างเทนเซอร์
ถ้าการคำนวณภายในโครงข่ายเป็นไปตามลำดับขั้นเรียบง่ายก็ใช้ Sequential ได้สบาย แต่ก็ไม่ได้ใช้แบบนั้นเสมอไป เช่นกรณีโครข่ายที่มีการแยกสายหรือการเชื่อมรวม
สำหรับกรณีปัญหาจำแนกข้อมูลแค่ ๒ กลุ่มซึ่งเรามักจะต้องการคำตอบแค่ตัวเดียวนั้น มักจะต้องปิดท้ายด้วยการปรับลดมิติเทนเซอร์ให้เหลือมิติเดียวโดยใช้ .flatten
หากต้องการจะปรับลดมิติหรือเปลี่ยนรูปร่างในระหว่างชั้นคำนวณโดย Sequential ก็ทำได้ เพียงแต่สิ่งที่จะใส่ใน Sequential ได้ต้องเป็นออบเจ็กต์ของคลาส Module เท่านั้น และ pytorch ไม่ได้เตรียม Module สำหรับเปลี่ยนรูปร่างเทนเซอร์ไว้ให้ ทำให้ต้องสร้างขึ้นเอง
การสร้างทำได้ไม่ยาก แค่นิยามส่วน forward ให้ใช้เมธอด .flatten() กับตัวแปรที่รับมา
อย่างไรก็ตาม ที่จริงมีวิธีที่สั้นกว่านั้น คือใช้ lambda
อาจลองสร้างโครงข่าย ๓ ชั้นในลักษณะนี้
แล้วลองนำมาใช้ดู
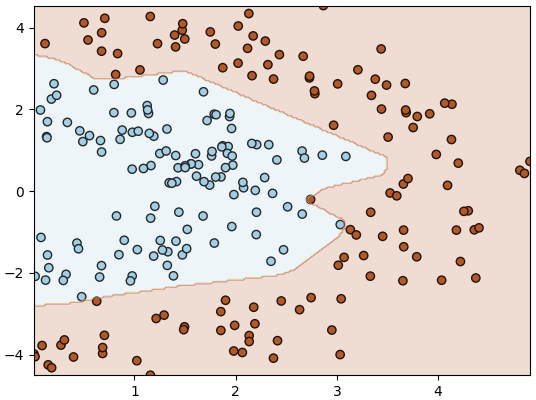
>> อ่านต่อ บทที่ ๘
บทที่ผ่านๆมาเป็นแค่การปูพื้นเพื่อให้เข้าใจหลักการทำงานคร่าวๆของ pytorch แต่ตั้งแต่บทนี้จะเป็นการนำมาสร้างเป็นโครงข่ายประสาทเทียมซึ่งประกอบด้วยหลายชั้นขึ้นจริงๆ
การสร้างโครงข่ายด้วยคลาส Module
โครงข่ายประสาทเทียมใน pytorch ปกติจะนิยามโดยสร้างคลาสขึ้นเป็นคลาสย่อยของคลาส torch.nn.Module
ภายในเมธอด __init__ จะมีการวางโครงสร้างว่าจะประกอบไปด้วยชั้นอะไรบ้าง
จากนั้นสร้างเมธอด forward เพื่อกำหนดลำดับการไหลของข้อมูลว่าจะให้มีการคำนวณยังไงในชั้นต่างๆ
ยกตัวอย่างเช่น หากต้องการสร้างโครงข่าย ๓ ชั้น ที่มีฟังก์ชันกระตุ้นเป็น ReLU จะเขียนได้ดังนี้
import torch
relu = torch.nn.ReLU()
class Khrongkhai(torch.nn.Module):
def __init__(self,m0,m1,m2,m3):
super(Khrongkhai,self).__init__()
self.lin1 = torch.nn.Linear(m0,m1)
self.lin2 = torch.nn.Linear(m1,m2)
self.lin3 = torch.nn.Linear(m2,m3)
def forward(self,x):
a1 = self.lin1(x)
h1 = relu(a1)
a2 = self.lin2(h1)
h2 = relu(a2)
a3 = self.lin3(h2)
return a3ฟังก์ชัน ReLU ในที่นี้สร้างขึ้นเตรียมไว้จากคลาส torch.nn.ReLU แต่จะใช้ฟังก์ชัน torch.nn.functional.relu() ก็ได้
คลาส Module ถูกสร้างขึ้นมาให้เวลาที่ถูกเรียกใช้โดยการเติม () ตามหลังจะไปเรียกเมธอดชื่อ forward ดังนั้นการที่ตั้งชื่อเมธอดว่า forward นี้เป็นการตั้งชื่อที่ตายตัว จะไปใช้ชื่ออื่นแทนไม่ได้
อันที่จริงตัว torch.nn.Linear เองก็เป็นคลาสย่อยของ torch.nn.Module
print(issubclass(torch.nn.Linear,torch.nn.Module)) # ได้ Trueเมธอด .parameters() สำหรับคืนค่าของพารามิเตอร์ทุกตัวในชั้นก็เป็นเมธอดของคลาส Module
สำหรับ Module ทั่วไปที่นิยามขึ้นโดยบรรจุ Module อื่น (ในที่นี้คือ Linear) ไว้ภายในนั้น เมธอด .parameters() ซึ่งจะคืนค่าพารามิเตอร์ของทุก Module ภายในนั้น
khrongkhai = Khrongkhai(1,1,1,1)
print(len(list(khrongkhai.parameters()))) # ได้ 6__init__ ยังอาจนิยามโดยใช้เมธอด .add_module ได้ เช่นแก้เป็นแบบนี้
def __init__(self,m0,m1,m2,m3):
super(Khrongkhai,self).__init__()
self.add_module('lin1',torch.nn.Linear(m0,m1))
self.add_module('lin2',torch.nn.Linear(m1,m2))
self.add_module('lin3',torch.nn.Linear(m2,m3))ผลที่ได้ไม่ต่างกัน แต่บางกรณีอาจสะดวกในการใช้มากกว่า เพราะชื่อของสายอักขระถูกป้อนในรูปของสายอักขระ
การใช้โครงข่ายที่นิยามขึ้นมา
ขอยกตัวอย่างเป็นปัญหาจำแนกข้อมูล ๔ กลุ่มที่แบ่งเป็นเชิงเส้นไม่ได้ แบบนี้
import numpy as np
import matplotlib.pyplot as plt
z = np.arange(4).repeat(40)
r = np.random.normal(z+1,0.25)
t = np.random.uniform(0,np.pi,160)
x = r*np.cos(t)
y = r*np.sin(t)
X = np.array([x,y]).T
plt.scatter(x,y,c=z,edgecolor='k',cmap='jet')
plt.show()นำโครงข่ายที่สร้างไว้มาใช้ได้ดังนี้
ha_entropy = torch.nn.CrossEntropyLoss()
X = torch.Tensor(X)
z = torch.LongTensor(z)
khrongkhai = Khrongkhai(2,60,40,4)
opt = torch.optim.Adam(khrongkhai.parameters(),lr=0.1)
ha_entropy = torch.nn.CrossEntropyLoss()
for i in range(200):
a = khrongkhai(X)
J = ha_entropy(a,z)
J.backward()
opt.step()
opt.zero_grad()
mx,my = np.meshgrid(np.linspace(x.min(),x.max(),200),np.linspace(y.min(),y.max(),200))
mX = torch.Tensor(np.array([mx.ravel(),my.ravel()]).T)
mz = khrongkhai(mX).argmax(1)
mz = mz.data.numpy().reshape(200,200)
plt.xlim(x.min(),x.max())
plt.ylim(y.min(),y.max())
plt.scatter(x,y,c=z,edgecolor='k',cmap='jet')
plt.contourf(mx,my,mz,alpha=0.2,cmap='jet')
plt.show()ถ้าเทียบกับตอนที่ใช้ lin แค่ตัวเดียวแล้ว วิธีการเขียนแทบจะเหมือนกัน แค่เปลี่ยนจาก lin ซึ่งเป็นแค่ชั้นคำนวณเชิงเส้นชั้นเดียวมาเป็น khrongkhai ซึ่งภายในประกอบด้วยหลายๆชั้น
เมธอด .parameters() นั้นทำการค้นหาพารามิเตอร์ที่อยู่ภายในชั้นย่อยทั้งหมดแล้วส่งให้กับออปทิไมเซอร์ พารามิเตอร์ทั้งหมดจึงถูกปรับค่า
การใช้ Sequential
การนิยามโครงข่ายตามตัวอย่างข้างต้นจะเห็นว่านอกจากกำหนดชั้นต่างๆขึ้นใน __init__ แล้วยังต้องกำหนดขั้นตอนการคำนวณใน forward อีก
แต่จะเห็นว่าขั้นตอนการคำนวณในที่นี้นั้นมีลักษณะค่อนข้างตายตัว นั่นคือเอาผลที่ได้จากการคำนวณแต่ละชั้นมาเข้าชั้นต่อไปคำนวณต่อไปเรื่อยๆ
กรณีแบบนี้มีวิธีที่สะดวกกว่านั้นเพื่อที่จะไม่ต้องมานิยาม forward นั่นคือใช้ torch.nn.Sequential
หากใช้แล้วจะสร้างโครงข่ายขึ้นได้ทันทีโดยไม่ต้องไปสร้างคลาสใหม่ ทำได้โดยแค่เขียนแบบนี้
khrongkhai = torch.nn.Sequential(
torch.nn.Linear(2,60),
relu,
torch.nn.Linear(60,40),
relu,
torch.nn.Linear(40,4)
)กรณีนี้จำเป็นต้องป้อนทุกชั้นที่เป็นทางผ่าน แม้แต่ชั้นที่ไม่มีพารามิเตอร์อย่าง relu (ถ้าเป็นแบบเดิมแค่ใส่ตอน forward ก็พอ)
Sequential ก็เป็นคลาสย่อยของคลาส Module จึงมีคุณสมบัติต่างๆเหมือนกัน
พอเรียกใช้โครงข่ายก็จะเกิดการคำนวณตามลำดับที่ใส่ไป
ข้อดีคือไม่จำเป็นต้องไปตั้งชื่อให้กับแต่ละชั้น ถ้าดูข้อมูลภายในโครงข่ายจะเห็นว่าแต่ละตัวถูกแทนด้วยเลขตามลำดับ
print(khrongkhai)ได้
Sequential(
(0): Linear(in_features=2, out_features=60, bias=True)
(1): ReLU()
(2): Linear(in_features=60, out_features=40, bias=True)
(3): ReLU()
(4): Linear(in_features=40, out_features=4, bias=True)
)เวลาจะเข้าถึงส่วนที่อยู่ด้านในก็ทำได้โดยใช้เลขลำดับเหมือนอาเรย์
print(khrongkhai[0]) # ได้ Linear(in_features=2, out_features=60, bias=True)นอกจากนี้ถ้าหากต้องการตั้งชื่อให้กับแต่ละชั้นเพื่อจะได้อ้างอิงได้สะดวก ก็อาจใช้คำสั่ง .add_module() ได้เช่นกัน
khrongkhai = torch.nn.Sequential()
khrongkhai.add_module('lin1',torch.nn.Linear(2,60))
# หรือ khrongkhai.lin1 = torch.nn.Linear(2,60)
khrongkhai.add_module('relu1',relu)
khrongkhai.add_module('lin2',torch.nn.Linear(60,40))
khrongkhai.add_module('relu2',relu)
khrongkhai.add_module('lin3',torch.nn.Linear(40,4))พอทำแบบนี้ก็จะมีชื่อติด เวลาจะเข้าถึงจะใช้เลขลำดับหรือชื่อก็ได้
print(khrongkhai)
print(khrongkhai.lin2) # หรือ khrongkhai[2]ได้
Sequential(
(lin1): Linear(in_features=2, out_features=60, bias=True)
(relu1): ReLU()
(lin2): Linear(in_features=60, out_features=40, bias=True)
(relu2): ReLU()
(lin3): Linear(in_features=40, out_features=4, bias=True)
)
Linear(in_features=60, out_features=40, bias=True)Module ซ้อน Module
โครงข่ายถูกนิยามได้จากการนำออบเจ็กต์คลาส Module หลายตัวมาใส่รวมกัน แต่โครงข่ายที่นิยามขึ้นก็เป็นคลาส Module ดังนั้นจึงถูกนำมาใช้เป็นส่วนประกอบย่อยของโครงข่ายที่ใหญ่ขึ้นอีกได้เช่นกัน
เช่น
l1 = torch.nn.Sequential(torch.nn.Linear(2,60),relu)
l2 = torch.nn.Sequential(torch.nn.Linear(60,40),relu)
l3 = torch.nn.Linear(40,4)
khrongkhai = torch.nn.Sequential(l1,l2,l3)
print(khrongkhai)ได้
Sequential(
(0): Sequential(
(0): Linear(in_features=2, out_features=60, bias=True)
(1): ReLU()
)
(1): Sequential(
(0): Linear(in_features=60, out_features=40, bias=True)
(1): ReLU()
)
(2): Linear(in_features=40, out_features=4, bias=True)
)โครงข่ายแบบนี้ก็ทำการคำนวณตามลำดับได้เช่นกัน บางทีการแบ่งเป็นชั้นย่อยๆซ้อนกันอาจทำให้เข้าใจง่ายขึ้น
สร้างชั้นปรับรูปร่างเทนเซอร์
ถ้าการคำนวณภายในโครงข่ายเป็นไปตามลำดับขั้นเรียบง่ายก็ใช้ Sequential ได้สบาย แต่ก็ไม่ได้ใช้แบบนั้นเสมอไป เช่นกรณีโครข่ายที่มีการแยกสายหรือการเชื่อมรวม
สำหรับกรณีปัญหาจำแนกข้อมูลแค่ ๒ กลุ่มซึ่งเรามักจะต้องการคำตอบแค่ตัวเดียวนั้น มักจะต้องปิดท้ายด้วยการปรับลดมิติเทนเซอร์ให้เหลือมิติเดียวโดยใช้ .flatten
หากต้องการจะปรับลดมิติหรือเปลี่ยนรูปร่างในระหว่างชั้นคำนวณโดย Sequential ก็ทำได้ เพียงแต่สิ่งที่จะใส่ใน Sequential ได้ต้องเป็นออบเจ็กต์ของคลาส Module เท่านั้น และ pytorch ไม่ได้เตรียม Module สำหรับเปลี่ยนรูปร่างเทนเซอร์ไว้ให้ ทำให้ต้องสร้างขึ้นเอง
การสร้างทำได้ไม่ยาก แค่นิยามส่วน forward ให้ใช้เมธอด .flatten() กับตัวแปรที่รับมา
class Flatten(torch.nn.Module):
def forward(self,x):
return x.flatten()
flat = Flatten()อย่างไรก็ตาม ที่จริงมีวิธีที่สั้นกว่านั้น คือใช้ lambda
flat = torch.nn.Module()
flat.forward = lambda x:x.flatten()อาจลองสร้างโครงข่าย ๓ ชั้นในลักษณะนี้
khrongkhai = torch.nn.Sequential(
torch.nn.Linear(2,80),
relu,
torch.nn.Linear(80,50),
relu,
torch.nn.Linear(50,1),
flat)แล้วลองนำมาใช้ดู
z = np.arange(2).repeat(120)
r = np.random.normal(z*2+2,0.5)
t = np.random.uniform(-0.5,0.5,240)*np.pi
x,y = r*np.cos(t),r*np.sin(t)
X = np.array([x,y]).T
X = torch.Tensor(X)
z = torch.Tensor(z)
opt = torch.optim.Adam(khrongkhai.parameters(),lr=0.1)
ha_entropy = torch.nn.BCEWithLogitsLoss()
for i in range(200):
a = khrongkhai(X)
J = ha_entropy(a,z)
J.backward()
opt.step()
opt.zero_grad()
mx,my = np.meshgrid(np.linspace(x.min(),x.max(),200),np.linspace(y.min(),y.max(),200))
mX = torch.Tensor(np.array([mx.ravel(),my.ravel()]).T)
mz = khrongkhai(mX)>0
mz = mz.data.numpy().reshape(200,200)
plt.xlim(x.min(),x.max())
plt.ylim(y.min(),y.max())
plt.scatter(x,y,c=z.data.numpy(),edgecolor='k',cmap='Paired')
plt.contourf(mx,my,mz,alpha=0.2,cmap='Paired')
plt.show()>> อ่านต่อ บทที่ ๘
-----------------------------------------
囧囧囧囧囧囧囧囧囧囧囧囧囧囧囧囧囧囧囧囧囧囧囧囧囧
หมวดหมู่
-- คอมพิวเตอร์ >> ปัญญาประดิษฐ์ >> โครงข่ายประสาทเทียม-- คอมพิวเตอร์ >> เขียนโปรแกรม >> python >> pytorch