โครงข่ายประสาทเทียมเบื้องต้น บทที่ ๑๖: การแบ่งข้อมูลฝึกและข้อมูลตรวจสอบ
เขียนเมื่อ 2018/08/26 23:35
แก้ไขล่าสุด 2021/09/28 16:42
>> ต่อจาก บทที่ ๑๕
ในบทที่ผ่านมาเราใช้ข้อมูลทั้งหมดที่มีในการเรียนรู้แล้วก็พิจารณาคะแนนที่ได้จากการทำนายข้อมูลชุดนั้นเอง
แต่ว่าในความเป็นจริงแล้วเราไม่ได้ให้โปรแกรมเรียนรู้เพื่อที่จะให้ทำนายแค่ข้อมูลชุดนั้น แต่ต้องให้สามารถทำนายข้อมูลที่ไม่เคยใช้เรียนรู้ด้วย
การที่โปรแกรมสามารถทำนายข้อมูลที่ใช้เรียนรู้ได้อย่างถูกต้องแต่กลับทำนายข้อมูลชุดอื่นไม่ค่อยได้ดีนักแบบนั้นเรียกว่าการเรียนรู้เกิน (过学习, overlearning) แบบนั้นไม่สามารถเอาไปใช้งานได้จริงในสถานการณ์จริง
ดังนั้นโดยทั่วไปแล้วนอกจากจะมีข้อมูลสำหรับใช้ฝึกแล้วจำเป็นต้องมีข้อมูลส่วนหนึ่งไว้ใช้เพื่อตรวจสอบ และอาจใช้เพื่อเป็นเงื่อนไขในการหยุดด้วย
ลองเขียนคลาสของโครงข่ายประสาทเทียมขึ้นใหม่ โดยเขียนให้รับข้อมูลส่วนหนึ่งมาใช้เป็นข้อมูลตรวจสอบ แล้วให้เลือกใช้เป็นเงื่อนไขในการหยุดได้ด้วย
เขียนได้ดังนี้ (เช่นเคย ให้โหลดคลาสต่างๆจาก unagi.py ก่อน)
ลองนำมาใช้ทำนายชุดข้อมูลรูปร่างต่างๆ >> https://phyblas.hinaboshi.com/triamhai/ruprang-raisi-25x25x1000x5.rar
อ่านข้อมูลรูปภาพทั้ง 5000 รูป โดยแบ่ง 4000 รูปไว้เป็นข้อมูลฝึก อีก 1000 รูปไว้เป็นข้อมูลตรวจสอบ ตั้งเงื่อนไขให้หยุดเมื่อคะแนนในการทายข้อมูลตรวจสอบไม่เพิ่มขึ้นเลย ๒๐ รอบ
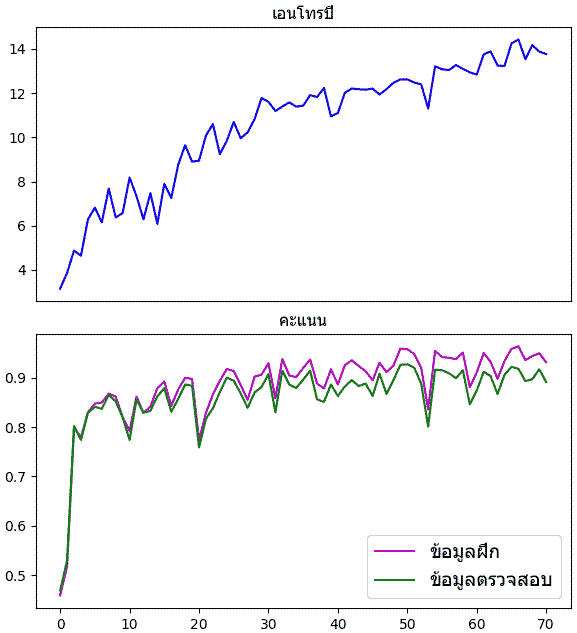
จะเห็นว่าความแม่นในการทายชุดข้อมูลฝึกจะมากกว่าชุดข้อมูลตรวจสอบเสมอ
แต่ในตัวอย่างนี้ความแตกต่างไม่มากเกินไปนักเพราะจำนวนข้อมูลฝึกมีมากพอ จึงไม่มีปัญหาการเรียนรู้เกิน แต่ปัญหาจะเด่นชัดขึ้นหากข้อมูลมีจำนวนน้อย
ลองลดข้อมูลลงสิบเท่าแล้วฝึกใหม่
จากนั้นก็เอาผลมาวาดกราฟเหมือนเดิมจะได้ผลแบบนี้
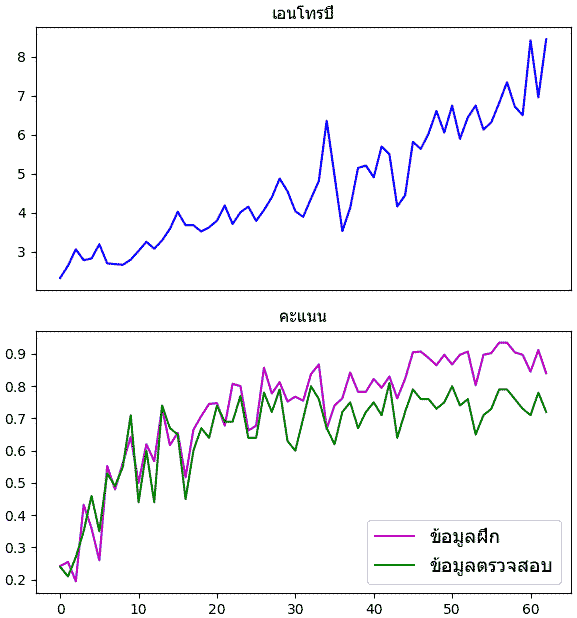
จะเห็นได้ว่าความแตกต่างระหว่างข้อมูลฝึกและตรวจสอบดูชัดเจนมากขึ้น
วิธีในการแก้เรื่องการเรียนรู้เกินมีหลายวิธีด้วยกัน วิธีหนึ่งก็คือเพิ่มจำนวนข้อมูล เพราะยิ่งมีตัวอย่างมากแบบจำลองของเราก็จะยิ่งเข้าใจได้ง่ายว่าเกณฑ์ทั่วไปควรจะเป็นยังไง
แต่ก็ไม่ใช่ว่าเราจะสามารถมีข้อมูลมากเหลือเฟือเสมอไป
สำหรับโครงข่ายประสาทเทียม วิธีหนึ่งที่นิยมใช้มากในการแก้ปัญหาการเรียนรู้เกินก็คือ ดรอปเอาต์ (dropout)
>> อ่านต่อ บทที่ ๑๗
ในบทที่ผ่านมาเราใช้ข้อมูลทั้งหมดที่มีในการเรียนรู้แล้วก็พิจารณาคะแนนที่ได้จากการทำนายข้อมูลชุดนั้นเอง
แต่ว่าในความเป็นจริงแล้วเราไม่ได้ให้โปรแกรมเรียนรู้เพื่อที่จะให้ทำนายแค่ข้อมูลชุดนั้น แต่ต้องให้สามารถทำนายข้อมูลที่ไม่เคยใช้เรียนรู้ด้วย
การที่โปรแกรมสามารถทำนายข้อมูลที่ใช้เรียนรู้ได้อย่างถูกต้องแต่กลับทำนายข้อมูลชุดอื่นไม่ค่อยได้ดีนักแบบนั้นเรียกว่าการเรียนรู้เกิน (过学习, overlearning) แบบนั้นไม่สามารถเอาไปใช้งานได้จริงในสถานการณ์จริง
ดังนั้นโดยทั่วไปแล้วนอกจากจะมีข้อมูลสำหรับใช้ฝึกแล้วจำเป็นต้องมีข้อมูลส่วนหนึ่งไว้ใช้เพื่อตรวจสอบ และอาจใช้เพื่อเป็นเงื่อนไขในการหยุดด้วย
ลองเขียนคลาสของโครงข่ายประสาทเทียมขึ้นใหม่ โดยเขียนให้รับข้อมูลส่วนหนึ่งมาใช้เป็นข้อมูลตรวจสอบ แล้วให้เลือกใช้เป็นเงื่อนไขในการหยุดได้ด้วย
เขียนได้ดังนี้ (เช่นเคย ให้โหลดคลาสต่างๆจาก unagi.py ก่อน)
import numpy as np
import matplotlib.pyplot as plt
from unagi import Affin,Relu,Softmax_entropy,ha_1h,Adam
class Prasat:
def __init__(self,m,eta):
self.m = m
self.chan = []
for i in range(len(m)-1):
self.chan.append(Affin(m[i],m[i+1],np.sqrt(2./m[i])))
if(i<len(m)-2):
self.chan.append(Relu())
self.chan.append(Softmax_entropy())
self.opt = Adam(self.param(),eta=eta)
def rianru(self,X,z,X_truat,z_truat,n_thamsam=100,n_batch=50,ro=0):
n = len(z)
Z = ha_1h(z,self.m[-1])
self.entropy = []
self.khanaen_fuek = []
self.khanaen_truat = []
khanaen_sungsut = 0
for o in range(n_thamsam):
lueak = np.random.permutation(n)
for i in range(0,n,n_batch):
Xb = X[lueak[i:i+n_batch]]
Zb = Z[lueak[i:i+n_batch]]
entropy = self.ha_entropy(Xb,Zb)
entropy.phraeyon()
self.opt()
entropy,khanaen_fuek = self.ha_entropy(X,Z,ao_khanaen=1)
khanaen_truat = self.ha_khanaen(X_truat,z_truat)
self.entropy.append(entropy.kha)
self.khanaen_fuek.append(khanaen_fuek)
self.khanaen_truat.append(khanaen_truat)
print(u'รอบที่ %d. เอนโทรปี=%.2f, ทำนายข้อมูลฝึกแม่น=%.2f, ทำนายข้อมูลตรวจสอบแม่น=%.2f'%(o,entropy.kha,khanaen_fuek,khanaen_truat))
if(khanaen_truat>khanaen_sungsut):
khanaen_sungsut = khanaen_truat
maiphoem = 0
else:
maiphoem += 1
if(ro>0 and maiphoem>=ro):
break
def ha_entropy(self,X,Z,ao_khanaen=0):
for c in self.chan[:-1]:
X = c(X)
if(ao_khanaen):
return self.chan[-1](X,Z),(X.kha.argmax(1)==Z.argmax(1)).mean()
return self.chan[-1](X,Z)
def ha_khanaen(self,X,z):
return (self.thamnai(X)==z).mean()
def param(self):
p = []
for c in self.chan:
if(hasattr(c,'param')):
p.extend(c.param)
return p
def thamnai(self,X):
for c in self.chan[:-1]:
X = c(X)
return X.kha.argmax(1)
ลองนำมาใช้ทำนายชุดข้อมูลรูปร่างต่างๆ >> https://phyblas.hinaboshi.com/triamhai/ruprang-raisi-25x25x1000x5.rar
อ่านข้อมูลรูปภาพทั้ง 5000 รูป โดยแบ่ง 4000 รูปไว้เป็นข้อมูลฝึก อีก 1000 รูปไว้เป็นข้อมูลตรวจสอบ ตั้งเงื่อนไขให้หยุดเมื่อคะแนนในการทายข้อมูลตรวจสอบไม่เพิ่มขึ้นเลย ๒๐ รอบ
from glob import glob
n = 1000
X = np.array([plt.imread(x) for x in sorted(glob('ruprang-raisi-25x25x1000x5/*/*.png'))])
X = X.reshape(-1,25*25)
z = np.arange(5).repeat(n)
np.random.seed(1)
sumlueak = np.random.permutation(5*n)
X_fuek,X_truat = X[sumlueak[:4000]],X[sumlueak[4000:]]
z_fuek,z_truat = z[sumlueak[:4000]],z[sumlueak[4000:]]
prasat = Prasat(m=[625,100,100,50,6],eta=0.002)
prasat.rianru(X_fuek,z_fuek,X_truat,z_truat,n_thamsam=200,n_batch=64,ro=20)
plt.figure(figsize=[6,8])
plt.subplot(211,xticks=[])
plt.plot(prasat.entropy,'b')
plt.title(u'เอนโทรปี',family='Tahoma',size=12)
plt.subplot(212)
plt.plot(prasat.khanaen_fuek,'m')
plt.plot(prasat.khanaen_truat,'g')
plt.title(u'คะแนน',family='Tahoma',size=12)
plt.legend([u'ข้อมูลฝึก',u'ข้อมูลตรวจสอบ'],prop={'family':'Tahoma','size':14})
plt.tight_layout()
plt.show()จะเห็นว่าความแม่นในการทายชุดข้อมูลฝึกจะมากกว่าชุดข้อมูลตรวจสอบเสมอ
แต่ในตัวอย่างนี้ความแตกต่างไม่มากเกินไปนักเพราะจำนวนข้อมูลฝึกมีมากพอ จึงไม่มีปัญหาการเรียนรู้เกิน แต่ปัญหาจะเด่นชัดขึ้นหากข้อมูลมีจำนวนน้อย
ลองลดข้อมูลลงสิบเท่าแล้วฝึกใหม่
X_fuek,X_truat,z_fuek,z_truat = X_fuek[::10],X_truat[::10],z_fuek[::10],z_truat[::10]
prasat = Prasat(m=[625,100,100,50,6],eta=0.002)
prasat.rianru(X_fuek,z_fuek,X_truat,z_truat,n_thamsam=200,n_batch=64,ro=20)จากนั้นก็เอาผลมาวาดกราฟเหมือนเดิมจะได้ผลแบบนี้
จะเห็นได้ว่าความแตกต่างระหว่างข้อมูลฝึกและตรวจสอบดูชัดเจนมากขึ้น
วิธีในการแก้เรื่องการเรียนรู้เกินมีหลายวิธีด้วยกัน วิธีหนึ่งก็คือเพิ่มจำนวนข้อมูล เพราะยิ่งมีตัวอย่างมากแบบจำลองของเราก็จะยิ่งเข้าใจได้ง่ายว่าเกณฑ์ทั่วไปควรจะเป็นยังไง
แต่ก็ไม่ใช่ว่าเราจะสามารถมีข้อมูลมากเหลือเฟือเสมอไป
สำหรับโครงข่ายประสาทเทียม วิธีหนึ่งที่นิยมใช้มากในการแก้ปัญหาการเรียนรู้เกินก็คือ ดรอปเอาต์ (dropout)
>> อ่านต่อ บทที่ ๑๗
-----------------------------------------
囧囧囧囧囧囧囧囧囧囧囧囧囧囧囧囧囧囧囧囧囧囧囧囧囧
หมวดหมู่
-- คอมพิวเตอร์ >> ปัญญาประดิษฐ์ >> โครงข่ายประสาทเทียม-- คอมพิวเตอร์ >> เขียนโปรแกรม >> python >> numpy