[python] การตรวจสอบแบบไขว้ k-fold เพื่อสลับเวียนข้อมูลที่ใช้ในการฝึกฝนและตรวจสอบ
เขียนเมื่อ 2017/10/18 00:42
แก้ไขล่าสุด 2022/07/21 14:53
ก่อนหน้านี้ได้พูดถึงการแยกข้อมูลฝึกกับข้อมูลทดสอบไป https://phyblas.hinaboshi.com/20170924
อย่างไรก็ตาม การแยกข้อมูลทดสอบแค่เพียงครั้งเดียวอาจไม่สามารถยืนยันความแม่นยำของโปรแกรมได้ดีพอก็เป็นได้ เพราะอาจจะแค่บังเอิญว่าข้อมูลที่หยิบมาใช้ฝึกกับทดสอบนั้นกระจายตัวไม่ดีพอ
ดังนั้นจึงมีคนคิดวิธีการที่ว่าให้นำข้อมูลที่มีอยู่สลับกันใช้เป็นข้อมูลฝึกและเป็นข้อมูลทดสอบ ทำซ้ำๆหลายๆครั้ง เปรียบเทียบผลในแต่ละรอบ
การทำแบบนี้เรียกว่า "การตรวจสอบแบบไขว้" (交叉验证, cross validation) ไขว้ในที่นี้หมายถึงมีการสลับสับเปลี่ยนข้อมูลไปมา
วิธีการหนึ่งที่นิยมก็คือวิธีที่เรียกว่า k-fold คือการแบ่งข้อมูลออกเป็นกลุ่ม k กลุ่ม (ในที่นี้ k แทนจำนวนกลุ่ม)
แบ่งแล้วก็ทำการทดลองฝึก k ครั้ง โดยครั้งแรกให้ข้อมูลกลุ่มแรกเป็นข้อมูลตรวจสอบ ที่เหลือเป็นข้อมูลฝึกฝน ครั้งต่อมาให้กลุ่มที่ ๒ เป็นข้อมูลตรวจสอบ แล้วก็ไล่ไปเรื่อยๆจนทุกกลุ่มถูกใช้เป็นข้อมูลทดสอบทั้งหมด
สุดท้ายก็นำประสิทธิภาพที่ได้จากการฝึก k ครั้งมาหาค่าเฉลี่ย แล้วก็หาส่วนเบี่ยงเบนมาตรฐานด้วย ก็จะได้ผลที่บอกได้ว่าผลการฝึกที่เราได้นั้นมีความแม่นยำอยู่ในช่วงประมาณเท่าไหร่
ภาพแสดงตัวอย่างให้เห็น สมมุติว่าข้อมูลมีทั้งหมด ๑๔ ต้องการแบ่งเป็น ๕ กลุ่ม ก็จะทำได้ดังนี้ แต่ละแถวแทนแต่ละรอบ โดยพื้นที่มีแสงคือส่วนที่เลือกไปเป็นข้อมูลตรวจสอบ ส่วนสีเขียวคือข้อมูลฝึกฝน

ตัวอย่างการใช้ เริ่มจากสร้างชุดข้อมูลเป็นกลุ่มก้อน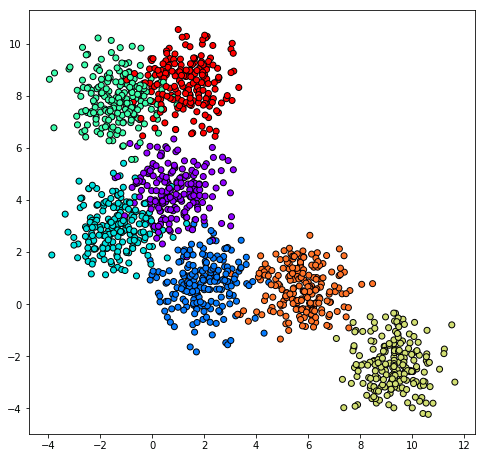
จากนั้นจะให้โปรแกรมแกรมลองแบ่งกลุ่มข้อมูลด้วยการถดถอยโลจิสติกโดยใช้คลาสที่ลงไว้ใน https://phyblas.hinaboshi.com/20171006
โหลดตัวไฟล์ที่นิยามคลาสไว้ได้ใน https://gist.github.com/phyblas/e65d8f2dc813b0d9289431a1061428fb
ทดสอบการเรียนรู้ด้วยวิธี k-fold ลองเขียนดูได้ดังนี้
คำสั่ง np.roll เป็นการหมุนเลื่อนการจัดเรียงแถวในอาเรย์ ในที่นี้ใช้เพื่อเปลี่ยนตัวขึ้นต้น
maen_fuek กับ maen_truat คือค่าความแม่นในการทายผลของข้อมูลฝึกกับข้อมูลตรวจสอบซึ่งได้บันทึกไว้ระหว่างเรียนรู้
ลองเอามาวาดกราฟดู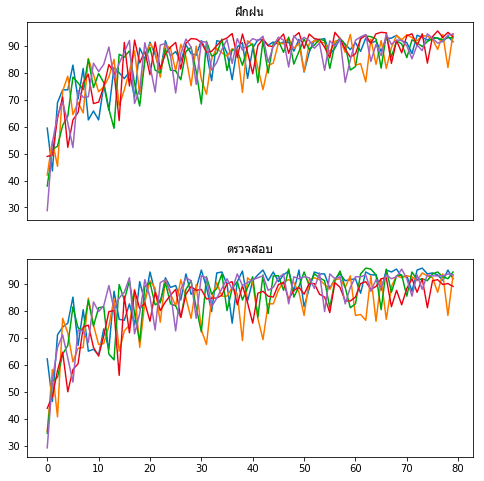
ผลที่ได้จะเห็นว่าแต่ละครั้งมีผลการเรียนรู้ที่ต่างกันออกไป
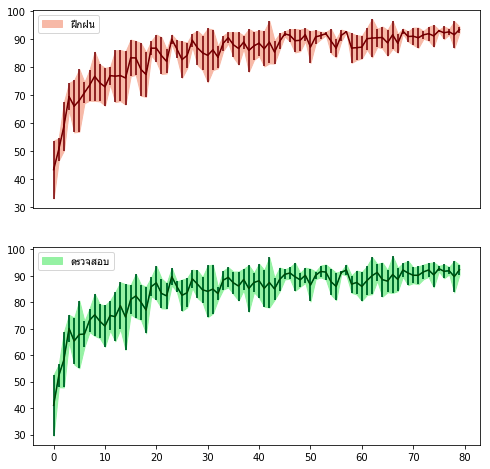
โดยทั่วไปจะสรุปได้ว่า ความแม่นยำรวม = ค่ำเฉลี่ยความแม่นยำ ± ส่วนเบี่ยงเบนมาตรฐานความแม่นยำ
ลองวาดกราฟแสดงค่าเฉลี่ยพร้อมแถบความคลาดเคลื่อน แล้วก็ระบายสีขอบเขตด้วย
นอกจากนี้ ใน sklearn ยังมีคำสั่งที่ช่วยทำแบบนี้ได้อย่างง่ายกว่า คือฟังก์ชัน KFold ซึ่งอยู่ในมอดูลย่อย model_selection
ได้
KFold จะสร้างอิเทอเรเตอร์ขึ้น ซึ่งโดยปกติจะเพื่อใช้ในวังวน for
โดยเริ่มแรกสร้างออบเจ็กต์ของคลาส KFold ขึ้นมา โดยเลขที่ใส่ไปใน n_splits คือจำนวนที่ต้องการแบ่ง
จากนั้นก็ใช้เมธอด split โดยใส่อาเรย์อะไรลงไปก็ได้ ขอแค่มีความยาวเท่ากับจำนวนข้อมูลที่เรามี จากนั้นมันจะทำการสร้างเจเนอเรเตอร์ที่เมื่อวนซ้ำจะได้อาเรย์ออกมาเป็นคู่ ตัวแรกคือดัชนีที่จะใช้เป็นข้อมูลฝึก ตัวหลังคือของข้อมูลทดสอบ
ตัวเลขจะวนเวียนจนดัชนีข้อมูลทดสอบไล่จาก 0 จนครบ
แต่ถ้าต้องการให้เลขสุ่มเรียงก็ใส่คีย์เวิร์ด shuffle=True ไปด้วย เป็น
ได้
เลขจะถูกเรียงแบบสุ่ม แต่สุดท้ายก็จะวนครบเหมือนเดิม
เวลาใช้งานจริงจะใช้แบบนี้
ดูแล้วก็สั้นลงเล็กน้อย ผลที่ได้ก็เหมือนกัน
นอกจากนี้ยังมีคำสั่ง StratifiedKFold ซึ่งเอาไว้ใช้เมื่อต้องการแบ่งกลุ่มให้สัดส่วนคำตอบเท่าเดิม
เพื่อให้เห็นภาพลองดูภาพนี้ เป็นตัวอย่างการแบ่งกลุ่มข้อมูล ๑๐ อัน ซึ่งประกอบไปด้วยแดงและเขียวอย่างละ ๕ อันเท่ากัน โดยลองแบ่งออกเป็น ๕ กลุ่ม

สมมุติว่าข้อมูลที่เรามีถูกจัดเรียงแบบบรรทัดบนสุด หาถใช้ KFold โดยที่ไม่ได้ให้ shuffle ด้วยก็จะถูกจัดกลุ่มทั้งๆแบบนั้น
หากใช้ KFold แล้ว shuffle=True ก็จะเกิดการสุ่ม กลายเป็นแบบแถวที่ ๒ การจัดเรียงอาจดูไม่สมดุล เช่นบางกลุ่มมีแต่สีแดงไม่มีสีเขียว
หากใช้ StratifiedKFold โดยไม่ได้ shuffle ก็จะได้แบบแถวที่ ๓
แต่หากใช้ StratifiedKFold แล้ว shuffle=True ก็จะได้แบบในภาพล่างสุด ทั้งแดงและเขียวถูกแบ่งเท่ากัน
ได้
ในที่นี้เนื่องจาก ๕ ตัวแรกเป็น 0 และ ๕ ตัวหลังเป็น 1 ดังนั้นผลที่ออกมาจะมี 0~4 คู่กับ 5~9 เสมอ
และที่จริงแล้วเวลาใช้อาเรย์ข้อมูลตัวแรกจะเป็นอะไรก็ได้ เพราะไม่ได้ถูกนำมาคิดอยู่ดี ขอแค่มีขนาดเท่ากับอาเรย์ตัวหลังก็พอ
ลองนำมาใช้กับข้อมูลของเราก็เขียนคล้ายๆกับตอน KFold ธรรมดา
skf.split(X,z) นี่จะใส่เป็น skf.split(z,z) หรือ skf.split(np.zeros(len(z)),z) ก็ยังได้
นอกจากนี้ก็ยังมี RepeatedKFold กับ RepeatedStratifiedKFold ซึ่งแค่เพิ่มคำว่า Repeated นำหน้า คือเอาไว้ใช้เมื่อต้องการให้มีการวนซ้ำมากกว่าหนึ่งรอบ
การใช้เหมือนกับ KFold หรือ StratifiedKFold ธรรมดา แต่จะมีคีย์เวิร์ดเพิ่มเข้ามาคือ n_repeats คือจำนวนที่ต้องการทำซ้ำ
และจะไม่มีคีย์เวิร์ด shuffle ให้เลือกว่าจะสุ่มหรือเปล่า คือยังไงก็สุ่มอยู่แล้ว
ลองใช้ดู
ได้
หมายเหตุ: หากใครไปอ่านตำราที่เก่าหน่อยจะพบว่าฟังก์ชัน KFold กับ StratifiedKFold อยู่ในมอดูล cross_validation และมีการใช้งานที่ต่างไป แต่ว่ามอดูลนั้นถูกเลิกใช้แล้ว ฟังก์ชันก็ถูกย้ายและเปลี่ยนใหม่ ดังนั้นให้ใช้ตามนี้ดีกว่า ส่วน RepeatedKFold กับ RepeatedStratifiedKFold เป็นของที่มาทีหลังหากใครใช้เวอร์ชันเก่าอาจไม่มี
อ้างอิง
อย่างไรก็ตาม การแยกข้อมูลทดสอบแค่เพียงครั้งเดียวอาจไม่สามารถยืนยันความแม่นยำของโปรแกรมได้ดีพอก็เป็นได้ เพราะอาจจะแค่บังเอิญว่าข้อมูลที่หยิบมาใช้ฝึกกับทดสอบนั้นกระจายตัวไม่ดีพอ
ดังนั้นจึงมีคนคิดวิธีการที่ว่าให้นำข้อมูลที่มีอยู่สลับกันใช้เป็นข้อมูลฝึกและเป็นข้อมูลทดสอบ ทำซ้ำๆหลายๆครั้ง เปรียบเทียบผลในแต่ละรอบ
การทำแบบนี้เรียกว่า "การตรวจสอบแบบไขว้" (交叉验证, cross validation) ไขว้ในที่นี้หมายถึงมีการสลับสับเปลี่ยนข้อมูลไปมา
วิธีการหนึ่งที่นิยมก็คือวิธีที่เรียกว่า k-fold คือการแบ่งข้อมูลออกเป็นกลุ่ม k กลุ่ม (ในที่นี้ k แทนจำนวนกลุ่ม)
แบ่งแล้วก็ทำการทดลองฝึก k ครั้ง โดยครั้งแรกให้ข้อมูลกลุ่มแรกเป็นข้อมูลตรวจสอบ ที่เหลือเป็นข้อมูลฝึกฝน ครั้งต่อมาให้กลุ่มที่ ๒ เป็นข้อมูลตรวจสอบ แล้วก็ไล่ไปเรื่อยๆจนทุกกลุ่มถูกใช้เป็นข้อมูลทดสอบทั้งหมด
สุดท้ายก็นำประสิทธิภาพที่ได้จากการฝึก k ครั้งมาหาค่าเฉลี่ย แล้วก็หาส่วนเบี่ยงเบนมาตรฐานด้วย ก็จะได้ผลที่บอกได้ว่าผลการฝึกที่เราได้นั้นมีความแม่นยำอยู่ในช่วงประมาณเท่าไหร่
ภาพแสดงตัวอย่างให้เห็น สมมุติว่าข้อมูลมีทั้งหมด ๑๔ ต้องการแบ่งเป็น ๕ กลุ่ม ก็จะทำได้ดังนี้ แต่ละแถวแทนแต่ละรอบ โดยพื้นที่มีแสงคือส่วนที่เลือกไปเป็นข้อมูลตรวจสอบ ส่วนสีเขียวคือข้อมูลฝึกฝน
ตัวอย่างการใช้ เริ่มจากสร้างชุดข้อมูลเป็นกลุ่มก้อน
from sklearn import datasets
X,z = datasets.make_blobs(n_samples=1000,n_features=2,centers=7,cluster_std=0.9,random_state=0)
plt.figure(figsize=[8,8])
plt.axes(aspect=1)
plt.scatter(X[:,0],X[:,1],c=z,edgecolor='k',cmap='rainbow')
plt.show()จากนั้นจะให้โปรแกรมแกรมลองแบ่งกลุ่มข้อมูลด้วยการถดถอยโลจิสติกโดยใช้คลาสที่ลงไว้ใน https://phyblas.hinaboshi.com/20171006
โหลดตัวไฟล์ที่นิยามคลาสไว้ได้ใน https://gist.github.com/phyblas/e65d8f2dc813b0d9289431a1061428fb
ทดสอบการเรียนรู้ด้วยวิธี k-fold ลองเขียนดูได้ดังนี้
n = len(z) # จำนวนข้อมูลทั้งหมด
nf = 5 # จำนวนส่วนที่จะแบ่ง
nn = int(n/nf)+(np.arange(nf)<(n%nf)) # จำนวนที่แบ่งได้ในแต่ละส่วน
tl = ThotthoiLogistic(eta=0.8,n_thamsam=80) # สร้างออบเจ็กต์แบบจำลองเตรียมไว้
sumriang = np.random.permutation(n) # อาเรย์กำหนดลำดับโดยสุ่ม
maen_fuek = []
maen_truat = []
for i in range(nf):
X_fuek = X[sumriang[nn[i]:]]
z_fuek = z[sumriang[nn[i]:]]
X_truat = X[sumriang[:nn[i]]]
z_truat = z[sumriang[:nn[i]]]
sumriang = np.roll(sumriang,nn[i],0) # หมุนเลื่อนอาเรย์
tl.rianru(X_fuek,z_fuek,X_truat,z_truat) # เรียนรู้
maen_fuek.append(tl.maen_fuek) # บันทึกค่าความแม่นยำของแต่ละรอบ
maen_truat.append(tl.maen_truat)
maen_fuek = np.stack(maen_fuek) # เปลี่ยนเป็นอาเรย์เดียว
maen_truat = np.stack(maen_truat)คำสั่ง np.roll เป็นการหมุนเลื่อนการจัดเรียงแถวในอาเรย์ ในที่นี้ใช้เพื่อเปลี่ยนตัวขึ้นต้น
maen_fuek กับ maen_truat คือค่าความแม่นในการทายผลของข้อมูลฝึกกับข้อมูลตรวจสอบซึ่งได้บันทึกไว้ระหว่างเรียนรู้
ลองเอามาวาดกราฟดู
plt.figure(figsize=[8,8])
plt.subplot(211,xticks=[]).set_title(u'ฝึกฝน',family='Tahoma')
plt.plot(maen_fuek.T)
plt.subplot(212).set_title(u'ตรวจสอบ',family='Tahoma')
plt.plot(maen_truat.T)
plt.show()ผลที่ได้จะเห็นว่าแต่ละครั้งมีผลการเรียนรู้ที่ต่างกันออกไป
โดยทั่วไปจะสรุปได้ว่า ความแม่นยำรวม = ค่ำเฉลี่ยความแม่นยำ ± ส่วนเบี่ยงเบนมาตรฐานความแม่นยำ
ลองวาดกราฟแสดงค่าเฉลี่ยพร้อมแถบความคลาดเคลื่อน แล้วก็ระบายสีขอบเขตด้วย
plt.figure(figsize=[8,8])
plt.subplot(211,xticks=[])
mean = maen_fuek.mean(0)
std = maen_fuek.std(0)
plt.errorbar(np.arange(80),mean,yerr=std,color='#660000')
plt.fill_between(np.arange(80),mean-std,mean+std,color='#EEBBAA')
plt.legend([u'ฝึกฝน'],prop={'family':'Tahoma'})
plt.subplot(212)
mean = maen_truat.mean(0)
std = maen_truat.std(0)
plt.errorbar(np.arange(80),mean,yerr=std,color='#004411')
plt.fill_between(np.arange(80),mean-std,mean+std,color='#AAEEAA')
plt.legend([u'ตรวจสอบ'],prop={'family':'Tahoma'})
plt.show()นอกจากนี้ ใน sklearn ยังมีคำสั่งที่ช่วยทำแบบนี้ได้อย่างง่ายกว่า คือฟังก์ชัน KFold ซึ่งอยู่ในมอดูลย่อย model_selection
from sklearn.model_selection import KFold
kf = KFold(n_splits=5)
print(list(kf.split(np.zeros(10))))ได้
[(array([2, 3, 4, 5, 6, 7, 8, 9]), array([0, 1])),
(array([0, 1, 4, 5, 6, 7, 8, 9]), array([2, 3])),
(array([0, 1, 2, 3, 6, 7, 8, 9]), array([4, 5])),
(array([0, 1, 2, 3, 4, 5, 8, 9]), array([6, 7])),
(array([0, 1, 2, 3, 4, 5, 6, 7]), array([8, 9]))]KFold จะสร้างอิเทอเรเตอร์ขึ้น ซึ่งโดยปกติจะเพื่อใช้ในวังวน for
โดยเริ่มแรกสร้างออบเจ็กต์ของคลาส KFold ขึ้นมา โดยเลขที่ใส่ไปใน n_splits คือจำนวนที่ต้องการแบ่ง
จากนั้นก็ใช้เมธอด split โดยใส่อาเรย์อะไรลงไปก็ได้ ขอแค่มีความยาวเท่ากับจำนวนข้อมูลที่เรามี จากนั้นมันจะทำการสร้างเจเนอเรเตอร์ที่เมื่อวนซ้ำจะได้อาเรย์ออกมาเป็นคู่ ตัวแรกคือดัชนีที่จะใช้เป็นข้อมูลฝึก ตัวหลังคือของข้อมูลทดสอบ
ตัวเลขจะวนเวียนจนดัชนีข้อมูลทดสอบไล่จาก 0 จนครบ
แต่ถ้าต้องการให้เลขสุ่มเรียงก็ใส่คีย์เวิร์ด shuffle=True ไปด้วย เป็น
kf = KFold(n_splits=5,shuffle=True)
print(list(kf.split(np.zeros(10))))ได้
[(array([1, 2, 3, 4, 5, 6, 7, 8]), array([0, 9])),
(array([0, 1, 2, 5, 6, 7, 8, 9]), array([3, 4])),
(array([0, 1, 2, 3, 4, 5, 8, 9]), array([6, 7])),
(array([0, 2, 3, 4, 6, 7, 8, 9]), array([1, 5])),
(array([0, 1, 3, 4, 5, 6, 7, 9]), array([2, 8]))]เลขจะถูกเรียงแบบสุ่ม แต่สุดท้ายก็จะวนครบเหมือนเดิม
เวลาใช้งานจริงจะใช้แบบนี้
kf = KFold(n_splits=5,shuffle=True)
for f,t in kf.split(z):
X_fuek = X[f]
z_fuek = z[f]
X_truat = X[t]
z_truat = z[t]
# ...ส่วนที่จะใช้งานดูแล้วก็สั้นลงเล็กน้อย ผลที่ได้ก็เหมือนกัน
นอกจากนี้ยังมีคำสั่ง StratifiedKFold ซึ่งเอาไว้ใช้เมื่อต้องการแบ่งกลุ่มให้สัดส่วนคำตอบเท่าเดิม
เพื่อให้เห็นภาพลองดูภาพนี้ เป็นตัวอย่างการแบ่งกลุ่มข้อมูล ๑๐ อัน ซึ่งประกอบไปด้วยแดงและเขียวอย่างละ ๕ อันเท่ากัน โดยลองแบ่งออกเป็น ๕ กลุ่ม
สมมุติว่าข้อมูลที่เรามีถูกจัดเรียงแบบบรรทัดบนสุด หาถใช้ KFold โดยที่ไม่ได้ให้ shuffle ด้วยก็จะถูกจัดกลุ่มทั้งๆแบบนั้น
หากใช้ KFold แล้ว shuffle=True ก็จะเกิดการสุ่ม กลายเป็นแบบแถวที่ ๒ การจัดเรียงอาจดูไม่สมดุล เช่นบางกลุ่มมีแต่สีแดงไม่มีสีเขียว
หากใช้ StratifiedKFold โดยไม่ได้ shuffle ก็จะได้แบบแถวที่ ๓
แต่หากใช้ StratifiedKFold แล้ว shuffle=True ก็จะได้แบบในภาพล่างสุด ทั้งแดงและเขียวถูกแบ่งเท่ากัน
from sklearn.model_selection import StratifiedKFold
skf = StratifiedKFold(n_splits=5,shuffle=True)
print(list(skf.split(np.zeros(10),np.array([0]*5+[1]*5))))ได้
[(array([0, 1, 2, 3, 5, 7, 8, 9]), array([4, 6])),
(array([0, 2, 3, 4, 5, 6, 7, 8]), array([1, 9])),
(array([1, 2, 3, 4, 6, 7, 8, 9]), array([0, 5])),
(array([0, 1, 3, 4, 5, 6, 8, 9]), array([2, 7])),
(array([0, 1, 2, 4, 5, 6, 7, 9]), array([3, 8]))]ในที่นี้เนื่องจาก ๕ ตัวแรกเป็น 0 และ ๕ ตัวหลังเป็น 1 ดังนั้นผลที่ออกมาจะมี 0~4 คู่กับ 5~9 เสมอ
และที่จริงแล้วเวลาใช้อาเรย์ข้อมูลตัวแรกจะเป็นอะไรก็ได้ เพราะไม่ได้ถูกนำมาคิดอยู่ดี ขอแค่มีขนาดเท่ากับอาเรย์ตัวหลังก็พอ
ลองนำมาใช้กับข้อมูลของเราก็เขียนคล้ายๆกับตอน KFold ธรรมดา
skf = StratifiedKFold(n_splits=5,shuffle=True)
for f,t in skf.split(X,z):
X_fuek = X[f]
z_fuek = z[f]
X_truat = X[t]
z_truat = z[t]
# ...ส่วนที่จะใช้งานskf.split(X,z) นี่จะใส่เป็น skf.split(z,z) หรือ skf.split(np.zeros(len(z)),z) ก็ยังได้
นอกจากนี้ก็ยังมี RepeatedKFold กับ RepeatedStratifiedKFold ซึ่งแค่เพิ่มคำว่า Repeated นำหน้า คือเอาไว้ใช้เมื่อต้องการให้มีการวนซ้ำมากกว่าหนึ่งรอบ
การใช้เหมือนกับ KFold หรือ StratifiedKFold ธรรมดา แต่จะมีคีย์เวิร์ดเพิ่มเข้ามาคือ n_repeats คือจำนวนที่ต้องการทำซ้ำ
และจะไม่มีคีย์เวิร์ด shuffle ให้เลือกว่าจะสุ่มหรือเปล่า คือยังไงก็สุ่มอยู่แล้ว
ลองใช้ดู
from sklearn.model_selection import RepeatedStratifiedKFold
rskf = RepeatedStratifiedKFold(n_splits=4,n_repeats=2)
print(list(rskf.split(np.zeros(8),np.array([0]*4+[1]*4))))ได้
[(array([0, 2, 3, 4, 5, 7]), array([1, 6])),
(array([1, 2, 3, 5, 6, 7]), array([0, 4])),
(array([0, 1, 2, 4, 6, 7]), array([3, 5])),
(array([0, 1, 3, 4, 5, 6]), array([2, 7])),
(array([0, 1, 2, 4, 5, 6]), array([3, 7])),
(array([0, 2, 3, 4, 5, 7]), array([1, 6])),
(array([1, 2, 3, 4, 6, 7]), array([0, 5])),
(array([0, 1, 3, 5, 6, 7]), array([2, 4]))]หมายเหตุ: หากใครไปอ่านตำราที่เก่าหน่อยจะพบว่าฟังก์ชัน KFold กับ StratifiedKFold อยู่ในมอดูล cross_validation และมีการใช้งานที่ต่างไป แต่ว่ามอดูลนั้นถูกเลิกใช้แล้ว ฟังก์ชันก็ถูกย้ายและเปลี่ยนใหม่ ดังนั้นให้ใช้ตามนี้ดีกว่า ส่วน RepeatedKFold กับ RepeatedStratifiedKFold เป็นของที่มาทีหลังหากใครใช้เวอร์ชันเก่าอาจไม่มี
อ้างอิง
https://www.amazon.co.jp/Python機械学習プログラミング-達人データサイエンティストによる理論と実践-impress-top-gearシリーズ-ebook/dp/B01HGIPIAK
http://aidiary.hatenablog.com/entry/20150826/1440596779
https://qiita.com/SE96UoC5AfUt7uY/items/d4b796f7658b7e5be3b6
https://naokiwatanabe.blogspot.tw/2015/11/pythonscikit-learn-svm-k-fold.html
http://segafreder.hatenablog.com/entry/2016/10/18/163925
http://scikit-learn.org/stable/modules/generated/sklearn.model_selection.KFold.html
https://qiita.com/kenmatsu4/items/0a862a42ceb178ba7155
https://morvanzhou.github.io/tutorials/machine-learning/sklearn/3-2-cross-validation1
http://aidiary.hatenablog.com/entry/20150826/1440596779
https://qiita.com/SE96UoC5AfUt7uY/items/d4b796f7658b7e5be3b6
https://naokiwatanabe.blogspot.tw/2015/11/pythonscikit-learn-svm-k-fold.html
http://segafreder.hatenablog.com/entry/2016/10/18/163925
http://scikit-learn.org/stable/modules/generated/sklearn.model_selection.KFold.html
https://qiita.com/kenmatsu4/items/0a862a42ceb178ba7155
https://morvanzhou.github.io/tutorials/machine-learning/sklearn/3-2-cross-validation1
-----------------------------------------
囧囧囧囧囧囧囧囧囧囧囧囧囧囧囧囧囧囧囧囧囧囧囧囧囧
หมวดหมู่
-- คอมพิวเตอร์ >> ปัญญาประดิษฐ์-- คอมพิวเตอร์ >> เขียนโปรแกรม >> python >> numpy
-- คอมพิวเตอร์ >> เขียนโปรแกรม >> python >> matplotlib
-- คอมพิวเตอร์ >> เขียนโปรแกรม >> python >> sklearn