[python] แบบจำลองการวิเคราะห์การถดถอยโลจิสติกที่พร้อมใช้งาน
เขียนเมื่อ 2017/10/06 23:21
แก้ไขล่าสุด 2022/07/21 15:16
บทความที่เขียนมาจนถึงตอนนี้ได้สร้างแบบจำลองการถดถอยโลจิสติกตั้งแต่พื้นฐานและปรับปรุงแต่งเสริมเพิ่มเติมรวมแล้วหลายตอน
เริ่มตั้งแต่หน้าแรกที่แนะนำการถดถอยโลจิสติกไป https://phyblas.hinaboshi.com/20161103
จากนั้นก็พูดถึงการทำข้อมูลให้เป็นมาตรฐาน https://phyblas.hinaboshi.com/20161124
ปรับแบบจำลองเป็นแบบมัลติโนเมียลเพื่อแก้ปัญหาการจำแนกข้อมูลหลายกลุ่ม (การถดถอยซอฟต์แม็กซ์) https://phyblas.hinaboshi.com/20161205
แล้วก็การเลือกใช้เอนโทรปีไขว้เป็นค่าเสียหาย https://phyblas.hinaboshi.com/20161207
การทำมินิแบตช์ https://phyblas.hinaboshi.com/20161207
ต่อมาก็การทำเรกูลาไรซ์ https://phyblas.hinaboshi.com/20170928
สุดท้ายก็พูดถึงรูปแบบต่างๆในการปรับปรุงวิธีการเคลื่อนลงตามความชันในการเรียนรู้ https://phyblas.hinaboshi.com/20171002
จะเห็นว่าแค่แบบจำลองการวิเคราะห์การถดถอยโลจิสติกก็มีรายละเอียดส่วนประกอบต่างๆมากมาย
ดังนั้นคราวนี้จะสรุปสิ่งทำมาทั้งหมดจนถึงตอนนี้ โดยสร้างคลาสอันใหม่ที่ใส่ทุกอย่างลงไป
ในที่นี้จะทำเป็นโลจิสติกแบบมัลติโนเมียล (ซอฟต์แม็กซ์) เท่านั้น ส่วนโลจิสติกแบบเบื้องต้นที่ใช้จำแนกข้อมูลแค่ ๒ กลุ่มนั้นอาจไม่ค่อยจำเป็น เนื่องจากใช้แบบมัลติโนเมียลจะจำแนกกี่กลุ่มก็ได้อยู่แล้ว
ทั้งหมดนี้สร้างขึ้นโดยใช้แค่ numpy ล้วนๆ ไม่ได้ใช้ sklearn เลย แม้ว่า sklearn จะมีฟังก์ชันหลายอย่างที่ช่วยให้สามารถเขียนได้ง่ายขึ้นก็ตาม แต่ต่อให้ไม่ใช้ก็สามารถเขียนเองได้ ผลแทบไม่ต่างกันอยู่แล้ว
การสร้างอะไรขึ้นเองหมดจากศูนย์โดยไม่ใช้มอดูลพิเศษอะไรช่วย (ไม่นับ numpy ซึ่งเป็นพื้นฐานอยู่แล้ว) แบบนี้เป็นการฝึกที่ดีที่ช่วยให้เราเข้าใจกระบวนการต่างๆอย่างชัดเจน
จริงอยู่ว่า sklearn เองก็มีคลาสแบบจำลองการถดถอยโลจิสติกที่ดูสมบูรณ์แบบอยู่แล้ว ซึ่งอาจใช้งานได้ดีกว่าที่เราสร้างขึ้นเอง บางทีต่อไปเวลาใช้งานจริงเราอาจจะไปใช้ของ sklearn อยู่ดีเพื่อความง่าย
แต่การที่เราได้เคยสร้างขึ้นมาด้วยตัวเองแล้วนั้นก็ทำให้เราเข้าใจส่วนประกอบภายในอย่างดี การเปลี่ยนค่าอะไรจะมีผลอย่างไร เวลาเจอบั๊กมันควรเกิดจากอะไร ย่อมวิเคราะห์ได้ง่าย
ต่อไปจะเป็นโค้ด เนื่องจากยาว โค้ดครั้งนี้ลองลงใน gist ไม่ได้ใส่ไว้ตรงนี้โดยตรง
ต่อไปจะอธิบายเกี่ยวกับพารามิเตอร์ต่างๆ
eta และ opt
เป็นตัวกำหนดอัตราการเรียนรู้และชนิดของตัวออปทิไมเซอร์
กรณีที่ใส่แต่ eta จะเป็นการใช้ SGD ธรรมดา และอัตราการเรียนรู้ก็จะเป็นตรามค่า eta ที่ใส่ไป
แต่หากต้องการใช้ตัวอื่น มีวิธีการใช้ ๒ วิธีคือใส่ opt เป็นสายอักขระของชื่อวิธีการนั้น หรือใส่เป็นออบเจ็กต์ไปเลย
หากใส่ชื่อของวิธีการนั้น ที่เลือกได้ก็มี Mmtsgd, Nag, Adagrad, Adadelta, Adam
เพียงว่าแบบนั้นไฮเพอร์พารามิเตอร์ตัวอื่นนอกจา eta จะไม่สามารถปรับได้เลย และจะใช้เป็นค่าตั้งต้นตลอด เช่นค่าโมเมนตัม=0.9 หรือค่า beta1=0.9,beta2=0.999 ของ Adam
กรณีที่ต้องการออปทิไมเซอร์ที่มีไฮเพอร์พารามิเตอร์ตามที่ต้องการให้ใส่ค่า opt เป็นออบเจ็กต์ของตัวนั้นเลย เช่น Nag(eta=0.1,mmt=0.8)
n_thamsam
คือจำนวนสูงสุดที่จะให้ทำซ้ำเพื่อเรียนรู้
แต่กรณีที่มีการใส่ค่า ro เอาไว้จะเป็นการกำหนดเงื่อนไขการหยุดก่อน และจำนวนครั้งที่ทำซ้ำก็อาจไม่ถึงจำนวนที่กำหนดไว้นี้
n_batch
คือขนาดของมินิแบตช์ แต่ถ้าใส่เป็น 0 ก็คือไม่ทำมินิแบตช์ แต่ใช้ข้อมูลทั้งหมดฝึกรวดเดียวเลย
loss
คือชนิดของค่าเสียหาย โดยทั่วไปแล้วจะใช้เป็น entropy ตลอดอยู่แล้ว แต่หากต้องการจะใช้เป็นค่าเฉลี่ยความคลาดเคลื่อนกำลังสอง (MSE) ก็ได้ ก็ใส่เป็น mse
ถ้าไม่ใส่จะใช้เป็น entropy
reg และ l
เป็นตัวกำหนดชนิดและขนาดของเรกูลาไรซ์
reg คือชนิดของเรกูลาไรซ์ เลือกได้ ๒ แบบคือ l1 และ l2 ถ้าไม่ใส่จะเป็น l2
l คือขนาดของเรกูลาไรซ์ ถ้าไม่ใส่จะเป็น 0 คือไม่มีการเรกูลาไรซ์
std
เป็นตัวกำหนดว่าจะทำให้ข้อมูลเป็นมาตรฐานก่อนการเรียนรู้หรือไม่ ถ้าทำใส่ 1 ถ้าไม่ทำใส่ 0
ถ้าไม่ใส่จะเป็น 0 คือไม่ทำ
dukha และ ro
เป็นตัวกำหนดเงื่อนไขการหยุดเร็ว
dukha เป็นตัวบอกว่าจะดูค่าอะไรเป็นเงื่อนไขการหยุด
maen_truat คือความแม่นยำในการทำนายชุดข้อมูลตรวจสอบ
maen_fuek คือความแม่นยำในการทำนายชุดข้อมูลฝึก
khasiahai คือค่าเสียหาย
ถ้าไม่ใส่จะใช้เป็น maen_truat
ส่วน ro เป็นตัวกำหนดว่าจะรอให้ค่านั้นไม่เพิ่มกี่ครั้งจึงจะให้สิ้นสุดการเรียนรู้ก่อนจำนวนครั้งสูงสุดที่กำหนดไว้
bok
เป็นตัวกำหนดว่าจะให้มีการพิมพ์บอกแจ้งความคืบหน้าในการเรียนรู้ครั้งนึงต่อกี่ขั้นการฝึก
หากไม่ใส่หรือใส่ 0 ก็คือไม่มีการบอกอะไร
ค่าพารามิเตอร์ทั้งหมดนี้จะให้กำหนดให้เรียบร้อยตั้งแต่ตอนเริ่มต้นสร้างออบเจ็กต์ของคลาส พอตอนเรียนรู้ก็ป้อนแค่ข้อมูลเรียนรู้กับข้อมูลตรวจสอบเข้ามาเท่านั้น
เพียงแต่ว่าก็สามารถป้อนค่าเหล่านี้ตอนเรียนรู้ได้เช่นกัน จะเป็นการเปลี่ยนมาใช้ค่าที่ป้อนเข้ามาใหม่นี้แทนในการเรียนรู้ครั้งนั้น
ในการเรียนรู้มีคีย์เวิร์ดสำคัญอีกอันหนึ่งคือ rianto เป็นตัวกำหนดว่าจะเรียนต่อจากครั้งที่แล้วหรือไม่ ในกรณีที่มีการเรียนรู้ไปแล้วทีนึง ถ้าเรียนต่อใส่ 1 ถ้าไม่ ใส่ 0
กรณีที่เรียนต่อนั้นหมายความว่าค่าน้ำหนักเริ่มต้นจะใช้ต่อจากที่เรียนรู้ไว้ครั้งที่แล้ว แต่ถ้าไม่ก็จะเริ่มจาก 0 ใหม่หมด
จากนั้นลองมาดูตัวอย่างการใช้ โดยลองสร้างข้อมูลเป็นกลุ่มก้อนออกมา ๖ กลุ่ม (รายละเอียดฟังก์ชัน make_blobs https://phyblas.hinaboshi.com/20161127)
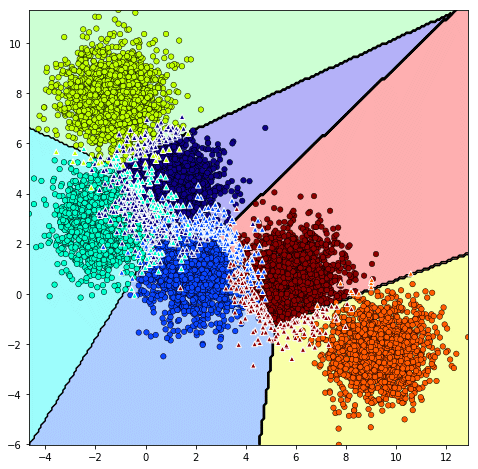
ในที่นี้ถ้าใช้เมธอด thamnai เฉยๆก็จะเป็นแค่การทายผลลัพธ์ว่าเป็นตัวแปรไหนเท่านั้น โดยจะเลือกกลุ่มที่มีความน่าจะเป็นสูงสุดมาเป็นคำตอบ
แต่ในนี้ได้เตรียมเมธอดเพิ่มอีกอย่างไว้คือ thamnai_laiat คือจะแสดงความน่าจะเป็นของแต่ละกลุ่ม ซึ่งเป็นผลมาจากการคำนวณด้วยฟังก์ชันซอฟต์แม็กซ์
ที่จริงเมธอด thamnai_laiat นี้ก็คืออันเดียวกับเมธอด ha_softmax เพียงแต่ตั้งชื่อใหม่ให้เพิ่มเติม หากจะใช้เป็น ha_softmax แทนก็ได้เช่นกัน
ลองใช้ดู แสดงความน่าจะเป็นของกลุ่มทั้ง ๖ ในที่นี้จุดสีน้ำเงินคือกลุ่มที่กำลังพิจารณาอยู่ ส่วนสีชมพูคือกลุ่มอื่น
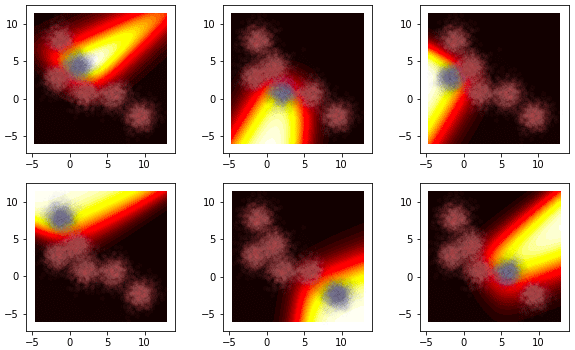
จะเห็นว่าเมื่อลองเทียบกับภาพที่แสดงผลการจำแนกกลุ่มด้านบนแล้วจะสอดคล้องกันดี กลุ่มที่เห็นเป็นสีสว่างก็คือที่ถูกเลือกเป็นคำตอบ
ต่อมาลองใช้กับข้อมูล MNIST ดูด้วย ครั้งนี้ลองใส่พารามิเตอร์ไปแค่นิดเดียว ส่วนที่ไม่ใส่ก็จะเป็นไปตามค่าตั้งต้น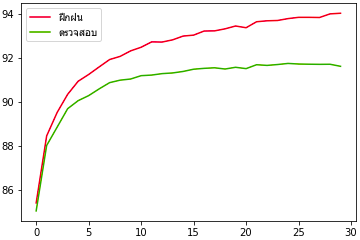
นอกจากนี้ก็ยังจะสามารถใช้ทำอะไรได้อีกมาก สิ่งที่ทำในตัวอย่างที่ผ่านๆมาในบทความก่อนๆสามารถใช้อันนี้แทนได้ทั้งหมด
เริ่มตั้งแต่หน้าแรกที่แนะนำการถดถอยโลจิสติกไป https://phyblas.hinaboshi.com/20161103
จากนั้นก็พูดถึงการทำข้อมูลให้เป็นมาตรฐาน https://phyblas.hinaboshi.com/20161124
ปรับแบบจำลองเป็นแบบมัลติโนเมียลเพื่อแก้ปัญหาการจำแนกข้อมูลหลายกลุ่ม (การถดถอยซอฟต์แม็กซ์) https://phyblas.hinaboshi.com/20161205
แล้วก็การเลือกใช้เอนโทรปีไขว้เป็นค่าเสียหาย https://phyblas.hinaboshi.com/20161207
การทำมินิแบตช์ https://phyblas.hinaboshi.com/20161207
ต่อมาก็การทำเรกูลาไรซ์ https://phyblas.hinaboshi.com/20170928
สุดท้ายก็พูดถึงรูปแบบต่างๆในการปรับปรุงวิธีการเคลื่อนลงตามความชันในการเรียนรู้ https://phyblas.hinaboshi.com/20171002
จะเห็นว่าแค่แบบจำลองการวิเคราะห์การถดถอยโลจิสติกก็มีรายละเอียดส่วนประกอบต่างๆมากมาย
ดังนั้นคราวนี้จะสรุปสิ่งทำมาทั้งหมดจนถึงตอนนี้ โดยสร้างคลาสอันใหม่ที่ใส่ทุกอย่างลงไป
ในที่นี้จะทำเป็นโลจิสติกแบบมัลติโนเมียล (ซอฟต์แม็กซ์) เท่านั้น ส่วนโลจิสติกแบบเบื้องต้นที่ใช้จำแนกข้อมูลแค่ ๒ กลุ่มนั้นอาจไม่ค่อยจำเป็น เนื่องจากใช้แบบมัลติโนเมียลจะจำแนกกี่กลุ่มก็ได้อยู่แล้ว
ทั้งหมดนี้สร้างขึ้นโดยใช้แค่ numpy ล้วนๆ ไม่ได้ใช้ sklearn เลย แม้ว่า sklearn จะมีฟังก์ชันหลายอย่างที่ช่วยให้สามารถเขียนได้ง่ายขึ้นก็ตาม แต่ต่อให้ไม่ใช้ก็สามารถเขียนเองได้ ผลแทบไม่ต่างกันอยู่แล้ว
การสร้างอะไรขึ้นเองหมดจากศูนย์โดยไม่ใช้มอดูลพิเศษอะไรช่วย (ไม่นับ numpy ซึ่งเป็นพื้นฐานอยู่แล้ว) แบบนี้เป็นการฝึกที่ดีที่ช่วยให้เราเข้าใจกระบวนการต่างๆอย่างชัดเจน
จริงอยู่ว่า sklearn เองก็มีคลาสแบบจำลองการถดถอยโลจิสติกที่ดูสมบูรณ์แบบอยู่แล้ว ซึ่งอาจใช้งานได้ดีกว่าที่เราสร้างขึ้นเอง บางทีต่อไปเวลาใช้งานจริงเราอาจจะไปใช้ของ sklearn อยู่ดีเพื่อความง่าย
แต่การที่เราได้เคยสร้างขึ้นมาด้วยตัวเองแล้วนั้นก็ทำให้เราเข้าใจส่วนประกอบภายในอย่างดี การเปลี่ยนค่าอะไรจะมีผลอย่างไร เวลาเจอบั๊กมันควรเกิดจากอะไร ย่อมวิเคราะห์ได้ง่าย
ต่อไปจะเป็นโค้ด เนื่องจากยาว โค้ดครั้งนี้ลองลงใน gist ไม่ได้ใส่ไว้ตรงนี้โดยตรง
ต่อไปจะอธิบายเกี่ยวกับพารามิเตอร์ต่างๆ
eta และ opt
เป็นตัวกำหนดอัตราการเรียนรู้และชนิดของตัวออปทิไมเซอร์
กรณีที่ใส่แต่ eta จะเป็นการใช้ SGD ธรรมดา และอัตราการเรียนรู้ก็จะเป็นตรามค่า eta ที่ใส่ไป
แต่หากต้องการใช้ตัวอื่น มีวิธีการใช้ ๒ วิธีคือใส่ opt เป็นสายอักขระของชื่อวิธีการนั้น หรือใส่เป็นออบเจ็กต์ไปเลย
หากใส่ชื่อของวิธีการนั้น ที่เลือกได้ก็มี Mmtsgd, Nag, Adagrad, Adadelta, Adam
เพียงว่าแบบนั้นไฮเพอร์พารามิเตอร์ตัวอื่นนอกจา eta จะไม่สามารถปรับได้เลย และจะใช้เป็นค่าตั้งต้นตลอด เช่นค่าโมเมนตัม=0.9 หรือค่า beta1=0.9,beta2=0.999 ของ Adam
กรณีที่ต้องการออปทิไมเซอร์ที่มีไฮเพอร์พารามิเตอร์ตามที่ต้องการให้ใส่ค่า opt เป็นออบเจ็กต์ของตัวนั้นเลย เช่น Nag(eta=0.1,mmt=0.8)
n_thamsam
คือจำนวนสูงสุดที่จะให้ทำซ้ำเพื่อเรียนรู้
แต่กรณีที่มีการใส่ค่า ro เอาไว้จะเป็นการกำหนดเงื่อนไขการหยุดก่อน และจำนวนครั้งที่ทำซ้ำก็อาจไม่ถึงจำนวนที่กำหนดไว้นี้
n_batch
คือขนาดของมินิแบตช์ แต่ถ้าใส่เป็น 0 ก็คือไม่ทำมินิแบตช์ แต่ใช้ข้อมูลทั้งหมดฝึกรวดเดียวเลย
loss
คือชนิดของค่าเสียหาย โดยทั่วไปแล้วจะใช้เป็น entropy ตลอดอยู่แล้ว แต่หากต้องการจะใช้เป็นค่าเฉลี่ยความคลาดเคลื่อนกำลังสอง (MSE) ก็ได้ ก็ใส่เป็น mse
ถ้าไม่ใส่จะใช้เป็น entropy
reg และ l
เป็นตัวกำหนดชนิดและขนาดของเรกูลาไรซ์
reg คือชนิดของเรกูลาไรซ์ เลือกได้ ๒ แบบคือ l1 และ l2 ถ้าไม่ใส่จะเป็น l2
l คือขนาดของเรกูลาไรซ์ ถ้าไม่ใส่จะเป็น 0 คือไม่มีการเรกูลาไรซ์
std
เป็นตัวกำหนดว่าจะทำให้ข้อมูลเป็นมาตรฐานก่อนการเรียนรู้หรือไม่ ถ้าทำใส่ 1 ถ้าไม่ทำใส่ 0
ถ้าไม่ใส่จะเป็น 0 คือไม่ทำ
dukha และ ro
เป็นตัวกำหนดเงื่อนไขการหยุดเร็ว
dukha เป็นตัวบอกว่าจะดูค่าอะไรเป็นเงื่อนไขการหยุด
maen_truat คือความแม่นยำในการทำนายชุดข้อมูลตรวจสอบ
maen_fuek คือความแม่นยำในการทำนายชุดข้อมูลฝึก
khasiahai คือค่าเสียหาย
ถ้าไม่ใส่จะใช้เป็น maen_truat
ส่วน ro เป็นตัวกำหนดว่าจะรอให้ค่านั้นไม่เพิ่มกี่ครั้งจึงจะให้สิ้นสุดการเรียนรู้ก่อนจำนวนครั้งสูงสุดที่กำหนดไว้
bok
เป็นตัวกำหนดว่าจะให้มีการพิมพ์บอกแจ้งความคืบหน้าในการเรียนรู้ครั้งนึงต่อกี่ขั้นการฝึก
หากไม่ใส่หรือใส่ 0 ก็คือไม่มีการบอกอะไร
ค่าพารามิเตอร์ทั้งหมดนี้จะให้กำหนดให้เรียบร้อยตั้งแต่ตอนเริ่มต้นสร้างออบเจ็กต์ของคลาส พอตอนเรียนรู้ก็ป้อนแค่ข้อมูลเรียนรู้กับข้อมูลตรวจสอบเข้ามาเท่านั้น
เพียงแต่ว่าก็สามารถป้อนค่าเหล่านี้ตอนเรียนรู้ได้เช่นกัน จะเป็นการเปลี่ยนมาใช้ค่าที่ป้อนเข้ามาใหม่นี้แทนในการเรียนรู้ครั้งนั้น
ในการเรียนรู้มีคีย์เวิร์ดสำคัญอีกอันหนึ่งคือ rianto เป็นตัวกำหนดว่าจะเรียนต่อจากครั้งที่แล้วหรือไม่ ในกรณีที่มีการเรียนรู้ไปแล้วทีนึง ถ้าเรียนต่อใส่ 1 ถ้าไม่ ใส่ 0
กรณีที่เรียนต่อนั้นหมายความว่าค่าน้ำหนักเริ่มต้นจะใช้ต่อจากที่เรียนรู้ไว้ครั้งที่แล้ว แต่ถ้าไม่ก็จะเริ่มจาก 0 ใหม่หมด
จากนั้นลองมาดูตัวอย่างการใช้ โดยลองสร้างข้อมูลเป็นกลุ่มก้อนออกมา ๖ กลุ่ม (รายละเอียดฟังก์ชัน make_blobs https://phyblas.hinaboshi.com/20161127)
from sklearn import datasets
from sklearn.model_selection import train_test_split
import matplotlib.pyplot as plt
np.random.seed(0)
X,z = datasets.make_blobs(n_samples=10000,n_features=2,centers=6)
X_fuek,X_truat,z_fuek,z_truat = train_test_split(X,z,test_size=0.2)
tl = ThotthoiLogistic(n_thamsam=200,
n_batch=100,
eta=0.001,
opt='Nag',
loss='entropy',
reg='l2',
l=10.,
std=1,
ro=10,
dukha='maen_truat',
bok=10)
tl.rianru(X_fuek,z_fuek,X_truat,z_truat)
plt.figure(figsize=[8,8])
plt.axes(xlim=[X[:,0].min(),X[:,0].max()],ylim=[X[:,1].min(),X[:,1].max()],aspect=1)
nmesh = 200
mx,my = np.meshgrid(np.linspace(X[:,0].min(),X[:,0].max(),nmesh),np.linspace(X[:,1].min(),X[:,1].max(),nmesh))
mX = np.stack([mx.ravel(),my.ravel()],1)
mz = tl.thamnai(mX)
si = plt.get_cmap('jet')(np.linspace(0,1,tl.kiklum))
plt.contourf(mx,my,mz.reshape(nmesh,nmesh),alpha=0.3,cmap='jet',zorder=0)
plt.contour(mx,my,mz.reshape(nmesh,nmesh),colors='k',lw=2,zorder=0)
ox = tl.thamnai(X)==z
c = np.array([si[i] for i in z])
plt.scatter(X[ox,0],X[ox,1],c=c[ox],s=30,edgecolor='k',lw=0.5)
plt.scatter(X[~ox,0],X[~ox,1],c=c[~ox],s=30,edgecolor='w',marker='^')
plt.show()ในที่นี้ถ้าใช้เมธอด thamnai เฉยๆก็จะเป็นแค่การทายผลลัพธ์ว่าเป็นตัวแปรไหนเท่านั้น โดยจะเลือกกลุ่มที่มีความน่าจะเป็นสูงสุดมาเป็นคำตอบ
แต่ในนี้ได้เตรียมเมธอดเพิ่มอีกอย่างไว้คือ thamnai_laiat คือจะแสดงความน่าจะเป็นของแต่ละกลุ่ม ซึ่งเป็นผลมาจากการคำนวณด้วยฟังก์ชันซอฟต์แม็กซ์
ที่จริงเมธอด thamnai_laiat นี้ก็คืออันเดียวกับเมธอด ha_softmax เพียงแต่ตั้งชื่อใหม่ให้เพิ่มเติม หากจะใช้เป็น ha_softmax แทนก็ได้เช่นกัน
ลองใช้ดู แสดงความน่าจะเป็นของกลุ่มทั้ง ๖ ในที่นี้จุดสีน้ำเงินคือกลุ่มที่กำลังพิจารณาอยู่ ส่วนสีชมพูคือกลุ่มอื่น
mz = tl.thamnai_laiat(mX)
plt.figure(figsize=[10,6])
for i in range(6):
plt.subplot(231+i,aspect=1)
plt.contourf(mx,my,mz[:,i].reshape(nmesh,nmesh),40,cmap='hot',zorder=0)
plt.scatter(X[z==i,0],X[z==i,1],c='#AAAAEE',alpha=0.02,s=30,edgecolor='k',lw=0.5)
plt.scatter(X[z!=i,0],X[z!=i,1],c='#FFAAAA',alpha=0.02,s=30,edgecolor='k',lw=0.5)
plt.show()จะเห็นว่าเมื่อลองเทียบกับภาพที่แสดงผลการจำแนกกลุ่มด้านบนแล้วจะสอดคล้องกันดี กลุ่มที่เห็นเป็นสีสว่างก็คือที่ถูกเลือกเป็นคำตอบ
ต่อมาลองใช้กับข้อมูล MNIST ดูด้วย ครั้งนี้ลองใส่พารามิเตอร์ไปแค่นิดเดียว ส่วนที่ไม่ใส่ก็จะเป็นไปตามค่าตั้งต้น
mnist = datasets.fetch_mldata('MNIST original')
mnist.data = mnist.data/255.
X_fuek,X_truat,z_fuek,z_truat = train_test_split(mnist.data,mnist.target,test_size=0.8)
tl = ThotthoiLogistic(opt=Adam())
tl.rianru(X_fuek,z_fuek,X_truat,z_truat,ro=5)
plt.figure()
plt.plot(tl.maen_fuek,'#dd0022')
plt.plot(tl.maen_truat,'#55aa00')
plt.legend([u'ฝึกฝน',u'ตรวจสอบ'],prop={'family':'Tahoma'})
plt.show()นอกจากนี้ก็ยังจะสามารถใช้ทำอะไรได้อีกมาก สิ่งที่ทำในตัวอย่างที่ผ่านๆมาในบทความก่อนๆสามารถใช้อันนี้แทนได้ทั้งหมด
-----------------------------------------
囧囧囧囧囧囧囧囧囧囧囧囧囧囧囧囧囧囧囧囧囧囧囧囧囧
หมวดหมู่
-- คอมพิวเตอร์ >> ปัญญาประดิษฐ์-- คอมพิวเตอร์ >> เขียนโปรแกรม >> python >> numpy
-- คอมพิวเตอร์ >> เขียนโปรแกรม >> python >> matplotlib