[python] สร้างข้อมูลกลุ่มรูปจันทร์เสี้ยวเพื่อใช้ทดสอบการเรียนรู้ของเครื่อง
เขียนเมื่อ 2017/12/02 10:56
แก้ไขล่าสุด 2022/07/19 08:34
ก่อนหน้านี้เคยได้แนะนำการสร้างข้อมูลเป็นกลุ่มๆก้อนๆเพื่อใช้ทดสอบแบบจำลองการเรียนรู้ของเครื่องไป https://phyblas.hinaboshi.com/20161127
แต่นอกจากนั้นแล้วใน sklearn มีของเล่นคล้ายๆกันแบบนี้ที่สามารถสร้างขึ้นได้อีกมากมาย
ในที่นี้จะลองนำเอาอีกตัวคือ make_moons มาลองใช้เล่นดู
make_moons เป็นฟังก์ชันสำหรับสร้างข้อมูลรูปพระจันทร์เสี้ยว
ตัวอย่างการใช้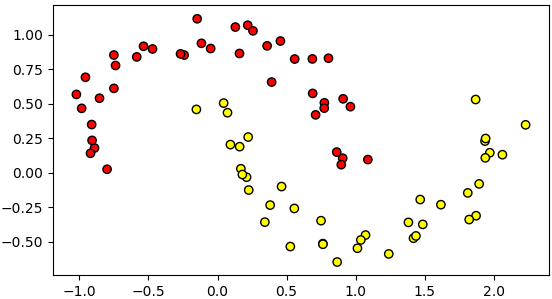
จะเห็นว่าได้ช้อมูลที่มีการกระจายเป็นแบบคล้ายพระจันทร์เสี้ยว ๒ อันไขว้กัน
ข้อมูลในลักษณะนี้เหมาะกับการทดสอบแบบจำลองการแบ่งกลุ่มที่ไม่เป็นเชิงเส้น เช่นวิธีการเพื่อนบ้านใกล้สุด k ตัว หรือป่าสุ่ม
คีย์เวิร์ดที่ใส่เพื่อปรับแต่งได้มีแค่ ๔ ตัว ดังนี้
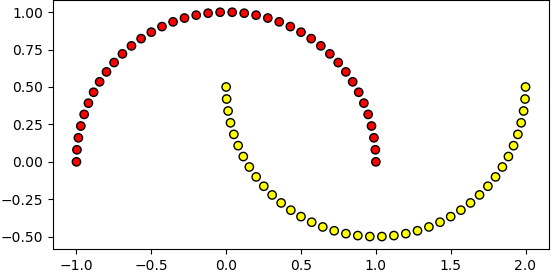
noise เป็นตัวกำหนดการกระจายของจุด เช่นถ้าไม่ใส่ noise เลย หรือใส่ noise=0 ก็จะเป็นแบบนี้
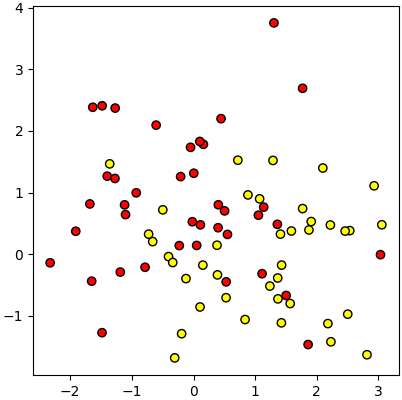
แต่ถ้าใส่ noise=1 ข้อมูลก็จะเริ่มกระจายมั่ว แยกไม่ค่อยออกแล้ว
ส่วน random_state นั้นคล้ายกับ np.random.seed ของ numpy คือเอาไว้ใช้เมื่อต้องการให้สุ่มได้ข้อมูลชุดเดิมๆ
ต่อไป ลองมาทดสอบการแบ่งกลุ่มข้อมูลพระจันทร์เสี้ยวนี้ด้วยแบบจำลองการแบ่งกลุ่มที่ต่างกัน ๔ แบบ
- การถดถอยโลจิสติก (逻辑回归, logistic regression)
- วิธีการเพื่อนบ้านใกล้สุด k ตัว (K-近邻算法, k-nearest neighbor, KNN)
- ต้นไม้ตัดสินใจ (决策树, decision tree)
- ป่าสุ่ม (随机森林, random forest)
แต่ละวิธีได้มีการแนะนำไปแล้วในบล็อกนี้ สามารถตามอ่านได้ >> หน้าสารบัญการเรียนรู้ของเครื่อง
เพื่อความสะดวก คราวนี้จะใช้แบบจำลองจากใน sklearn ทั้งหมด
เขียนได้ดังนี้
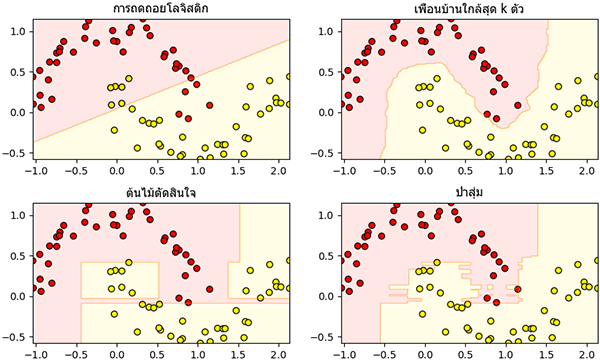
ผลจะเห็นว่าแบบจำลองแต่ละชนิดมีลักษณะการแบ่งที่ต่างกันออกไป สำหรับการถดถอยโลจิสติกนั้นเนื่องจากเป็นการแบ่งเชิงเส้น ดังนั้นจึงไม่มีทางแบ่งกลุ่มข้อมูลแบบนี้ออกมาได้สมบูรณ์ ส่วนแบบจำลองอื่นสามารถแบ่งได้ดีในแบบของตัวเอง
แต่นอกจากนั้นแล้วใน sklearn มีของเล่นคล้ายๆกันแบบนี้ที่สามารถสร้างขึ้นได้อีกมากมาย
ในที่นี้จะลองนำเอาอีกตัวคือ make_moons มาลองใช้เล่นดู
make_moons เป็นฟังก์ชันสำหรับสร้างข้อมูลรูปพระจันทร์เสี้ยว
ตัวอย่างการใช้
import matplotlib.pyplot as plt
from sklearn import datasets
X,z = datasets.make_moons(n_samples=80,noise=0.1)
plt.axes(aspect=1)
plt.scatter(X[:,0],X[:,1],c=z,edgecolor='k',cmap='autumn')
plt.show()จะเห็นว่าได้ช้อมูลที่มีการกระจายเป็นแบบคล้ายพระจันทร์เสี้ยว ๒ อันไขว้กัน
ข้อมูลในลักษณะนี้เหมาะกับการทดสอบแบบจำลองการแบ่งกลุ่มที่ไม่เป็นเชิงเส้น เช่นวิธีการเพื่อนบ้านใกล้สุด k ตัว หรือป่าสุ่ม
คีย์เวิร์ดที่ใส่เพื่อปรับแต่งได้มีแค่ ๔ ตัว ดังนี้
| ความหมาย | ค่าตั้งต้น | |
|---|---|---|
| n_samples | จำนวนข้อมูลทั้งหมด | 100 |
| shuffle | จะสุ่มการจัดเรียงแต่ละกลุ่มหรือไม่ | True |
| noise | ส่วนเบี่ยงเบนมาตรฐานของคลื่นรบกวนแบบเกาส์ที่เพิ่มเข้าไป | None |
| random_state | หมายเลขชุดของการสุ่ม | None |
noise เป็นตัวกำหนดการกระจายของจุด เช่นถ้าไม่ใส่ noise เลย หรือใส่ noise=0 ก็จะเป็นแบบนี้
X,z = datasets.make_moons(n_samples=80)
plt.axes(aspect=1).scatter(X[:,0],X[:,1],c=z,edgecolor='k',cmap='autumn')
plt.show()แต่ถ้าใส่ noise=1 ข้อมูลก็จะเริ่มกระจายมั่ว แยกไม่ค่อยออกแล้ว
X,z = datasets.make_moons(n_samples=80,noise=1)
plt.axes(aspect=1).scatter(X[:,0],X[:,1],c=z,edgecolor='k',cmap='autumn')
plt.show()ส่วน random_state นั้นคล้ายกับ np.random.seed ของ numpy คือเอาไว้ใช้เมื่อต้องการให้สุ่มได้ข้อมูลชุดเดิมๆ
ต่อไป ลองมาทดสอบการแบ่งกลุ่มข้อมูลพระจันทร์เสี้ยวนี้ด้วยแบบจำลองการแบ่งกลุ่มที่ต่างกัน ๔ แบบ
- การถดถอยโลจิสติก (逻辑回归, logistic regression)
- วิธีการเพื่อนบ้านใกล้สุด k ตัว (K-近邻算法, k-nearest neighbor, KNN)
- ต้นไม้ตัดสินใจ (决策树, decision tree)
- ป่าสุ่ม (随机森林, random forest)
แต่ละวิธีได้มีการแนะนำไปแล้วในบล็อกนี้ สามารถตามอ่านได้ >> หน้าสารบัญการเรียนรู้ของเครื่อง
เพื่อความสะดวก คราวนี้จะใช้แบบจำลองจากใน sklearn ทั้งหมด
เขียนได้ดังนี้
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
from sklearn.linear_model import LogisticRegression as Lori
from sklearn.neighbors import KNeighborsClassifier as Knn
from sklearn.tree import DecisionTreeClassifier as Ditri
from sklearn.ensemble import RandomForestClassifier as Rafo
model = [Lori(),Knn(),Ditri(),Rafo()]
chue = [u'การถดถอยโลจิสติก',u'เพื่อนบ้านใกล้สุด k ตัว',u'ต้นไม้ตัดสินใจ',u'ป่าสุ่ม']
X,z = datasets.make_moons(n_samples=80,noise=0.12,random_state=1)
nmesh = 200
mx,my = np.meshgrid(np.linspace(X[:,0].min(),X[:,0].max(),nmesh),np.linspace(X[:,1].min(),X[:,1].max(),nmesh))
mX = np.stack([mx.ravel(),my.ravel()],1)
plt.figure(figsize=[10,6])
for i,m in enumerate(model):
m.fit(X,z)
mz = m.predict(mX).reshape(nmesh,nmesh)
plt.subplot(221+i,xlim=[X[:,0].min(),X[:,0].max()],ylim=[X[:,1].min(),X[:,1].max()],aspect=1)
plt.scatter(X[:,0],X[:,1],c=z,edgecolor='k',cmap='autumn')
plt.contourf(mx,my,mz,alpha=0.1,cmap='autumn')
plt.title(chue[i],family='Tahoma')
plt.show()ผลจะเห็นว่าแบบจำลองแต่ละชนิดมีลักษณะการแบ่งที่ต่างกันออกไป สำหรับการถดถอยโลจิสติกนั้นเนื่องจากเป็นการแบ่งเชิงเส้น ดังนั้นจึงไม่มีทางแบ่งกลุ่มข้อมูลแบบนี้ออกมาได้สมบูรณ์ ส่วนแบบจำลองอื่นสามารถแบ่งได้ดีในแบบของตัวเอง
-----------------------------------------
囧囧囧囧囧囧囧囧囧囧囧囧囧囧囧囧囧囧囧囧囧囧囧囧囧
หมวดหมู่
-- คอมพิวเตอร์ >> ปัญญาประดิษฐ์-- คอมพิวเตอร์ >> เขียนโปรแกรม >> python >> numpy
-- คอมพิวเตอร์ >> เขียนโปรแกรม >> python >> matplotlib
-- คอมพิวเตอร์ >> เขียนโปรแกรม >> python >> sklearn