ตอนท้ายได้กล่าวถึงว่าการวิเคราะห์ในลักษณะนี้สามารถพัฒนาต่อไปสู่การจำแนกประเภทกลุ่มของข้อมูลเป็นมากกว่าสองได้ด้วย และนั่นคือสิ่งที่จะเขียนถึงในคราวนี้
ขอเริ่มจากยกตัวอย่างปัญหาที่ต้องการจะแก้ขึ้นมา
สมมุติว่ามีเกมอยู่เกมหนึ่งซึ่งภายในเกมมีการเลี้ยงพญานาค โดยต้องเลี้ยงตั้งแต่เด็กแล้วพอถึงอายุถึงกำหนดก็จะเปลี่ยนร่างเป็นร่างสมบูรณ์
พญานาคร่างสมบูรณ์ไม่ได้มีเพียงรูปแบบเดียว แต่จะต่างกันออกไปขึ้นอยู่กับว่าตอนเด็กอยู่ให้อาหารอะไรไปแค่ไหน
สมมุติว่าอาหารพญานาคในเกมนี้มีแค่ ๒ อย่างคือผักและปลา มีผู้เล่นคนหนึ่งลองเลี้ยงซ้ำทั้งหมดร้อยครั้งแล้วให้อาหารปริมาณต่างกันออกไป ผลที่ได้ออกมาตามนี้
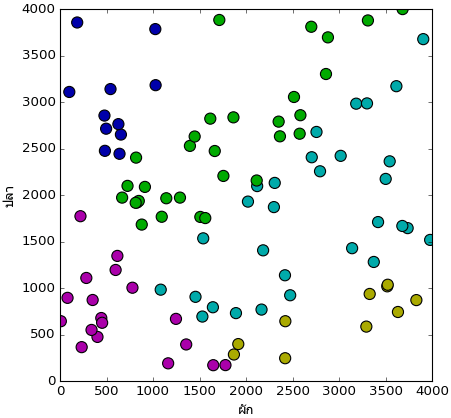
จากภาพนี้ผลที่ได้จำแนกตามพื้นที่ออกเป็น ๕ ส่วน ดังนี้
0. สีม่วง ไม่เปลี่ยนร่าง
1. สีเหลือง พญานาคเหลือง
2. สีฟ้า พญานาคฟ้า
3. สีเขียว พญานาคเขียว
4. สีน้ำเงิน พญานาคน้ำเงิน
แค่มองจากตรงนี้ก็คงพอเห็นภาพคร่าวๆแล้วว่ามีกฎเกณฑ์การจำแนกเป็นยังไง
ความจริงแล้วข้อมูลชุดนี้ถูกสร้างขึ้นมาด้วยโค้ดนี้
import matplotlib.pyplot as plt
# สุ่มจำนวนผักและปลา
phak = np.random.randint(0,4000,100)
pla = np.random.randint(0,4000,100)
# กำหนดว่าจะเปลี่ยนเป็นร่างไหน
plianrang = np.tile([1],100)
plianrang[phak-pla*2<1000] = 2
plianrang[phak-pla<0] = 3
plianrang[phak*2-pla<-1000] = 4
plianrang[phak+pla<2000] = 0
# บันทึกข้อมูลเก็บไว้ใช้
np.savez('liangphayanak.npz',x=phak,y=pla,z=plianrang)
# กำหนดสีแทนแต่ละกลุ่ม
si = ['#aa00aa','#aaaa00','#00aaaa','#00aa00','#0000aa']
# แปลงเลขเป็นรหัสสี
c = [si[i] for i in plianrang]
# วาดแผนภาพการกระจาย
plt.figure(figsize=[6,6])
ax = plt.axes(xlim=[0,4000],ylim=[0,4000],aspect=1)
ax.set_xlabel(u'ผัก',fontname='Tahoma')
ax.set_ylabel(u'ปลา',fontname='Tahoma')
ax.scatter(phak,pla,c=c,s=100,edgecolor='k')
plt.show()
หมายเลขที่อยู่ในตัวแปร plianrang แสดงถึงว่าจะเปลี่ยนเป็นร่างไหน ตามเลขที่เขียนไว้ข้างต้น
ได้
0 2 0 1 2 3 2 3 3 3 2 1 2 0 2 1 3 2 1 3 4 0 0 4 3 0 2 3 4 0 4 3 2 1 2 2 2
1 3 0 4 0 3 2 3 2 3 4 0 4 2 1 3 3 3 3 0 0 3 3 0 2 2]
ดูโค้ดตรงนี้แล้วเราคงเข้าในกฎเกณฑ์การจำแนกเป็นอย่างดี อย่างไรก็ตาม จากตรงนี้จะลืมโค้ดข้างต้นนี้ไปให้หมด แล้วตั้งคำถามว่าจะขีดเส้นแบ่งพื้นที่อย่างไรดีโดยดูจากผลที่ได้ในรูปนี้ หากมีการเลี้ยงพญานาคตัวใหม่อีกครั้งเราจะทำนายได้ว่าจะได้ร่างอะไรโดยดูจากปริมาณอาหารที่ให้
เราจะเขียนโปรแกรมให้เครื่องทำการเรียนรู้ที่จะลากเส้นแบ่งเองโดยที่มันไม่รู้ที่มาของข้อมูล ไม่รู้ว่าเราใช้สูตรอะไรจึงได้อย่างนี้มา ข้อมูลที่เราจะป้อนให้มีแค่ค่าตัวแปรต้นและผลที่ได้เท่านั้น
โจทย์ครั้งนี้ใกล้เคียงกับเรื่องการปลูกถั่วที่ยกไปแล้ว เป็นปัญหาสองมิติ (มีตัวแปรต้น ๒ ตัว) เหมือนกัน ต่างกันตรงที่ว่าถั่วเราสนใจแค่ว่างอกหรือไม่งอก มีแค่ ๒ คำตอบ แต่พญานาคเราสนใจว่ามันจะกลายเป็นร่างอะไร มีมากถึง ๕ คำตอบ
การวิเคราะห์การถดถอยโลจิสติกสำหรับการจำแนกประเภทข้อมูลเป็นหลายกลุ่มนั้นเรียกว่าการถดถอยโลจิสติกแบบมัลติโนเมียล (multinomial logistic regression) และบางครั้งก็ถูกเรียกว่าการถดถอยซอฟต์แม็กซ์ (softmax regression) ในที่นี้ก็จะเรียกแบบนั้นเพื่อแยกให้ชัด
ในการวิเคราะห์การถอถอยซอฟต์แม็กซ์จะใช้ฟังก์ชันที่เรียกว่าซอฟต์แม็กซ์ (softmax) เพื่อหาความน่าจะเป็นที่จะอยู่ในกลุ่มใดๆ ซึ่งต่างจากการวิเคราะห์การถดถอยโลจิสติกที่ใช้ฟังก์ชันซิกมอยด์
ในตอนที่จำแนกข้อมูลเป็นสองกลุ่มนั้นในขั้นตอนก่อนสุดท้ายซึ่งหาความน่าจะเป็นนั้นเราใช้ฟังก์ชันซิกมอยด์ ผลที่ได้คือค่าความน่าจะเป็นที่ข้อมูลอันหนึ่งๆจะอยู่ในกลุ่มหนึ่ง ค่าที่ได้อยู่ระหว่าง 0 ถึง 1 และความน่าจะเป็นที่จะอยู่อีกกลุ่มก็เอาค่าที่ได้นี้ไปหักออกจาก 1 อีกที เพราะรวมแล้วต้องเท่ากับ 1
แต่พอมีการจำแนกมากกว่าสองกลุ่มจะใช้วิธีแบบนั้นไม่ได้แล้ว เพราะถึงคำนวณความน่าจะเป็นที่จะถูกจัดอยู่ในกลุ่มหนึ่งได้แล้วหักออกจาก 1 ไปก็ไม่รู้ว่าความน่าจะเป็นที่เหลืออยู่นั้นเป็นของกลุ่มไหนในกลุ่มที่เหลือ
ดังนั้นจึงจำเป็นจะต้องหาความน่าจะเป็นของทุกกลุ่มพร้อมๆกันแล้วนำมาคำนวณเปรียบเทียบอีกที
เพื่อให้เห็นภาพชัดลองเขียนเป็นแผนภาพดู ขอยกตัวอย่างกรณีที่มีตัวแปรต้น ๒ ตัว เช่นในโจทย์ข้อนี้ x คือจำนวนผักและ y คือจำนวนปลา
ถ้าเป็นสำหรับกรณีการถดถอยโลจิสติกแบบเดิมจะเขียนได้แบบนี้
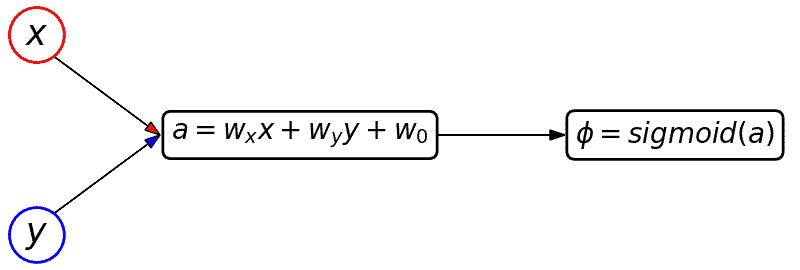
ส่วนกรณีการถดถอยซอฟต์แม็กซ์จะเป็นแบบนี้
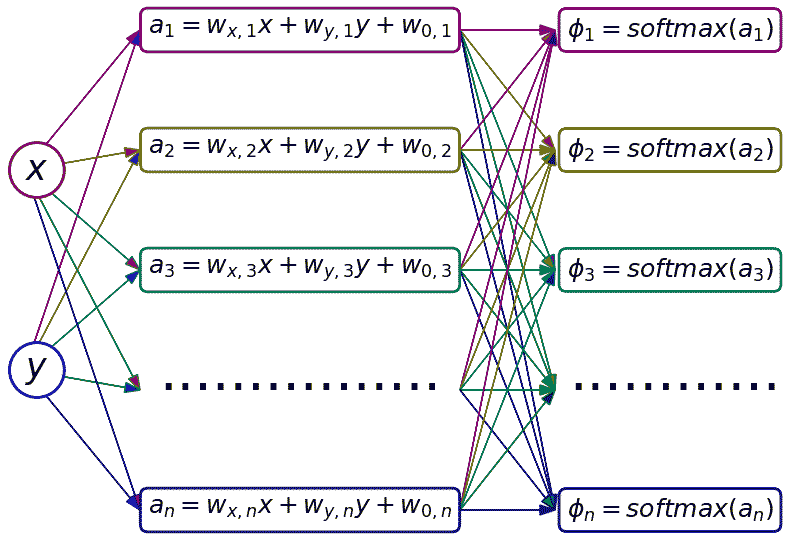
จะเห็นว่าจำนวนข้อมูลที่ต้องคำนวณเพิ่มเป็นจำนวน n ตามจำนวนกลุ่มที่จะจำแนก และฟังก์ชันสำหรับคำนวณความน่าจะเป็นในท้ายสุดที่เข้ามาแทนที่ฟังก์ชันซิกมอยด์ก็คือฟังก์ชันซอฟต์แม็กซ์
ฟังก์ชันซอฟต์แม็กซ์นิยามดังนี้
...
โดยที่ n เป็นจำนวนกลุ่มประเภทของข้อมูลที่ต้องการจะจำแนก
เทียบกับซิกมอยด์แล้วจะดูคล้ายกันมาก ที่จริงแล้วซอฟต์แม็กซ์คือซิกมอยด์ที่ทำให้เป็นรูปทั่วไปมากขึ้น และสามารถเห็นได้ว่าถ้าจำนวนกลุ่มมีแค่สองฟังก์ชันซอฟต์แม็กซ์จะเกือบเหมือนกับซิกมอยด์
และจากทั้งสมการจะเห็นได้ว่าการคำนวณซอฟต์แม็กซ์ต้องใช้ค่า a ที่ได้จากการคำนวณทุกกลุ่ม ดังนั้นลูกศรในภาพจึงระโยงระยางลากเชื่อมทุกตัว
การเขียนฟังก์ชันซอฟต์แม็กซ์ขึ้นมาในไพธอนนั้นมีความซับซ้อนเล็กน้อย จึงขอแยกไปอธิบายในหน้าอื่น สำหรับผู้ที่สนใจตามอ่านได้ที่ https://phyblas.hinaboshi.com/20161206
ผลลัพธ์ที่ได้จากซอฟต์แม็กซ์จะได้ออกมาจำนวนเท่ากับจำนวนกลุ่ม โดยเป็นค่าความน่าจะเป็นที่จะอยู่ในกลุ่มนั้นๆ ซึ่งถ้าเอามารวมกันทั้งหมดจะได้เป็น 1 เสมอ
ในขณะที่ผลลัพธ์จริงๆที่เราป้อนเข้าไปเพื่อให้โปรแกรมเรียนรู้นั้นคือสิ่งที่เรารู้แน่ชัดอยู่แล้วว่าอยู่กลุ่มไหน ดังนั้นจะอยู่ในรูปที่มีอยู่อันเดียวที่เป็น 1 อันที่เหลือเป็น 0 ลักษณะข้อมูลแบบนี้เรียกว่าวันฮ็อต (one-hot)
เช่นผลอาจทำนายว่าความน่าจะเป็นของแต่ละกลุ่มคือ 0.05,0.9,0.01,0.005,0.035
ในขณะที่ผลจริงๆอาจเป็น 0,1,0,0,0 เป็นต้น
สำหรับในตัวอย่างที่เรายกขึ้นมาข้างต้นนั้นผลการเปลี่ยนร่างที่ถูกเก็บอยู่ในตัวแปร plianrang นั้นอยู่ในรูปตัวเลข 0 ถึง 4 ข้อมูลตรงนี้ยังใช้ไม่ได้ทันทีจำเป็นต้องทำการแปลงให้อยู่ในรูปดังที่ว่าก่อน
การแปลงสามารถทำได้โดยเขียนแบบนี้
print(plianrang_1h[:12]) # แสดง ๑๒ แถวแรกดู
ผลที่ได้คือถ้าค่าใน plianrang เป็นเลขไหน ค่าใน plianrang_1h ก็จำเป็น 1 ในตำแหน่งนั้น และที่เหลือเป็น 0
[1 0 0 0 0]
[0 0 0 1 0]
[0 0 1 0 0]
[0 0 1 0 0]
[0 0 1 0 0]
[0 0 1 0 0]
[0 1 0 0 0]
[0 0 1 0 0]
[0 0 0 1 0]
[0 0 0 1 0]
[0 0 0 0 1]]
ในที่นี้โค้ดอาจดูเข้าใจยากสักหน่อย ในนี้ [:,None] เป็นการเปลี่ยนอาเรย์จากหนึ่งมิติให้เป็นสองมิติ หรือจะเขียนเป็น .reshape(1,-1) ก็ได้เช่นกัน
ในขณะที่ range(5) จะเป็นอาเรย์หนึ่งมิติ เมื่อนำมาเข้าคู่คำนวณกันจะเป็นการแจกแจง ผลที่ได้คือเป็นอาเรย์ที่มีรูปร่างเป็นจำนวนข้อมูลคูณด้วย 5
และ +0 ที่เติมเข้าไปนี้แค่เพื่อเปลี่ยนให้ค่าเป็นชนิดจำนวนเต็มเท่านั้น เพราะที่ได้จากการคำนวณทางตรรกะจะเป็นชนิดบูล (True False) ที่จริงจะใช้ .astype(int) แทนก็ได้ แต่เขียนแบบนี้สั้นกว่ามาก
แต่ที่จริงจะไม่เปลี่ยนเป็น int ก็ได้ ปล่อยให้เป็น True False ไปทั้งอย่างนั้นก็นำมาใช้ในการคำนวณได้เช่นกัน โดย True=1 False=0 ดังนั้นในตัวอย่างโค้ดที่จะเขียนจะใช้ทั้งๆแบบนั้น ไม่ใส่ +0
อีกเรื่องที่จะต้องมาคิดก็คือเรื่องค่าน้ำหนักและไบแอสของแบบจำลอง
ถ้าเป็นการถดถอยโลจิสแบบเดิมสมการที่ใช้คำนวณคือ wx+wy+w0 นั่นคือมีค่าน้ำหนักแค่ ๒ ตัวคือ wx และ wy และไบแอสคือ w0
แต่กรณีถดถอยซอฟต์แม็กซ์เราต้องคิดแยกกันเป็นหลายอัน ดังนั้นจึงมี wx, wy และ w0 อย่างละหลายอัน
นั่นคือจะเป็น wx[0], wx[1], ... กับ wy[0], wy[1], ... แล้วก็ w0[0], w0[1], ...
และเวลาที่คำนวณก็จะเป็น wx[n]*x[:,n]+wy[n]*y[:,n]+w0[n] แบบนี้ เป็นต้น
ดูแล้วยุ่งยากขึ้นมากทีเดียว และที่จะยุ่งยากขึ้นไปอีกคือเรื่องการหาค่าความชันของฟังก์ชันเพื่อที่จะคำนวณการเปลี่ยนแปลงค่าน้ำหนักและไบแอส
ลองไล่คิดดูทีละขั้น เริ่มจากฟังก์ชันค่าเสียหาย ในที่นี้ใช้เป็นผลรวมความคลาดเคลื่อนกำลังสองเช่นเดียวกับที่ใช้ในการถดถอยโลจิสติก แต่เมื่อมีค่าของหลายกลุ่มดังนั้นจึงต้องรวมทุกกลุ่ม เขียนสมการก็จะได้แบบนี้
..(1)
ในที่นี้ i คือดัชนีของแถวข้อมูล ส่วน k คือดัชนีของกลุ่ม
z คือคำตอบจริงซึ่งอยู่ในรูปของ one-hot
ส่วน φ สำหรับในที่นี้คือค่าที่คำนวณจากฟังก์ชันซอฟต์แม็กซ์
..(2)
โดย H คือผลรวมของตัวแปรต้นคูณน้ำหนักในแต่ละมิติ
..(3)
โดย wj คือค่าน้ำหนักในมิติต่างๆ ในที่นี้เป็นสองมิติจะมี ๓ ตัวคือ wx wy และ w0 และแต่ละตัวยังมี m ห้อยต่อท้าย m ในที่นี้เป็นดัชนีแสดงถึงกลุ่ม เช่นเดียวกับ k
เราต้องการค่าความเปลี่ยนแปลงของค่าเสียหายเทียบกับน้ำหนักต่าง ซึ่งสามารถคำนวณได้จากกฎลูกโซ่ นั่นคือ
..(4)
ก้อนแรกคือจากสมการ (1) มาหาอนุพันธ์ของค่าเสียหายเทียบกับ φ ได้
..(5)
ก้อนต่อมาคือจากสมการ (2) หาอนุพันธ์ของ φ เทียบกับ a ได้
..(6)
ในที่นี้ δ คือเดลตาของโครเน็กเกอร์ จะเป็น 1 เมื่อ k=m และเป็น 0 เมื่อ k≠m
ก้อนสุดท้ายได้จากสมการ (3) หาอนุพันธ์ของ a เทียบกับ xj ได้
..(7)
หรือถ้าแทน xj ด้วย x, y และ wj ด้วย wx, wy, w0 จะได้
..(8)
นำ (5)(6)(7) แทนลงใน (4) จะได้
..(9)
หรือถ้าแทน (5)(6)(8) จะได้
..(10)
สุดท้ายคำนวณค่าน้ำหนักที่ควรจะเปลี่ยนในแต่ละรอบการเรียนรู้ได้โดย
..(11)
โดย η คืออัตราการเรียนรู้
แทน (9) ลงใน (11)
..(12)
หรือแทน (10) ลงใน (11) จะได้
..(13)
สมการนี้คือสมการที่เราจะใช้ในโปรแกรมวิเคราะห์การถดถอยซอฟต์แม็กซ์
เมื่อได้สมการมาแล้วต่อมาก็นำมาใช้เขียนโค้ดได้เลย ในที่นี้ก่อนเริ่มเข้าสู่ส่วนการเรียนรู้จะมีการทำข้อมูลให้เป็นมาตรฐาน และมีการปรับค่าน้ำหนักกลับหลังเรียนรู้เสร็จ ดังที่อธิบายไปในนี้ด้วย https://phyblas.hinaboshi.com/20161124
โค้ดตั้งแต่เริ่มโหลดข้อมูลอาหารพญานาคมาแล้วก็ทำการเรียนรู้เพื่อปรับน้ำหนักเสร็จเรียบร้อย
exp_x = np.exp(x.T-x.max(1))
return (exp_x/exp_x.sum(0)).T
eta = 0.001 # อัตราการเรียนรู้
n_thamsam = 10000 # จำนวนครั้งที่ทำซ้ำเพื่อปรับค่าน้ำหนักและไบแอส
liangphayanak = np.load('liangphayanak.npz') # โหลดข้อมูลการเลี้ยงพญานาคที่บันทึกไว้
phak = liangphayanak['x'] # จำนวนผัก
pla = liangphayanak['y'] # จำนวนปลา
plianrang = liangphayanak['z'] # ร่างที่เปลี่ยน
ahan = np.stack([phak,pla],1) # รวมผักกับปลาเป็นอาเรย์สองมิติของอาหารทั้งหมด
kiklum = int(plianrang.max()+1) # จำนวนกลุ่ม
plianrang_1h = plianrang[:,None]==range(kiklum) # ทำเป็น one-hot
ahan_std = ahan.std(0) # หาส่วนเบี่ยงเบนมาตรฐาน
ahan_mean = ahan.mean(0) # หาค่าเฉลี่ย
X = (ahan-ahan_mean)/ahan_std # ทำข้อมูลให้เป็นมาตรฐาน
# ค่าน้ำหนักเริ่มต้น
wx = np.zeros(kiklum)
wy = np.zeros(kiklum)
w0 = np.zeros(kiklum)
khasiahai = [] # ลิสต์เก็บค่าเสียหาย
thuktong = [] # ลิสต์เก็บค่าจำนวนครั้งที่ทายถูก
# คำนวณความน่าจะเป็นของแต่ละกลุ่มจากค่าน้ำหนักตอนแรก
phi = softmax(wx*X[:,0:1]+wy*X[:,1:2]+w0)
# เริ่มการทำซ้ำเพื่อปรับค่าน้ำหนัก
for i in range(n_thamsam):
# คำนวณค่าและปรับค่าน้ำหนักทีละกลุ่ม
for n in range(kiklum):
delta_nm = np.zeros(kiklum)
delta_nm[n] = 1
eee = 2*(phi*(delta_nm-phi[:,n:n+1])*(plianrang_1h-phi)).sum(1)*eta
wx[n] += (eee*X[:,0]).sum()
wy[n] += (eee*X[:,1]).sum()
w0[n] += eee.sum()
# คำนวณความน่าจะเป็นของแต่ละกลุ่มจากค่าน้ำหนักที่ปรับแล้ว
phi = softmax(wx*X[:,0:1]+wy*X[:,1:2]+w0)
# คำนวณค่าเสียหายแล้วเก็บใส่ลิสต์
khasiahai += [((plianrang_1h-phi)**2).sum()]
# เทียบว่าอันไหนทายถูกบ้าง
thukmai = plianrang==phi.argmax(1)
# นับจำนวนว่าถูกกี่อันแล้วเก็บใส่ลิสต์
thuktong += [thukmai.sum()]
# ปรับค่าน้ำหนักให้เข้ากับข้อมูลเดิมที่ไม่ได้ปรับมาตรฐาน
wx /= ahan_std[0]
wy /= ahan_std[1]
w0 -= wx*ahan_mean[0]+wy*ahan_mean[1]
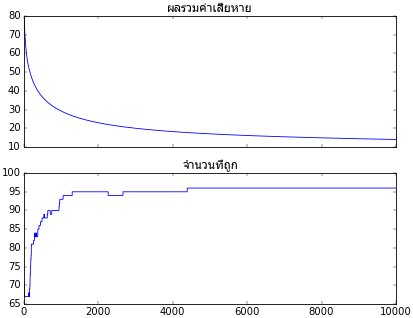
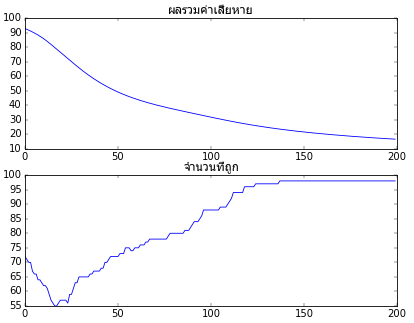
ค่าเสียหายและจำนวนที่ทายถูกที่เปลี่ยนแปลงไประหว่างการเรียนรู้ถูกบันทึกเอาไว้ในตัวแปร khasiahai และ thuktong ลองนำมาวาดกราฟ
ax.set_title(u'ผลรวมค่าเสียหาย',fontname='Tahoma')
plt.plot(khasiahai)
plt.tick_params(labelbottom='off')
ax = plt.subplot(212)
ax.set_title(u'จำนวนที่ถูก',fontname='Tahoma')
plt.plot(thuktong)
plt.show()
จะเห็นว่าการเรียนรู้คืบหน้าไปตามที่ต้องการ ยิ่งผ่านไปยิ่งทายถูกมากขึ้นเรื่อยๆจนเกือบถูกหมด
จากนั้นลองวาดภาพแสดงผลการจำแนกประเภทดู โดยสร้างโครงข่ายตามแกน x และ y ขึ้นมาด้วย np.meshgrid จากนั้นทำนายผลว่าในแต่ละจุดบนโครงข่ายนี้ควรจัดอยู่ในกลุ่มไหนโดยใช้ค่าน้ำหนักที่ได้มาจากการเรียนรู้ จากนั้นวาดจุดกระจายทั่วด้วย scatter แล้ววาดเส้นคั่นด้วย contour
ax = plt.axes(xlim=[0,4000],ylim=[0,4000],aspect=1)
ax.set_xlabel(u'ผัก',fontname='Tahoma')
ax.set_ylabel(u'ปลา',fontname='Tahoma')
# สร้างโครงข่ายตามแนว x และ y
nmesh = 200
mx,my = np.meshgrid(np.linspace(0,4000,nmesh),np.linspace(0,4000,nmesh))
mx = mx.ravel()
my = my.ravel()
# ทำนายเลขกลุ่มด้วยน้ำหนักที่ได้มาจากการเรียนรู้
mz = (wx*mx[:,None]+wy*my[:,None]+w0).argmax(1)
# ค่าสีของแต่ละกลุ่ม
si = ['#770077','#777700','#007777','#007700','#000077']
# วาดจุดกระจายเป็นฉากหลังซึ่งมีสีต่างไปตามกลุ่ม
for i in range(kiklum):
ax.scatter(mx[mz==i],my[mz==i],c=si[i],s=2,marker='s',alpha=0.2,lw=0)
# วาดเส้นแบ่งเขต
ax.contour(mx.reshape(nmesh,nmesh),my.reshape(nmesh,nmesh),mz.reshape(nmesh,nmesh),
kiklum,colors='k',linewidths=3,zorder=0)
# แปลงเลขกลุ่มเป็นรหัสสี
c = np.array([si[i] for i in plianrang])
# วาดจุดที่ถูก
ax.scatter(phak[thukmai],pla[thukmai],c=c[thukmai],s=100,edgecolor='k')
# วาดจุดที่ผิด มีขอบเป็นสีแดง
ax.scatter(phak[~thukmai],pla[~thukmai],c=c[~thukmai],s=100,edgecolor='r',lw=2)
plt.show()
ได้ภาพที่มีการแบ่งเขตเป็นสีต่างๆอย่างสวยงาม และมีจุดสีต่างๆซึ่งสอดคล้องกับสีของเขตนั้นๆ สีที่อยู่ผิดเขตจะมีขอบแดงล้อม หมายถึงทายผิด
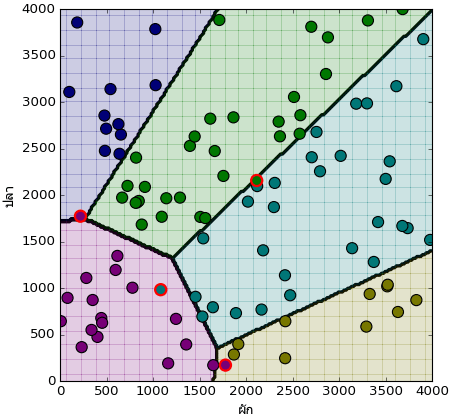
การจำแนกกลุ่มด้วยการถดถอยโลจิสติกนั้นเส้นแบ่งที่ได้จะเป็นเส้นตรงเสมอ เพราะได้จากการคำนวณเชิงเส้น การถดถอยซอฟต์แม็กซ์ก็เช่นกัน แม้จะมีหลายเส้นแบ่งแต่ทั้งหมดก็คือเส้นตรง
เรื่องหนึ่งที่น่าสังเกตก็คือ ฟังก์ชันซอฟต์แม็กซ์ไม่ได้ทำให้ลำดับการจัดเรียงค่าเปลี่ยนไป กล่าวคือตัวไหนมีค่ามากสุดก็ยังมากสุดอยู่ ดังนั้นหากแค่จะใช้ argmax เพื่อหาว่าอันไหนมีค่ามากสุดเพื่อทำนายว่าอยู่กลุ่มไหน กรณีแบบนี้ไม่ต้องผ่านซอฟต์แม็กซ์ ใช้ค่าที่ได้จากผลรวมของผลคูณน้ำหนักกับตัวแปรต้นได้เลย
นั่นคือ thukmai = phi.argmax(1) จะเปลี่ยนเป็น (wx*X[:,0:1]+wy*X[:,1:2]+w0).argmax(1) ก็ไม่ต่างกัน
ฟังก์ชันซอฟต์แม็กซ์ใช้แค่เมื่อต้องการคำนวณค่าเสียหายเพื่อนำมาใช้ในการเรียนรู้เท่านั้น
เมื่อได้ผลตามที่ต้องการสำเร็จแล้วต่อไปเราจะมาปรับปรุงให้ดีขึ้นด้วยการเขียนในรูปของคลาสเพื่อให้เป็นระบบใช้งานง่าย
พร้อมกันนั้นก็ปรับให้สามารถรองรับข้อมูลที่เป็นกี่มิติก็ได้โดยไม่จำเป็นต้องเป็นสองมิติ
คลาสของแบบจำลองการถดถอยซอฟต์แม็กซ์ที่ได้จะออกมาเป็นแบบนี้
import matplotlib.pyplot as plt
def softmax(x):
exp_x = np.exp(x.T-x.max(1))
return (exp_x/exp_x.sum(0)).T
class ThotthoiSoftmax:
def __init__(self,eta):
self.eta = eta
# เรียนรู้
def rianru(self,X,z,n_thamsam):
self.kiklum = int(z.max()+1)
X_std = X.std(0)
X_std[X_std==0] = 1
X_mean = X.mean(0)
# ปรับ X ให้เป็นมาตรฐาน
X = (X-X_mean)/X_std
# ทำข้อมูล z ในแบบ one-hot
z_1h = z[:,None]==range(self.kiklum)
# ใส่ค่าน้ำหนักเริ่มต้นเป็น 0 ทุกตัว
self.w = np.zeros([X.shape[1]+1,self.kiklum])
self.khasiahai = []
self.thuktong = []
phi = self.ha_softmax(X)
#เริ่มการเรียนรู้
for i in range(n_thamsam):
# คำนวณและปรับค่าน้ำหนักของแต่ละกลุ่ม
for n in range(self.kiklum):
delta_nm = np.zeros(self.kiklum)
delta_nm[n] = 1
eee = 2*(phi*(delta_nm-phi[:,n:n+1])*(z_1h-phi)).sum(1)*self.eta
self.w[1:,n] += (eee[:,None]*X).sum(0)
self.w[0,n] += eee.sum()
phi = self.ha_softmax(X)
# เปรียบเทียบค่าที่ทายได้กับคำตอบจริง
thukmai = phi.argmax(1)==z
# บันทึกจำนวนที่ถูกและค่าเสียหาย
self.thuktong += [thukmai.sum()]
self.khasiahai += [self.ha_khasiahai(X,z_1h)]
# ปรับค่าน้ำหนักให้เข้ากับข้อมูลเดิมที่ไม่ได้ปรับมาตรฐาน
self.w[1:] /= X_std[:,None]
self.w[0] -= (self.w[1:]*X_mean[:,None]).sum(0)
# ทำนายว่าอยู่กลุ่มไหน
def thamnai(self,X):
return self.ha_softmax(X).argmax(1)
# หาความน่าจะเป็นที่จะอยู่ในแต่ละกลุ่ม
def ha_softmax(self,X):
return softmax(np.dot(X,self.w[1:])+self.w[0])
# หาค่าเสียหาย
def ha_khasiahai(self,X,z_1h):
return ((z_1h-self.ha_softmax(X))**2).sum()
ลองนำมาใช้งานโดยใช้ข้อมูลชุดเดิมและให้แสดงผลเหมือนเดิม
phak = liangphayanak['x']
pla = liangphayanak['y']
plianrang = liangphayanak['z']
ahan = np.stack([phak,pla],1)
eta = 0.001
n_thamsam = 1000
ts = ThotthoiSoftmax(eta) # สร้างออบเจ็กต์จากคลาส
ts.rianru(ahan,plianrang,n_thamsam) # เริ่มการเรียนรู้
ax = plt.subplot(211)
ax.set_title(u'ผลรวมค่าเสียหาย',fontname='Tahoma')
plt.plot(ts.khasiahai)
ax = plt.subplot(212)
ax.set_title(u'จำนวนที่ถูก',fontname='Tahoma')
plt.plot(ts.thuktong)
plt.figure(figsize=[6,6])
ax = plt.axes(xlim=[0,4000],ylim=[0,4000],aspect=1)
ax.set_xlabel(u'ผัก',fontname='Tahoma')
ax.set_ylabel(u'ปลา',fontname='Tahoma')
nmesh = 200
mx,my = np.meshgrid(np.linspace(0,4000,nmesh),np.linspace(0,4000,nmesh))
mx = mx.ravel()
my = my.ravel()
mX = np.stack([mx,my],1)
mz = ts.thamnai(mX)
si = ['#770077','#777700','#007777','#007700','#000077']
for i in range(ts.kiklum):
ax.scatter(mx[mz==i],my[mz==i],c=si[i],s=2,marker='s',alpha=0.2,lw=0)
ax.contour(mx.reshape(nmesh,nmesh),my.reshape(nmesh,nmesh),mz.reshape(nmesh,nmesh),
ts.kiklum,colors='k',linewidths=3,zorder=0)
thukmai = ts.thamnai(ahan)==plianrang
c = np.array([si[i] for i in plianrang])
ax.scatter(phak[thukmai],pla[thukmai],c=c[thukmai],s=100,edgecolor='k')
ax.scatter(phak[~thukmai],pla[~thukmai],c=c[~thukmai],s=100,edgecolor='r',lw=2)
plt.show()
ผลที่ได้จะออกมาเหมือนกับตอนที่ไม่ใช้คลาส
ต่อมาลองทดสอบกับข้อมูลอื่น เช่นใช้ datasets.make_blobs ของ sklearn ดังที่ได้เคยลองใช้ใน https://phyblas.hinaboshi.com/20161127
X,z = datasets.make_blobs(n_samples=1000,n_features=2,centers=6,random_state=36)
eta = 0.001
n_thamsam = 1000
ts = ThotthoiSoftmax(eta)
ts.rianru(X,z,n_thamsam)
ax = plt.axes(xlim=[X[:,0].min(),X[:,0].max()],ylim=[X[:,1].min(),X[:,1].max()],aspect=1)
nmesh = 200
mx,my = np.meshgrid(np.linspace(X[:,0].min(),X[:,0].max(),nmesh),np.linspace(X[:,1].min(),X[:,1].max(),nmesh))
mx = mx.ravel()
my = my.ravel()
mX = np.stack([mx,my],1)
mz = ts.thamnai(mX)
si = ['#770077','#777700','#007777','#007700','#000077','#770000']
for i in range(ts.kiklum):
ax.scatter(mx[mz==i],my[mz==i],c=si[i],s=2,marker='s',alpha=0.2,lw=0)
ax.contour(mx.reshape(nmesh,nmesh),my.reshape(nmesh,nmesh),mz.reshape(nmesh,nmesh),
ts.kiklum,colors='k',linewidths=3,zorder=0)
thukmai = ts.thamnai(X)==z
c = np.array([si[i] for i in z])
ax.scatter(X[thukmai,0],X[thukmai,1],c=c[thukmai],s=100,edgecolor='k')
ax.scatter(X[~thukmai,0],X[~thukmai,1],c=c[~thukmai],s=100,edgecolor='r',lw=2)
plt.show()
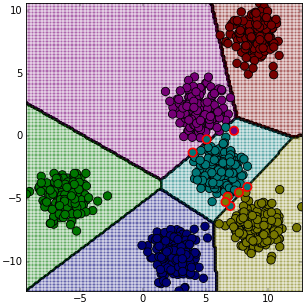
ลองทดสอบใช้กับข้อมูลที่มีมิติสูงขึ้นดูด้วย เช่น ลองจำแนกข้อมูล ๑๕ มิติเป็น ๕ กลุ่ม คราวนี้แสดงแค่กราฟความคืบหน้าในการเรียนรู้
eta = 0.01
n_thamsam = 200
ts = ThotthoiSoftmax(eta)
ts.rianru(X,z,n_thamsam)
ax = plt.subplot(211)
ax.set_title(u'ผลรวมค่าเสียหาย',fontname='Tahoma')
plt.plot(ts.khasiahai)
ax = plt.subplot(212)
ax.set_title(u'จำนวนที่ถูก',fontname='Tahoma')
plt.plot(ts.thuktong)
plt.show()
เท่านี้เราก็สามารถเขียนโปรแกรมเพื่อจำแนกประเภทข้อมูลอย่างง่ายได้แล้ว
ที่จริงยังมีอะไรต้องปรับปรุงอีกมากมายเพื่อให้เหมาะแก่การใช้งานจริงมากขึ้น ที่สำคัญอย่างหนึ่งก็คือการเปลี่ยนฟังก์ชันค่าเสียหาย ซึ่งในตัวอย่างที่ผ่านๆมาเราใช้เป็นผลรวมความคลาดเคลื่อนกำลังสอง แต่โดยทั่วไปแล้วเอนโทรปีไขว้ (cross entropy) เป็นที่นิยมมากกว่า
จากตัวอย่างในบทความนี้จะเห็นว่าสมการและโค้ดในส่วนคำนวณความชันนั้นดูแล้วยุ่งยากซับซ้อน แต่หากใช้เอนโทรปีไขว้เป็นฟังก์ชันค่าเสียหายแทนก็จะดูซับซ้อนน้อยลง เหมาะแก่การใช้งานจริงมากกว่า
อ่านต่อเรื่องการปรับแก้เป็นใช้เอนโทรปีไขว้ได้ที่ https://phyblas.hinaboshi.com/20161207
อ้างอิง
-----------------------------------------
囧囧囧囧囧囧囧囧囧囧囧囧囧囧囧囧囧囧囧囧囧囧囧囧囧
หมวดหมู่
-- คอมพิวเตอร์ >> ปัญญาประดิษฐ์-- คอมพิวเตอร์ >> เขียนโปรแกรม >> python >> numpy
-- คอมพิวเตอร์ >> เขียนโปรแกรม >> python >> matplotlib