การทำป่าสุ่มโดยใช้ sklearn
เขียนเมื่อ 2017/11/17 10:10
แก้ไขล่าสุด 2022/07/21 15:04
ตอนที่แล้วแนะนำวิธีการสร้างป่าสุ่มอย่างง่ายไป https://phyblas.hinaboshi.com/20171111
คราวนี้จะใช้ sklearn สร้างบ้าง
ป่าสุ่มเป็นส่วนหนึ่งของวิธีการแบบอ็องซ็องบล์ (ensemble) จึงอยู่ในมอดูลย่อย sklearn.ensemble
วิธีการใช้ก็ทำนองเดียวกับต้นไม้ตัดสินใจ อาร์กิวเมนต์ต่างๆสำหรับปรุงแต่งต้นไม้ก็สามารถใส่ในป่าสุ่มได้เช่นกัน
รายละเอียดที่สามารถปรับได้มีมากมาย แต่ในที่นี้จะพูดถึงแค่ส่วนหนึ่ง รายละเอียดอื่นๆก็ดูได้ใน http://scikit-learn.org/stable/modules/generated/sklearn.ensemble.RandomForestClassifier.html
ตัวอย่างการใช้ ลองสร้างข้อมูลที่เป็นกระจุกก้อน ๕ กลุ่ม แล้วแบ่งด้วยป่าสุ่ม
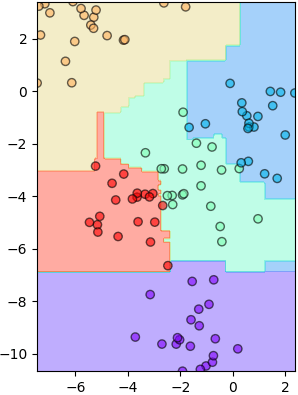
จำนวนต้นไม้ปรับได้ที่คีย์เวิร์ด n_estimators ค่าตั้งต้นคือ 10 ในที่นี้ไม่ได้ใส่จึงมี 10 ต้น
สามารถดูต้นไม้แต่ละต้นที่อยู่ด้านในป่าสุ่มได้โดยดูที่แอตทริบิวต์ .estimators_
ได้
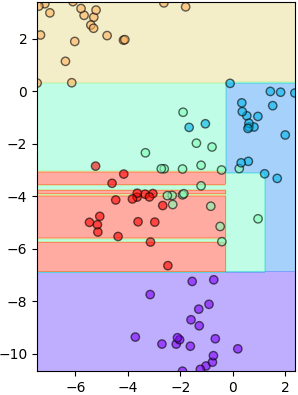
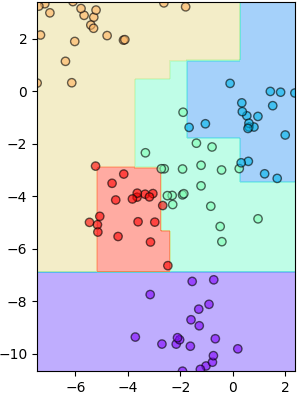
ลองเอาต้นไม้สัก ๒ ต้นจากในนั้นมาใช้ทำนายดู
ก็จะเห็นว่าแต่ละต้นมีการแบ่งเขตต่างกันออกไป แต่รวมแล้วก็จะให้ผลสรุปรวมเป็นผลของป่าสุ่ม
ป่าสุ่มมีเมธอด predict_proba ซึ่งจะคำนวณความน่าจะเป็นโดยดูจากว่ามีต้นไม้ตัดสินใจกี่ต้นในนั้นโหวตให้
ลองสร้างข้อมูลที่มี ๒ กลุ่มก้อนขึ้นมาแล้วพิจารณาความน่าจะเป็นของแต่ละกลุ่ม โดยดูที่จำนวนต้นไม้ค่าต่างๆกัน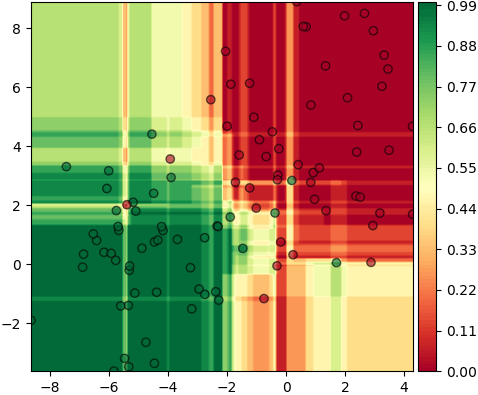
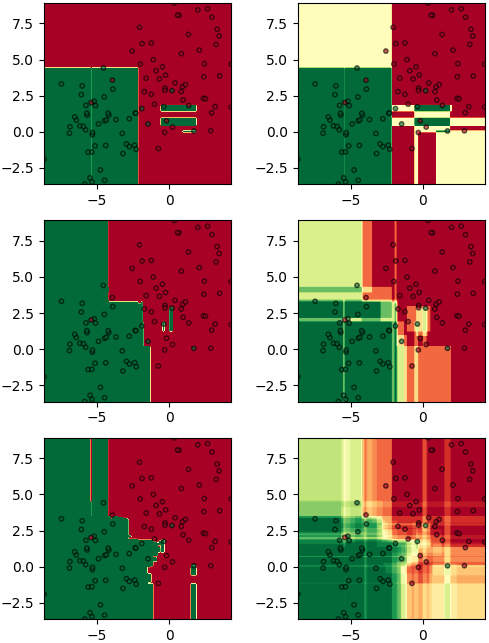
ลองเทียบผลของ predict ธรรมดากับ predict_proba ที่จำนวนต้นไม้ต่างๆกัน
จะเห็นว่าจำนวนต้นไม้ยิ่งมาก ใน predict_proba ยิ่งแบ่งละเอียด
พอใช้ sklearn แบบนี้แล้วทั้งต้นไม้ตัดสินใจและป่าสุ่มก็ใช้ได้อย่างสะดวกง่ายดายขึ้นมาก
คราวนี้จะใช้ sklearn สร้างบ้าง
ป่าสุ่มเป็นส่วนหนึ่งของวิธีการแบบอ็องซ็องบล์ (ensemble) จึงอยู่ในมอดูลย่อย sklearn.ensemble
วิธีการใช้ก็ทำนองเดียวกับต้นไม้ตัดสินใจ อาร์กิวเมนต์ต่างๆสำหรับปรุงแต่งต้นไม้ก็สามารถใส่ในป่าสุ่มได้เช่นกัน
รายละเอียดที่สามารถปรับได้มีมากมาย แต่ในที่นี้จะพูดถึงแค่ส่วนหนึ่ง รายละเอียดอื่นๆก็ดูได้ใน http://scikit-learn.org/stable/modules/generated/sklearn.ensemble.RandomForestClassifier.html
ตัวอย่างการใช้ ลองสร้างข้อมูลที่เป็นกระจุกก้อน ๕ กลุ่ม แล้วแบ่งด้วยป่าสุ่ม
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
from sklearn.ensemble import RandomForestClassifier as Rafo
np.random.seed(2)
X,z = datasets.make_blobs(n_samples=100,n_features=2,centers=5)
rafo = Rafo()
rafo.fit(X,z)
# สร้างเตรียมฟังก์ชันสำหรับวาดภาพแสดงผล
def plottassimo(X,z,mx,my,mz):
plt.figure()
plt.axes(aspect=1,xlim=[mx.min(),mx.max()],ylim=[my.min(),my.max()])
plt.scatter(X[:,0],X[:,1],alpha=0.6,c=z,edgecolor='k',cmap='rainbow')
plt.contourf(mx,my,mz,alpha=0.4,cmap='rainbow',zorder=0)
plt.show()
nmesh = 200
mx,my = np.meshgrid(np.linspace(X[:,0].min(),X[:,0].max(),nmesh),np.linspace(X[:,1].min(),X[:,1].max(),nmesh))
mX = np.stack([mx.ravel(),my.ravel()],1)
mz = rafo.predict(mX).reshape(nmesh,nmesh)
plottassimo(X,z,mx,my,mz)จำนวนต้นไม้ปรับได้ที่คีย์เวิร์ด n_estimators ค่าตั้งต้นคือ 10 ในที่นี้ไม่ได้ใส่จึงมี 10 ต้น
สามารถดูต้นไม้แต่ละต้นที่อยู่ด้านในป่าสุ่มได้โดยดูที่แอตทริบิวต์ .estimators_
print(len(rafo.estimators_))
print(rafo.estimators_[0])ได้
10
DecisionTreeClassifier(class_weight=None, criterion='gini', max_depth=None,
max_features='auto', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_impurity_split=None,
min_samples_leaf=1, min_samples_split=2,
min_weight_fraction_leaf=0.0, presort=False,
random_state=388557017, splitter='best')ลองเอาต้นไม้สัก ๒ ต้นจากในนั้นมาใช้ทำนายดู
mz = rafo.estimators_[0].predict(mX).reshape(nmesh,nmesh)
plottassimo(X,z,mx,my,mz)
mz = rafo.estimators_[7].predict(mX).reshape(nmesh,nmesh)
plottassimo(X,z,mx,my,mz)ก็จะเห็นว่าแต่ละต้นมีการแบ่งเขตต่างกันออกไป แต่รวมแล้วก็จะให้ผลสรุปรวมเป็นผลของป่าสุ่ม
ป่าสุ่มมีเมธอด predict_proba ซึ่งจะคำนวณความน่าจะเป็นโดยดูจากว่ามีต้นไม้ตัดสินใจกี่ต้นในนั้นโหวตให้
ลองสร้างข้อมูลที่มี ๒ กลุ่มก้อนขึ้นมาแล้วพิจารณาความน่าจะเป็นของแต่ละกลุ่ม โดยดูที่จำนวนต้นไม้ค่าต่างๆกัน
np.random.seed(3)
X,z = datasets.make_blobs(n_samples=100,n_features=2,centers=2,cluster_std=2.2)
rafo = Rafo(n_estimators=15)
rafo.fit(X,z)
nmesh = 200
mx,my = np.meshgrid(np.linspace(X[:,0].min(),X[:,0].max(),nmesh),np.linspace(X[:,1].min(),X[:,1].max(),nmesh))
mX = np.stack([mx.ravel(),my.ravel()],1)
mz = rafo.predict_proba(mX)[:,1].reshape(nmesh,nmesh)
plt.figure()
plt.axes(aspect=1,xlim=[mx.min(),mx.max()],ylim=[my.min(),my.max()])
plt.scatter(X[:,0],X[:,1],alpha=0.6,c=z,edgecolor='k',cmap='RdYlGn')
plt.contourf(mx,my,mz,100,alpha=1,cmap='RdYlGn',zorder=0)
plt.colorbar(pad=0.01)
plt.show()ลองเทียบผลของ predict ธรรมดากับ predict_proba ที่จำนวนต้นไม้ต่างๆกัน
n = [2,5,20]
plt.figure(figsize=[6,8])
for i in range(3):
rafo = Rafo(n_estimators=n[i])
rafo.fit(X,z)
for j in [0,1]:
if(j):
mz = rafo.predict_proba(mX)[:,1].reshape(nmesh,nmesh)
else:
mz = rafo.predict(mX).reshape(nmesh,nmesh)
plt.subplot(321+i*2+j,aspect=1,xlim=[mx.min(),mx.max()],ylim=[my.min(),my.max()])
plt.scatter(X[:,0],X[:,1],10,alpha=0.6,c=z,edgecolor='k',cmap='RdYlGn')
plt.contourf(mx,my,mz,100,alpha=1,cmap='RdYlGn',zorder=0)
plt.show()จะเห็นว่าจำนวนต้นไม้ยิ่งมาก ใน predict_proba ยิ่งแบ่งละเอียด
พอใช้ sklearn แบบนี้แล้วทั้งต้นไม้ตัดสินใจและป่าสุ่มก็ใช้ได้อย่างสะดวกง่ายดายขึ้นมาก
-----------------------------------------
囧囧囧囧囧囧囧囧囧囧囧囧囧囧囧囧囧囧囧囧囧囧囧囧囧
หมวดหมู่
-- คอมพิวเตอร์ >> ปัญญาประดิษฐ์-- คอมพิวเตอร์ >> เขียนโปรแกรม >> python >> numpy
-- คอมพิวเตอร์ >> เขียนโปรแกรม >> python >> matplotlib
-- คอมพิวเตอร์ >> เขียนโปรแกรม >> python >> sklearn