จัดการข้อมูลด้วย pandas เบื้องต้น บทที่ ๑๙: การจัดการกับตารางข้อมูลใน html และดึงข้อมูลจากเว็บไซต์
เขียนเมื่อ 2019/10/20 23:41
แก้ไขล่าสุด 2021/09/28 16:42
เว็บไซต์เป็นแหล่งที่สามารถหาข้อมูลอะไรต่างๆได้มากมายง่ายดายนัก ข้อมูลจำนวนมากจัดเรียงอยู่ในรูปแบบตาราง
ตารางที่เห็นในเว็บนั้นโดยมากแล้วจะเป็นตารางที่สร้างจากโค้ด html
การจะแปลงข้อมูลจากตาราง html มาเป็นตารางข้อมูลในโปรแกรมไพธอนนั้นมีหลายวิธี เช่นอาจใช้ beautifulsoup หรือเรกูลาร์เอ็กซ์เพรชชัน
แต่หากใช้ pandas สามารถดึงข้อมูลตารางจากเว็บไซต์ออกมาได้อย่างง่ายดายที่สุด โดยใช้ฟังก์ชัน pd.read_html เขียนโค้ดแค่บรรทัดเดียวก็เสร็จได้เลย
การดึงข้อมูลจากตาราง html ในเว็บใส่เดตาเฟรม
ขอยกตัวอย่างโดยการดึงโค้ดจากเว็บทางการของไพธอน หน้านี้ https://www.python.org/downloads/release/python-380
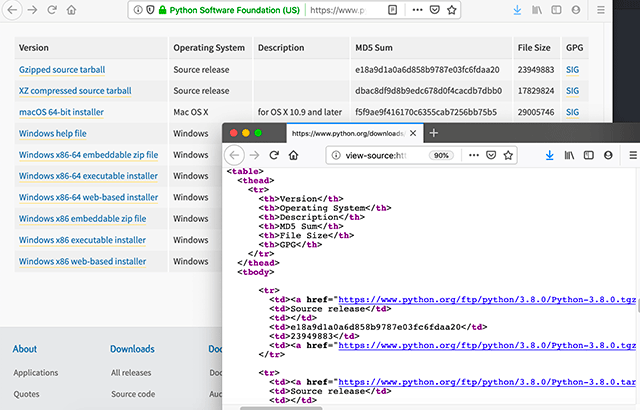
เขียนโค้ดดึงข้อมูลดูได้ดังนี้
ได้
เมื่อใช้ pd.read_html แล้วระบุเว็บไซต์ที่ต้องการดึงข้อมูลไป มันจะไปค้นข้อมูลภายในเว็บนั้นแล้วหาดูว่ามีตารางข้อมูลอะไรอยู่หรือเปล่า แล้วแปลงตารางนั้นเป็นเดตาเฟรมของ pandas ให้เลย ตารางทั้งหมดจะถูกเก็บอยู่ในลิสต์ตามลำดับ นำมาใช้ได้ทันที
วิธีนี้จึงสะดวกมากเวลาจะดึงข้อมูลที่เป็นตารางจากเว็บ
นอกจากดึงข้อมูลจากเว็บแล้ว อาจดึงจากไฟล์ html ที่อยู่ในเครื่องก็ได้ เช่น
หรือจะป้อนโค้ด html ที่อยู่ในรูปแบบสายอักขระก็ได้ เช่น ถ้าไปดึงโค้ดมาจากเว็บด้วยวิธีอื่น เช่นใช้ requests.get แล้วเอาโค้ด html ที่ได้จากเว็บไซต์นั้นมาใส่ใน pd.read_html
แต่ถ้าไม่ได้ต้องการจะเอาข้อมูลส่วนอื่นของเว็บอยู่แล้ว ก็ใส่แค่ url เว็บไปโดยตรงเลยเว็บก็จะไปค้นหาตารางมาเองจากโค้ด html ภายในเว็บนั้น แบบนี้จะเขียนสั้นกว่ามาก
ค่าที่ถือว่าเป็น NaN
ปกติถ้าหากค่าในตารางเป็นช่องว่างเปล่าหรือเขียนไว้ว่า nan ก็จะถูกตีความเป็น NaN
แต่ถ้าต้องการเพิ่มตัวที่จะถูกตีความว่าเป็นช่อง NaN ก็อาจใส่ na_values เพิ่มเข้าไป เช่น
ได้
ในขณะเดียวกัน หากไม่ต้องการให้ช่องว่างเปล่าหรือคำว่า nan ถูกตีความเป็น NaN ก็ให้ใส่ keep_default_na=False
ได้
ชื่อคอลัมน์
ในตัวอย่างที่ยกมาข้างต้นนั้นจะเห็นว่าแถวแรกใช้แท็ก <th> ซึ่งปกติแล้วจะเอาไว้ใช้แทนหัวข้ออยู่แล้ว ดังนั้นแถวนั้นจึงกลายมาเป็นชื่อคอลัมน์ไปโดยอัตโนมัติ
แต่ว่าสำหรับตารางที่ไม่ได้ใช้แท็ก <th> จะถูกอ่านโดยที่ไม่มีชื่อคอลัมน์ ผลที่ได้ก็จะได้คอลัมน์เป็นแค่ตัวเลข
ตัวอย่าง
ได้
กรณีแบบนี้อาจต้องใส่ header=0 ไป เพื่อบอกให้รู้ว่าจะใช้แถวแรกเป็นชื่อคอลัมน์
ได้
เพียงแต่ว่าในกรณีกลับกัน หากแถวแรกเป็น <th> ต่อให้ใส่ header=None ไปแถวแรกก็ยังคงจะถูกใช้เป็นชื่อคอลัมน์อยู่ดี
การตั้งคอลัมน์เป็นดัชนี
สำหรับกรณีดัชนี (ชื่อแถว) นั้นจะต่างจากกรณีชื่อคอลัมน์ตรงที่ว่าต่อให้ใช้แท็ก <th> อยู่ก็จะไม่มีการอ่านมาเป็นดัชนี
หากต้องการกำหนดแถวที่เป็นดัชนีให้ใส่ index_col
ตัวอย่าง
ได้
การแปลงจากเดตาเฟรมไปเป็น html
ในทางกลับกันหากมีเดตาเฟรมแล้วจะแปลงไปเป็นตารางใน html เพื่อเอาไปเขียนลงในเว็บ ก็สามารถใช้เมธอด .to_html ที่ตัวเดตาเฟรมได้
ตัวอย่าง
ถ้าไม่ได้ใส่ชื่อไฟล์ลงไปก็จะเป็นแค่การแปลงออกมาเป็นสายอักขระของโค้ด html แต่หากต้องการสร้างไฟล์ html ก็สามารถใส่ชื่อไฟล์เพื่อให้เขียนลงไปในไฟล์ได้เลย เช่น
ลองเปิดไฟล์ขึ้นมาดู

ปกติจะมีการใส่กรอบมาให้แบบนี้ แต่ถ้าถ้าไม่ต้องการก็ใส่ border=0 หรือถ้าต้องการให้กรอบหนาขึ้นก็ใส่ตัวเลขเยอะๆได้

สามารถกำหนดขนาดความกว้างของตารางแต่ละช่องโดยใส่ค่า col_space หน่วยเป็นพิกเซล

หากไม่ต้องการดัชนีและชื่อคอลัมน์ก็อาจกำหนด index=False และ header=False
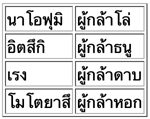
บางทีถ้าตารางยาวไป สามารถใช้ max_rows หรือ max_cols เพื่อกำหนดว่าถ้ามีเกินกี่ตัวจะถูกละ กลายเป็น ...
เช่น
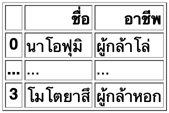
ปกติดัชนีจะเป็นตัวหนา แต่ถ้าไม่อยากให้หนาก็กำหนด bold_rows=False ได้
เช่น

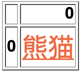
ปกติข้อมูลข้างในถ้ามีโค้ด html ปนอยู่จะถูก escape โดยอัตโนมัติ ทำให้โค้ด html แสดงผลทั้งอย่างนั้น แต่หากต้องการใช้ html มีผลทั้งอย่างนันก็ใช้ escape=False ได้
เช่น
ข้อมูลที่มีจำนวนเลขทศนิยมอาจกำหนดรูปแบบจุดทศนิยมโดย float_format
เช่นต้องการให้แสดงเลขทศนิยม ๓ ตัว
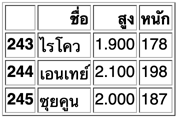
ในที่นี้ "ส่วนสูง" กลายเป็นเลขทศนิยม ๓ ตำแหน่งตามที่กำหนด ส่วน "น้ำหนัก" เป็นจำนวนเต็มดังนั้น float_format จึงไม่มีผล
นอกจากนี้ทั้ง to_html และ read_html ยังมีตัวเลือกเสริมอีกมากมายที่ยังไม่อาจกล่าวถึงได้หมด ที่เหลืออาจลองดูได้ในเว็บหลัก
https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.to_html.html
https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.read_html.html
อ้างอิง
ตารางที่เห็นในเว็บนั้นโดยมากแล้วจะเป็นตารางที่สร้างจากโค้ด html
การจะแปลงข้อมูลจากตาราง html มาเป็นตารางข้อมูลในโปรแกรมไพธอนนั้นมีหลายวิธี เช่นอาจใช้ beautifulsoup หรือเรกูลาร์เอ็กซ์เพรชชัน
แต่หากใช้ pandas สามารถดึงข้อมูลตารางจากเว็บไซต์ออกมาได้อย่างง่ายดายที่สุด โดยใช้ฟังก์ชัน pd.read_html เขียนโค้ดแค่บรรทัดเดียวก็เสร็จได้เลย
การดึงข้อมูลจากตาราง html ในเว็บใส่เดตาเฟรม
ขอยกตัวอย่างโดยการดึงโค้ดจากเว็บทางการของไพธอน หน้านี้ https://www.python.org/downloads/release/python-380
เขียนโค้ดดึงข้อมูลดูได้ดังนี้
import pandas as pd
py380 = pd.read_html('https://www.python.org/downloads/release/python-380/')
print('มีตาราง %d อัน'%len(py380))
print(py380[0])ได้
มีตาราง 1 อัน
Version Operating System ... File Size GPG
0 Gzipped source tarball Source release ... 23949883 SIG
1 XZ compressed source tarball Source release ... 17829824 SIG
2 macOS 64-bit installer Mac OS X ... 29005746 SIG
3 Windows help file Windows ... 8457529 SIG
4 Windows x86-64 embeddable zip file Windows ... 8084795 SIG
5 Windows x86-64 executable installer Windows ... 27505064 SIG
6 Windows x86-64 web-based installer Windows ... 1363336 SIG
7 Windows x86 embeddable zip file Windows ... 7213298 SIG
8 Windows x86 executable installer Windows ... 26406312 SIG
9 Windows x86 web-based installer Windows ... 1325368 SIG
[10 rows x 6 columns]เมื่อใช้ pd.read_html แล้วระบุเว็บไซต์ที่ต้องการดึงข้อมูลไป มันจะไปค้นข้อมูลภายในเว็บนั้นแล้วหาดูว่ามีตารางข้อมูลอะไรอยู่หรือเปล่า แล้วแปลงตารางนั้นเป็นเดตาเฟรมของ pandas ให้เลย ตารางทั้งหมดจะถูกเก็บอยู่ในลิสต์ตามลำดับ นำมาใช้ได้ทันที
วิธีนี้จึงสะดวกมากเวลาจะดึงข้อมูลที่เป็นตารางจากเว็บ
นอกจากดึงข้อมูลจากเว็บแล้ว อาจดึงจากไฟล์ html ที่อยู่ในเครื่องก็ได้ เช่น
pandanarak = pd.read_html('pandanarak.html')หรือจะป้อนโค้ด html ที่อยู่ในรูปแบบสายอักขระก็ได้ เช่น ถ้าไปดึงโค้ดมาจากเว็บด้วยวิธีอื่น เช่นใช้ requests.get แล้วเอาโค้ด html ที่ได้จากเว็บไซต์นั้นมาใส่ใน pd.read_html
import requests
r = requests.get('https://www.python.org/downloads/release/python-380/')
pd.read_html(r.text)แต่ถ้าไม่ได้ต้องการจะเอาข้อมูลส่วนอื่นของเว็บอยู่แล้ว ก็ใส่แค่ url เว็บไปโดยตรงเลยเว็บก็จะไปค้นหาตารางมาเองจากโค้ด html ภายในเว็บนั้น แบบนี้จะเขียนสั้นกว่ามาก
ค่าที่ถือว่าเป็น NaN
ปกติถ้าหากค่าในตารางเป็นช่องว่างเปล่าหรือเขียนไว้ว่า nan ก็จะถูกตีความเป็น NaN
แต่ถ้าต้องการเพิ่มตัวที่จะถูกตีความว่าเป็นช่อง NaN ก็อาจใส่ na_values เพิ่มเข้าไป เช่น
html = '''
<table>
<tr><td>1</td><td></td></tr>
<tr><td>nan</td><td>nil</td></tr>
</table>
'''
df = pd.read_html(html,na_values=['nil'])[0]
print(df)ได้
0 1
0 1.0 NaN
1 NaN NaNในขณะเดียวกัน หากไม่ต้องการให้ช่องว่างเปล่าหรือคำว่า nan ถูกตีความเป็น NaN ก็ให้ใส่ keep_default_na=False
df = pd.read_html(html,keep_default_na=0)[0]
print(df)ได้
0 1
0 1
1 nan nilชื่อคอลัมน์
ในตัวอย่างที่ยกมาข้างต้นนั้นจะเห็นว่าแถวแรกใช้แท็ก <th> ซึ่งปกติแล้วจะเอาไว้ใช้แทนหัวข้ออยู่แล้ว ดังนั้นแถวนั้นจึงกลายมาเป็นชื่อคอลัมน์ไปโดยอัตโนมัติ
แต่ว่าสำหรับตารางที่ไม่ได้ใช้แท็ก <th> จะถูกอ่านโดยที่ไม่มีชื่อคอลัมน์ ผลที่ได้ก็จะได้คอลัมน์เป็นแค่ตัวเลข
ตัวอย่าง
html = '''
<table>
<tr><td><b>ชื่อ</b></td><td><b>อายุ</b></td></tr>
<tr><td>ฮาจิเมะ</td><td>17</td></tr>
<tr><td>เยวี่ย</td><td>323</td></tr>
<tr><td>ไอโกะ</td><td>25</td></tr>
<tr><td>มิว</td><td>4</td></tr>
</table>
'''
tarang = pd.read_html(html)[0]
print(tarang)ได้
0 1
0 ชื่อ อายุ
1 ฮาจิเมะ 17
2 เยวี่ย 323
3 ไอโกะ 25
4 มิว 4กรณีแบบนี้อาจต้องใส่ header=0 ไป เพื่อบอกให้รู้ว่าจะใช้แถวแรกเป็นชื่อคอลัมน์
tarang = pd.read_html(html,header=0)[0]
print(tarang)ได้
ชื่อ อายุ
0 ฮาจิเมะ 17
1 เยวี่ย 323
2 ไอโกะ 25
3 มิว 4เพียงแต่ว่าในกรณีกลับกัน หากแถวแรกเป็น <th> ต่อให้ใส่ header=None ไปแถวแรกก็ยังคงจะถูกใช้เป็นชื่อคอลัมน์อยู่ดี
การตั้งคอลัมน์เป็นดัชนี
สำหรับกรณีดัชนี (ชื่อแถว) นั้นจะต่างจากกรณีชื่อคอลัมน์ตรงที่ว่าต่อให้ใช้แท็ก <th> อยู่ก็จะไม่มีการอ่านมาเป็นดัชนี
หากต้องการกำหนดแถวที่เป็นดัชนีให้ใส่ index_col
ตัวอย่าง
html = '''
<table>
<tr><th>ชื่อ</th><th>อาชีพ</th></tr>
<tr><th>โควกิ</th><td>ผู้กล้า</td></tr>
<tr><th>ชิซึกุ</th><td>นักดาบ</td></tr>
<tr><th>ฮาจิเมะ</th><td>นักแปรธาตุ</td></tr>
</table>
'''
tarang = pd.read_html(html,index_col=0)[0]
print(tarang)ได้
อาชีพ
ชื่อ
โควกิ ผู้กล้า
ชิซึกุ นักดาบ
ฮาจิเมะ นักแปรธาตุการแปลงจากเดตาเฟรมไปเป็น html
ในทางกลับกันหากมีเดตาเฟรมแล้วจะแปลงไปเป็นตารางใน html เพื่อเอาไปเขียนลงในเว็บ ก็สามารถใช้เมธอด .to_html ที่ตัวเดตาเฟรมได้
ตัวอย่าง
phukla = pd.DataFrame([
['นาโอฟุมิ','ผู้กล้าโล่'],
['อิตสึกิ','ผู้กล้าธนู'],
['เรง','ผู้กล้าดาบ'],
['โมโตยาสึ','ผู้กล้าหอก']],
columns=['ชื่อ','อาชีพ'])
print(phukla.to_html())<table border="1" class="dataframe">
<thead>
<tr style="text-align: right;">
<th></th>
<th>ชื่อ</th>
<th>อาชีพ</th>
</tr>
</thead>
<tbody>
<tr>
<th>0</th>
<td>นาโอฟุมิ</td>
<td>ผู้กล้าโล่</td>
</tr>
<tr>
<th>1</th>
<td>อิตสึกิ</td>
<td>ผู้กล้าธนู</td>
</tr>
<tr>
<th>2</th>
<td>เรง</td>
<td>ผู้กล้าดาบ</td>
</tr>
<tr>
<th>3</th>
<td>โมโตยาสึ</td>
<td>ผู้กล้าหอก</td>
</tr>
</tbody>
</table>ถ้าไม่ได้ใส่ชื่อไฟล์ลงไปก็จะเป็นแค่การแปลงออกมาเป็นสายอักขระของโค้ด html แต่หากต้องการสร้างไฟล์ html ก็สามารถใส่ชื่อไฟล์เพื่อให้เขียนลงไปในไฟล์ได้เลย เช่น
phukla.to_html('phukla.html')ลองเปิดไฟล์ขึ้นมาดู
ปกติจะมีการใส่กรอบมาให้แบบนี้ แต่ถ้าถ้าไม่ต้องการก็ใส่ border=0 หรือถ้าต้องการให้กรอบหนาขึ้นก็ใส่ตัวเลขเยอะๆได้
phukla.to_html('phukla.html',border=0)สามารถกำหนดขนาดความกว้างของตารางแต่ละช่องโดยใส่ค่า col_space หน่วยเป็นพิกเซล
phukla.to_html('phukla.html',col_space=150)หากไม่ต้องการดัชนีและชื่อคอลัมน์ก็อาจกำหนด index=False และ header=False
phukla.to_html('phukla.html',index=0,header=0)บางทีถ้าตารางยาวไป สามารถใช้ max_rows หรือ max_cols เพื่อกำหนดว่าถ้ามีเกินกี่ตัวจะถูกละ กลายเป็น ...
เช่น
phukla.to_html('phukla.html',max_rows=3)ปกติดัชนีจะเป็นตัวหนา แต่ถ้าไม่อยากให้หนาก็กำหนด bold_rows=False ได้
เช่น
phukla.to_html('phukla.html',bold_rows=0)ปกติข้อมูลข้างในถ้ามีโค้ด html ปนอยู่จะถูก escape โดยอัตโนมัติ ทำให้โค้ด html แสดงผลทั้งอย่างนั้น แต่หากต้องการใช้ html มีผลทั้งอย่างนันก็ใช้ escape=False ได้
เช่น
df = pd.DataFrame([['<u style="color: #de7654; font-size: 26px">熊猫</u>']])
df.to_html('df.html',escape=0)ข้อมูลที่มีจำนวนเลขทศนิยมอาจกำหนดรูปแบบจุดทศนิยมโดย float_format
เช่นต้องการให้แสดงเลขทศนิยม ๓ ตัว
pokemon = pd.DataFrame([
['ไรโคว',1.9,178],
['เอนเทย์',2.1,198],
['ซุยคูน',2,187]],
columns=['ชื่อ','สูง','หนัก'],
index=[243,244,245])
pokemon.to_html('pokemon.html',float_format='%.3f')ในที่นี้ "ส่วนสูง" กลายเป็นเลขทศนิยม ๓ ตำแหน่งตามที่กำหนด ส่วน "น้ำหนัก" เป็นจำนวนเต็มดังนั้น float_format จึงไม่มีผล
นอกจากนี้ทั้ง to_html และ read_html ยังมีตัวเลือกเสริมอีกมากมายที่ยังไม่อาจกล่าวถึงได้หมด ที่เหลืออาจลองดูได้ในเว็บหลัก
https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.to_html.html
https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.read_html.html
อ้างอิง