responder เฟรมเวิร์กเล็กๆใช้งานง่ายสำหรับสร้างเว็บไซต์โดย python
เขียนเมื่อ 2020/05/17 00:45
แก้ไขล่าสุด 2024/09/21 13:32

responder เป็นมอดูลเขียนเฟรมเวิร์กสร้างเว็บโดยไพธอนที่ได้รับความนิยมมากตัวหนึ่ง ถูกสร้างขึ้นในเดือนตุลาคมปี 2018 ถือว่าค่อนข้างใหม่หากเทียบกับเฟรมเวิร์กที่ได้รับความนิยมมาก่อนเช่น django หรือ flask แต่ได้รับความนิยมขึ้นมาอย่างรวดเร็ว
>> เว็บไซต์หลักของ responder
ไพธอนเองก็มีมอดูลเฟรมเวิร์กเขียนเว็บอยู่หลายตัวมาก เมื่อเทียบแล้ว responder จะคล้ายกับเฟรมเวิร์กแบบง่ายๆอย่างเช่น flask หรือ bottle มากกว่าเฟรมเวิร์กที่มีขนาดใหญ่จัดเตรียมอะไรเสร็จสรรพเรียบร้อยอย่าง django
บางทีก็เรียกเฟรมเวิร์กเล็กๆแบบนี้ว่าเป็น ไมโครเฟรมเวิร์ก (microframework)
คือสามารถเขียนโค้ดสั้นๆแล้วทำเว็บแบบง่ายๆออกมาได้ ไม่ต้องเรียนรู้ขั้นตอนอะไรซับซ้อนมากมาย เหมาะสำหรับทำเว็บไซต์เล็กๆ มีอิสระในการเขียนมากกว่า
เมื่อเทียบกับ flask แล้วถือว่ามีความคล้ายคลึงกัน แต่โดยรวมมีโครงสร้างเรียบง่ายกว่า เช่น สั่ง import responder ตัวเดียวก็ใช้ได้เลย ไม่ต้อง import แยกส่วนอย่าง flask
นอกจากนี้ก็เช่นกำหนดรูตในรูปแบบคล้าย f-string ของไพธอน ซึ่งสำหรับคนที่ใช้ f-string ไพธอนอยู่แล้วอาจดูแล้วคุ้นเคยเข้าใจง่ายกว่า
เกี่ยวกับ f-string เคยเขียนแนะนำไว้ อ่านได้ใน >> https://phyblas.hinaboshi.com/20190714
เบื้องหลัง responder มีการใช้มอดูล starlette ซึ่งทำการสร้างเซิร์ฟเวอร์ที่ภายในมีการทำงานแบบไม่ประสานเวลา (asynchronous) ทั้งหมด
ในบทความนี้จะอธิบายและยกตัวอย่างการใช้เบื้องต้น รายละเอียดเพิ่มเติมอาจอ่านได้ในเว็บหลักของ responder
การติดตั้ง
การเช่นเดียวกับมอดูลอื่นๆ การติดตั้ง responder ทำได้ง่ายโดยใช้ pip
pip install responder
เพียงแต่ว่าผู้สร้าง responder คือ Kenneth Reitz ซึ่งเป็นคนที่สร้าง pipenv ซึ่งเป็นมอดูลหนึ่งที่เอาไว้จัดการสภาพแวดล้อมของไพธอนซึ่งนิยมใช้กันมาก ดังนั้นในเว็บหลักของ responder เขาจะแนะนำให้ติดตั้งด้วย pipenv
pipenv install responder --pre
แต่จริงๆจะใช้ pip ธรรมดาก็ได้เช่นกัน
responder ใช้ได้ในไพธอน 3.6 ขึ้นไปเท่านั้น ไม่ได้สร้างมาให้รองรับเวอร์ชันเก่ากว่านั้น
เริ่มต้น
ขอเริ่มโดยยกตัวอย่างโค้ดการเขียนเว็บอย่างสั้นๆ
เมื่อใช้ responder สามารถสร้างเว็บง่ายๆขึ้นได้โดยอาจเขียนสั้นๆได้แบบนี้
import responder
# ฟังก์ชันสำหรับเตรียมเนื้อหาให้หน้าเว็บ
def sawatdi(req,resp):
resp.html = '<meta charset="UTF-8"> <h1> สวัสดี ^^ </h1>๛' + req.full_url
api = responder.API() # สร้างออบเจ็กต์ api
api.add_route('/',sawatdi) # กำหนดรูต
api.run() # รันเซิร์ฟเวอร์จากนั้นสั่งรันแล้วจะได้ข้อความประมาณนี้ขึ้นมา แสดงให้เห็นว่าเว็บได้ถูกเปิดขึ้นแล้ว อยู่ที่ url ตามที่ขึ้นมาให้เห็นในนี้
INFO: Started server process [1501]
INFO: Uvicorn running on http://127.0.0.1:5042 (Press CTRL+C to quit)
INFO: Waiting for application startup.
INFO: Application startup complete.โดยค่าตั้งต้นแล้ว url ของเว็บที่สร้างขึ้นจะอยู่ที่ http://127.0.0.1:5042/ ลองเปิดหน้าเว็บนี้ขึ้นมาด้วยเบราว์เซอร์ก็จะขึ้นหน้าเว็บแบบนี้มา
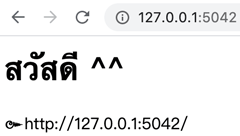
คอมมานด์ไลน์ตัวที่ใช้รันโปรแกรมตัวนี้ก็จะค้างอยู่แบบนั้นแล้วมีขึ้นข้อความแสดงสถานะของเว็บ เช่นเมื่อเราเข้าเว็บก็จะขึ้นข้อความแบบนี้
INFO: 127.0.0.1:52792 - "GET / HTTP/1.1" 200 OKหากต้องการปิดให้กด ctrl+c เว็บก็จะถูกปิด และเข้าไม่ได้อีก
INFO: Shutting down
INFO: Waiting for application shutdown.
INFO: Application shutdown complete.
INFO: Finished server process [1501]อนึ่ง หากใครรันภายใน spyder อาจจะเกิดข้อผิดพลาดขึ้น เพราะการทำงานของ responder จะใช้อีเวนต์ลูปซึ่งทำงานแบบไม่ประสานเวลา หากต้องการใช้ใน spyder อาจใช้มอดูล nest-asyncio ช่วย ดังที่เขียนใน >> https://phyblas.hinaboshi.com/20200311
โดยรวมแล้วในเบื้องต้นการสร้างเว็บง่ายๆนี้อาจสรุปได้เป็นขั้นตอนดังนี้
import responder- สร้างออบเจ็กต์
responder.API()นี่เป็นจุดเริ่มต้นของทั้งหมด ออบเจ็กต์ตัวนี้จะเป็นตัวเรียกเมธอดสั่งทำคำสั่งอะไรต่างๆในเว็บนี้
ในวงเล็บ () อาจใส่ตัวเลือกเสริมต่างๆเพื่อเปลี่ยนรูปแบบของเว็บที่จะทำไปตามที่ต้องการ ในที่นี้ไม่ได้กำหนดอะไรก็จะเป็นไปตามค่าตั้งต้น - กำหนดรูตของหน้าต่างๆในเว็บ โดยใส่ฟังก์ชันที่จะเป็นตัวจัดการต่างๆในหน้าเว็บนั้น
ฟังก์ชันนั้นต้องประกอบไปด้วยพารามิเตอร์ ๒ ตัว ซึ่งจะมาเป็นออบเจ็กต์ตัวคำร้องขอ (request) และออบเจ็กต์ตัวตอบสนอง
(response) ในที่นี้ใช้ชื่อเป็น req และ resp
เป็นออบเจ็กต์สำคัญที่มีแอตทริบิวต์หรือเมธอดต่างๆซึ่งกำหนดพฤติกรรมของเว็บไซต์
ในที่นี้ได้ใส่รูตไปตัวเดียวคือ "/" ซึ่งจะหมายถึงหน้าหลักของเว็บ สำหรับตรงนี้ก็คือ http://127.0.0.1:5042/ กำหนดโดยฟังก์ชัน sawatdi
ถ้าใส่เป็นapi.add_route('/haha',huaro)ก็จะเป็นการกำหนดรูตให้ที่ http://127.0.0.1:5042/haha เป็นฟังก์ชัน huaro เป็นต้น
- รันเซิร์ฟเวอร์โดยใช้เมธอด .run() ในวงเล็บสามารถกำหนดหมายเลขพอร์ตได้โดยใส่ตัวเลือกเสริม port เช่นถ้าใส่
api.run(port=8080) ก็จะได้ url เป็น http://127.0.0.1/8080/
ในที่นี้ไม่ได้ใส่ก็จะได้พอร์ตเป็น 5042 ตามค่าตั้งต้น - เท่านี้เสร็จแล้วก็รันโค้ด รอขึ้นข้อความแสดงว่าเซิร์ฟเวอร์ถูกเปิดเรียบร้อยแล้วก็ไปเปิดหน้าเว็บขึ้นมาดูได้ และเมื่อต้องการปิดก็กด ctrl+c ในหน้าคอมมานด์ไลน์ที่เราสั่งรันโค้ดไป
ออบเจ็กต์ตัวคำร้อง (req) เป็นตัวที่เก็บข้อมูลการเชื่อมต่อเข้าเว็บมา เช่น url, เฮดเดอร์, พารามิเตอร์, เมธอดที่เชื่อมต่อ (get, post, ...), ฯลฯ ซึ่งส่งมาจากไคลเอนต์
ส่วนออบเจ็กต์ตัวตอบสนอง resp เป็นตัวกำหนดว่าจะให้หน้าเว็บมีลักษณะเป็นอย่างไร เช่นเนื้อหาตัวเว็บหรือเฮดเดอร์ เป็นต้น
ในตัวอย่างนี้เนื้อหาในตัวหน้าเว็บกำหนดโดยใส่ลงไปที่แอตทริบิวต์ .html ของออบเจ็กต์ตัวตอบสนอง (resp) ในที่นี้ใส่โค้ด html ง่ายๆสั้นๆสำหรับแสดงข้อความ "สวัสดี" แล้วก็ให้แสดง url ที่ใส่เข้าไปด้วย โดยเอาค่า url จากเก็บอยู่ที่แอตทริบิวต์ .full_url ในออบเจ็กต์ตัวคำร้องขอ (req)
ออบเจ็กต์ resp นอกเหนือจาก resp.html ซึ่งใช้กำหนดเนื้อหาตัวเว็บแล้ว ยังสามารถกำหนดอะไรอื่นๆเช่น resp.headers ใช้กำหนดเฮดเดอร์
ตัวอย่างการใช้ resp.header เช่น
import responder
def sawatdi(req,resp):
resp.headers = {"Content-Type": "text/html; charset=utf-8"}
resp.html = '<h1> สวัสดี ^^ </h1>๛' + req.full_url
api = responder.API()
api.add_route('/',sawatdi)
api.run()แบบนี้จะได้ผลเหมือนกับในตัวอย่างที่แล้ว แต่ในที่นี้ใช้กำหนด Content-Type ในเฮดเดอร์เพื่อบอกให้รู้ว่าให้อ่านเป็นยูนิโค้ด utf-8 แทนที่จะใส่
<meta charset="UTF-8"> ลงในโค้ด html โดยตรงการเขียนในรูปแบบเดคอเรเตอร์
ในตัวอย่างข้างต้นนั้นใช้ใส่รูตโดยใช้เมธอด .add_route() แต่หากเข้าไปดูวิธีการที่แนะนำในเว็บหลักของ responder เองจะเห็นว่าเขาแนะนำการเขียนด้วยวิธีการใช้เดคอเรเตอร์เพื่อให้การเขียนดูง่ายขึ้น
เกี่ยวกับเดคอเรเตอร์ได้เขียนไว้ใน ไพธอนเบื้องต้นบทที่ ๓๐
โดยการใช้เดคอเรเตอร์ช่วย อาจเขียนใหม่ได้ดังนี้
import responder
api = responder.API() # สร้างออบเจ็กต์ api
# กำหนดรูต
@api.route('/')
def sawatdi(req,resp):
resp.html = '<meta charset="UTF-8"> <h1> สวัสดี ^^ </h1>๛' + req.full_url
api.run() # รันเซิร์ฟเวอร์ซึ่งเทียบเท่ากับการเขียนแบบนี้
import responder
def sawatdi(req,resp):
resp.html = '<meta charset="UTF-8"> <h1> สวัสดี ^^ </h1>๛' + req.full_url
api = responder.API()
api.route('/')(sawatdi)
api.run().route() ก็เป็นเมธอดของ api ที่เอาไว้กำหนดรูตเหมือนกับ .add_route() แต่วิธีเขียนต่างกันเล็กน้อย และปกติจะใช้ในรูปเดคอเรเตอร์แบบในตัวอย่างด้านบน
วิธีการเขียนแบบนี้จะดูคล้ายกับเฟรมเวิร์กตัวอื่นที่มีมาก่อนอย่าง flask ถ้าใครเคยใช้มาก่อนก็อาจจะคุ้นเคยกับการเขียนแบบนี้
จะเขียนแบบไหนก็แล้วแต่ความสะดวก สำหรับในบทความนี้เพื่อความเข้าใจง่าย ในตัวอย่างต่อๆไปจะใช้ .add_route() เป็นหลัก แต่หากเข้าใจแล้วจะเปลี่ยนมาใช้เดคอเรเตอร์แบบนี้ก็ได้เช่นกัน
ตัวแปรที่เปลี่ยนค่าตาม url
ในส่วนของการตั้งรูต สามารถกำหนดให้ส่วนหนึ่งของ url กลายมาเป็นค่าของตัวแปร ซึ่งอาจทำให้เว็บแสดงผลต่างกันไปตามค่านั้นได้
วิธีการเขียนจะคล้ายกับการเขียน f-string ในไพธอน คือใช้วงเล็บปีกกา { } ส่วนที่อยู่ในนี้จะกลายเป็นชื่อตัวแปร ซึ่งเราต้องเตรียมพารามิเตอร์ชื่อเดียวกันนี้ไว้ในฟังก์ชันด้วย
โดยต้องให้ใส่พารามิเตอร์ตัวที่ ๓ เป็น * แล้วตัวที่ ๔ เป็นต้นไปเป็นตัวแปรที่ตรงกับในวงเล็บ { }
ตัวอย่าง
import responder
def pika(req,resp,*,n):
resp.html = '<meta charset="UTF-8">'
try:
resp.html += '★'*int(n)
except:
resp.html += 'มีบางอย่างผิดพลาด'
api = responder.API()
api.add_route('/pika/{n}',pika)
api.run()ในที่นี้ {n} จะแทนอะไรก็ได้ที่ใส่ลงไปถัดจาก pika/
ลองเปิดหน้า http://127.0.0.1:5042/pika/5 จะได้แบบนี้
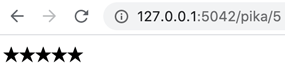
หากเปิดหน้า http://127.0.0.1:5042/pika/16 ก็จะเป็นแบบนี้

และพอเปิดหน้า http://127.0.0.1:5042/pika/xx ก็จะได้ว่า
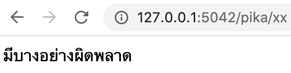
แม้การเขียนจะใช้วงเล็บปีกกาเหมือน f-string แต่ว่าไม่ได้ให้เขียนเป็น f-string จริงๆ ดังนั้นไม่ต้องเติม f ข้างหน้า (เช่น
'{x}' ไม่ใช่ f'{x}')ถ้ามีตัวแปรหลายตัวก็ใส่พารามิเตอร์ไปตามนั้นให้ครบ พารามิเตอร์จะแทนตัวที่ชื่อเหมือนกันดังนั้นจะใส่ลำดับสลับกันก็ได้ เช่น
import responder
def wdp(req,resp,*,wan,duean,pi):
resp.html = '<meta charset="UTF-8">'
resp.html += f'วันนี้วันที่ {wan} เดือน {duean} ปี {pi}'
api = responder.API()
api.add_route('/wdp/{pi}-{duean}-{wan}',wdp)
api.run()เปิดหน้า http://127.0.0.1:5042/wdp/2020-5-17
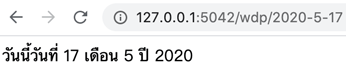
ใส่เนื้อหาข้อความธรรมดาด้วย resp.text
ในตัวอย่างข้างต้นใช้แอตทริบิวต์ resp.html จะเป็นการสร้างหน้าเว็บทั่วไปซึ่งเขียนเป็นโค้ด html
แต่นอกจากนั้นยังมี resp.text สำหรับแสดงเป็นข้อความธรรมดา, resp.content สำหรับลงข้อมูลไบนารี และ resp.media สำหรับลงข้อมูล json หรือ yaml
ตัวอย่างการใช้ resp.text ผลจะต่างจาก resp.html ตรงที่ได้เป็นข้อความธรรมดา เขียนอะไรลงไปก็ขึ้นตามนั้น ไม่ได้ถูกอ่านเป็นโค้ด html
import responder
def sawatdi(req, resp):
resp.text = '''
<meta charset="UTF-8">
xin chào
sawạtđi'''
api = responder.API()
api.add_route('/sawatdi',sawatdi)
api.run()เปิดหน้า http://127.0.0.1:5042/sawatdi ผลที่ได้จะเป็นแบบนี้
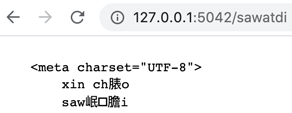
ผลที่ได้ตรงนี้อักษร à ạ đ แสดงผลได้ไม่ถูกต้องเนื่องจากไม่ได้เป็นอักษร ASCII การอ่านจะผิดพลาดถ้าไม่ระบุให้เบราว์เซอร์รู้ว่าให้อ่านเป็น utf-8 ก็จะถูกอ่านแบบอื่นตีความให้ผลเพี้ยนไป
ซึ่งโค้ดตรงส่วน
<meta charset="UTF-8"> นี้มีเพื่อให้เบราว์เซอร์อ่านเป็น UTF-8 เสมอ แต่เนื่องจากใช้
resp.text อักษรจึงแสดงทั้งๆอย่างนั้น ไม่ได้ถูกอ่านเป็นโค้ด html จึงไม่ได้ถูกตีความกรณีแบบนี้ถ้าต้องการให้แสดงภาษาไทยถูกต้องอาจระบุ charset ลงใน Content-Type ของเฮดเดอร์โดยใส่ resp.headers แทน เช่น
import responder
def sawatdi(req, resp):
resp.headers = {"Content-Type": "text/plain; charset=utf-8"}
resp.text = 'สวัสดี'*5
api = responder.API()
api.add_route('/sawatdi',sawatdi)
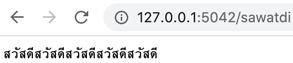
api.run()แบบนี้ก็จะแสดงภาษาไทยหรืออักษรต่างๆที่เป็นยูนิโค้ดได้อย่างถูกต้อง
ลงเนื้อหาเป็น json โดย resp.media
resp.media เป็นการให้ข้อมูลในรูปแบบ json ซึ่งเป็นรูปแบบการเก็บข้อมูลโครงสร้างที่นิยมใช้ในการส่งข้อมูลตามเว็บ
วิธีการใช้ให้ใส่ข้อมูลดิกชันนารีลงใน resp.media แล้วจะถูกเปลี่ยนเป็น json โดยอัตโนมัติ
ตัวอย่าง
def jsonmedia(req, resp):
resp.media = {}
resp.media['b'] = 2
resp.media['c'] = 3.
resp.media['d'] = "IV"
resp.media['e'] = "๕"
api = responder.API()
api.add_route('/json',jsonmedia)
api.run()เปิดอ่านหน้า http://127.0.0.1:5042/json ผลที่ได้จะเป็นแบบนี้

จะเห็นว่าในที่นี้โค้ด json ที่ได้จะมีการแปลง โดยอักษรไทยจะกลายเป็นรหัสยูนิโค้ดไป
เมื่อใช้ resp.media ข้อความจะถูกแปลงไปแบบนั้น ยังไม่มีวิธีที่จะแก้ให้ไม่แปลง หากต้องการให้แสดงผลตามนั้นก็อาจใช้มอดูล json จัดการแปลงเอง ถ้าใส่ ensure_ascii=False ก็จะไม่มีการแปลงอักษรไทยเป็นโค้ดแล้ว
นอกจากนี้ต้องระบุ charset ตรง resp.headers ด้วย
ตัวอย่างเช่น
import responder,json
def jsonsawatdi(req, resp):
resp.headers = {"Content-Type": "application/json; charset=utf-8"}
dic = {"ทักทาย": "สวัสดี สบายดี"}
resp.text = json.dumps(dic, ensure_ascii=False)
api = responder.API()
api.add_route('/jsonsawatdi',jsonsawatdi)
api.run()เปิดหน้า http://127.0.0.1:5042/jsonsawatdi
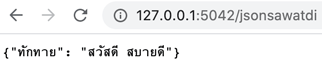
เกี่ยวกับการใช้มอดูล json ในไพธอน ดูรายละเอียดเพิ่มเติมได้ที่หน้านี้ >> https://phyblas.hinaboshi.com/20190427
resp.media ยังใช้กับข้อมูลรูปแบบอื่นได้ เช่น .yaml หากต้องการใช้กับ yaml ก็ใส่วงเล็บด้านหลังระบุเป็น
resp.media(format='yaml')ทำหน้าเว็บสำหรับดาวน์โหลดไฟล์
ในบางเว็บจะเห็นว่าเวลาที่เราเข้าเว็บไปนั้นแทนที่มันจะแสดงเนื้อหาในเบราว์เซอร์กลับกลายเป็นขึ้นให้ดาวน์โหลดไฟล์แทน
โดยปกติถ้าเข้าเว็บจะเป็นการเปิดดูหน้าเว็บทั่วไป แต่หากต้องการทำให้หน้าเว็บนั้นเป็นตัวโหลดข้อมูลก็ทำได้โดยตั้งที่ Content-Disposition ใน resp.headers เป็น attachment
ตัวอย่างเช่น
import responder
def load(req, resp):
resp.headers['Content-Disposition'] = 'attachment'
resp.text = 'ข้อมูล'
api = responder.API()
api.add_route('/load',load)
api.run()พอทำแบบนี้เมื่อเข้าไปที่หน้าเว็บ http://127.0.0.1:5042/load ก็จะกลายเป็นการขึ้นให้โหลดหน้านั้น แทนที่จะย้ายไปที่หน้านั้นตามปกติ
สามารถทำลิงก์โหลดข้อมูลไบนารีเช่นรูปภาพได้เช่นกัน
เช่นสมมุติว่าเตรียมไฟล์ภาพ xxx.jpg ไว้ ใส่ไว้ในโฟลเดอร์เดียวกับไฟล์โปรแกรม .py ที่เป็นตัวรัน อาจลองทำเป็นเว็บที่กดแล้วโหลดข้อมูลได้ในลักษณะนี้
import responder
# หน้าที่แสดงลิงก์โหลด
def linkload(req, resp):
resp.headers = {"Content-Type": "text/html; charset=utf-8"}
resp.html = '<a href="/loading" >กดเพื่อโหลด</a>'
resp.html += '<style>a {font-size: 50px}</style>'
# หน้าโหลด
def loading(req, resp):
resp.headers = {'Content-Disposition': 'attachment'}
with open('xxx.jpg','rb') as f:
resp.content = f.read()
api = responder.API()
api.add_route('/linkload',linkload)
api.add_route('/loading',loading)
api.run()เปิดหน้า http://127.0.0.1:5042/linkload ก็จะขึ้นมาแบบนี้
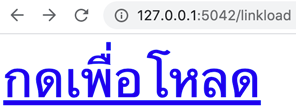
พอคลิกลิงก์ก็จะเริ่มโหลดไฟล์
ในกรณีโหลดข้อความใช้ resp.content เพื่ออ่านเนื้อหาแบบไบนารีจะดีกว่าใช้ resp.text ซึ่งจะอ่านเป็นตัวหนังสือ โดยเฉพาะเนื่องจากใช้ได้กับไฟล์ไบนารีเช่นไฟล์รูปภาพด้วย
เนื้อหาที่ใส่ลงใน resp.content นี้ใส่ข้อมูลที่เปิดอ่านจากไฟล์ที่เตรียมไว้ลงไปได้เลย โดยใช้ open() ในโหมดไบนารี (rb)
การกำหนดรหัสสถานะตอบรับ
สถานะตอบกลับซึ่งเป็นตัวบอกว่าหน้าเว็บโหลดได้เรียบร้อยหรือมีปัญหาอะไรนั้นสามารถกำหนดได้โดยใส่ที่แอตทริบิวต์ .status_code
ปกติถ้าไม่ได้ใส่อะไรก็จะเป็นสถานะปกติ คือ 200 คำร้องขอสำเร็จ
แต่ถ้าต้องการกำหนดสถานะเป็นอย่างอื่นก็ใส่ได้เลย เช่นลองใส่ 416 ซึ่งหมายถึงช่วงที่ร้องขอไม่เหมาะสม
import responder
rakha = {'แกงเขียวหวาน': 95, 'ต้มยำกุ้ง': 40, 'ส้มตำ': 200}
def durakha(req,resp,*,item):
resp.html = '<meta charset="UTF-8">'
if(item in rakha):
resp.html += '%s ราคา %d'%(item,rakha[item])
else:
resp.html += 'ไม่มีรายการที่ค้นหา'
resp.status_code = 416
api = responder.API()
api.add_route('/durakha/{item}',durakha)
api.run()จากนั้นถ้าเข้า http://127.0.0.1:5042/durakha/แกงเขียวหวาน ก็จะขึ้นข้อความแสดงราคามา แต่ถ้าเข้า http://127.0.0.1:5042/durakha/ข้าวมันไก่ ก็จะขึ้นว่า "ไม่มีรายการที่ค้นหา" แล้วส่งรหัสผิดพลาด 416 ออกมาด้วย
รายละเอียดเรื่องของโค้ดสถานะอาจอ่านได้เช่นใน >> https://support.microsoft.com/th-th/help/318380/description-of-microsoft-internet-information-services-iis-5-0-and-6-0
การใช้แม่แบบทำหน้าเว็บ
ในการสร้างตัวหน้าเว็บต่างๆขึ้น แทนที่จะเขียนโค้ด html ลงในนี้โดยตรง ปกตินิยมใช้แม่แบบมากกว่า
responder สามารถใช้แม่แบบของ jinja2 ได้
jinja2 เองก็เป็นมอดูลตัวหนึ่งของไพธอน ซึ่งก็สามารถลงได้ง่ายๆด้วย pip
pip install jinja2
เพียงแต่ว่าปกติเวลาที่ลง responder ไป jinja2 ก็จะถูกลงไปด้วยอยู่แล้ว จึงสามารถใช้ได้เลยโดยไม่ต้องอุตส่าห์มาลงเพิ่มเอง
แม่แบบของ jinja2 มีลักษณะคล้ายแม่แบบของ django แม้จะไม่ได้เหมือนซะทีเดียว เช่น ใช้วงเล็บปีกกา {{ }} เป็นหลักเหมือนกัน
รายละเอียดเพิ่มเติมอาจดูได้ที่เว็บหลักของ jinja2
โฟลเดอร์ที่จะใส่พวกไฟล์แม่แบบกำหนดโดยอาร์กิวเมนต์ templates_dir ตอนสร้าง responder.API ถ้าไม่ใส่จะเป็นค่าตั้งต้นคืออยู่ในโฟลเดอร์ชื่อ templates
สมมุติว่าสร้างตัวแม่แบบไว้ในไฟล์ buak.html และ err.html ซึ่งใส่ไว้ในโฟลเดอร์ tempura ที่อยู่ในที่เดียวกับไฟล์โปรแกรมตัวที่จะใช้รัน ดังนี้
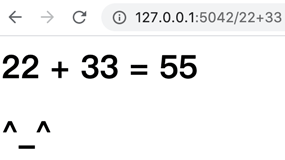
tempura/buak.html<h1>{{a}} + {{b}} = {{c}}</h1>
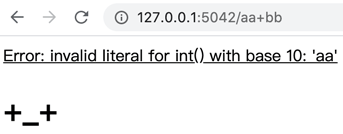
<h1>^_^</h1>tempura/err.html<u>Error: {{er}}</u>
<h1>+_+</h1>ตรงที่ล้อมด้วยวงเล็บปีกกาซ้อน {{ }} แบบนี้คือส่วนที่จะแทนค่าด้วยตัวแปร เราต้องเตรียมค่าตัวแปรนี้ไว้ตอนเรียกใช้แม่แบบด้วย
จากนั้นเรียกใช้แม่แบบโดยใช้เมธอด .template() จากตัวออบเจ็กต์ api
import responder
def buaklek(req,resp,*,xy):
try:
x,y = xy.split('+')
x = int(x)
y = int(y)
z = x+y
resp.html = api.template('buak.html',a=x,b=y,c=z)
except Exception as e:
resp.html = api.template('err.html',er=e)
resp.status_code = 416
api = responder.API(templates_dir='tempura')
api.add_route('/{xy}',buaklek)
api.run()ลองเข้า url เป็น http://127.0.0.1:5042/22+33 จะได้แบบนี้
หากเข้า url เป็น http://127.0.0.1:5042/aa+bb ก็จะเกิดข้อผิดพลาดแล้วได้แบบนี้
การใช้กับ async และ await
ในการใช้งานทั่วไป responder อาจใช้คู่กับ async และ await เพื่อทำงานแบบไม่ประสานเวลา
เรื่องเกี่ยวกับการใช้ async และ await ได้เคยเขียนเอาไว้ใน >> https://phyblas.hinaboshi.com/20200315
ฟังก์ชันที่ใช้ใส่ใน api.add_route() เพื่อกำหนดเนื้อหาหน้าเว็บนั้นนอกจากจะเป็นฟังก์ชันธรรมดา สามารถใช้ฟังก์ชัน async ได้
เช่น
import responder
async def asy(req, resp):
resp.html = 'xxxxxxxxx'
api = responder.API()
api.add_route('/',asy)
api.run()กรณีนี้ถึงจะตัด async ออก กลายเป็นฟังก์ชันธรรมดา ผลที่ได้ก็ไม่ได้ต่างกัน
อย่างไรก็ตาม แอตทริบิวต์บางส่วนของออบเจ็กต์คำร้องขอ (req) นั้นเวลาอ่านจะต้องใช้คู่กับ await ดังนั้นจึงจำเป็นต้องทำให้เป็นฟังก์ชัน async ไม่เช่นนั้นจะใช้ไม่ได้
แอตทริบิวต์ที่ต้องใช้ await เช่น req.content หรือ req.text หรือ req.media สำหรับอ่านเนื้อหาที่ส่งมากับคำร้องขอ นอกจากนี้ก็มีแอตทริบิวต์ req.encoding ซึ่งใช้ดูรูปแบบเอนโค้ดของตัวคำร้องขอ พวกนี้เมื่ออ่านข้อมูลจะทำงานแบบไม่ประสานเวลาจึงต้อง await
ยกตัวอย่างการใช้ req.encoding
import responder
async def enco(req, resp):
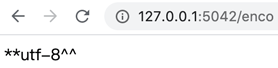
resp.html = '**' + await req.encoding + '^^'
api = responder.API()
api.add_route('/enco',enco)
api.run()เปิดดูหน้า http://127.0.0.1:5042/enco ก็จะได้ว่า
ทำหน้าเว็บสำหรับอัปโหลดไฟล์
เพื่อเป็นตัวอย่างของข้อมูลที่จำเป็นต้องมีการอ่านข้อมูลจาก req โดยใช้ async กับ await ลองมาดูการเขียนเว็บสำหรับอัปโหลดไฟล์
เตรียมไฟล์แม่แบบ ๒ หน้า คือหน้าหลัก index.html และหน้าที่จะให้แสดงหลังโหลดเสร็จแล้ว ok.html
tempura/index.html<meta charset="utf-8">
<form id="fileupload" action="/upload" method="post" enctype="multipart/form-data">
<input name="file" type="file" style="font-size: 20px">
<br><br>
<button type="submit" style="font-size: 16px">ส่งไฟล์</button>
</form>tempura/ok.html<meta charset="utf-8">
<h2>
{{chuefile}} อัปโหลดเรียบร้อย<br>
<a href="/">กลับหน้าแรก</a>
</h2>ตัวโปรแกรมรันเว็บ
import responder
# หน้าแรก แสดงฟอร์มอัปโหลด
def index(req, resp):
resp.html = api.template('index.html')
# หน้าที่ทำการอัปโหลด
async def upload(req, resp):
data = await req.media(format='files') # เอาข้อมูลตัวไฟล์
chuefile = data['file']['filename'] # ชื่อไฟล์
# เขียนเนื้อหาในไฟล์ที่อ่านได้ลงไฟล์
with open(chuefile,'wb') as f:
f.write(data['file']['content'])
# แสดงข้อความในหน้าเว็บเพื่อบอกว่าอัปโหลดเรียบร้อย
resp.html = api.template('ok.html',chuefile=chuefile)
api = responder.API(templates_dir='tempura')
api.add_route('/',index)
api.add_route('/upload',upload)
api.run()ในที่นี้ตรงส่วน req.media สำหรับดึงข้อมูลไฟล์นั้นต้องใช้กับ await จึงต้องทำให้ทั้งฟังก์ชัน upload เป็นฟังก์ชัน async ไว้ด้วย
จากนั้นลองเปิด http://127.0.0.1:5042 จะขึ้นฟอร์มให้ใส่ไฟล์ (ข้อความที่ขี้นตรงปุ่มเลือกไฟล์จะเปลี่ยนไปแล้วแต่ภาษาของเครื่อง ในที่นี้ใช้ภาษาจีนจึงขึ้นแบบนี้)
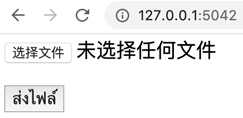
ลองเลือกไฟล์สักอันหนึ่งแล้วกด "ส่งไฟล์" เสร็จแล้วไฟล์ก็จะถูกอ่านเข้ามาแล้วบันทึกลงไปในโฟลเดอร์เดียวกับที่เรารันโปรแกรม
สมมุติว่าไฟล์ที่เราเลือกอัปโหลดชื่อ load.txt ถ้าไม่มีข้อผิดพลาดอะไรก็จะขึ้นหน้าแบบนี้มา เป็นอันเสร็จ

api.background.task
ปกติฟังก์ชันที่ใช้ใน api.add_route นั้นจะทำงานไปจนจบแล้วจึงแสดงผลหน้าเว็บออกมา
แต่หากมีบางบางอย่างที่ต้องการให้แยกไปทำในขณะเดียวกันก็อาจทำได้โดยตั้งให้เป็นภารกิจเบื้องหลัง (background task) โดยสร้างฟังก์ชันแล้วใส่เดคอเรเตอร์ api.background.task
ขอยกตัวอย่างการใช้ เช่นสร้างภารกิจฉากหลังให้ขึ้นว่าเวลาผ่านไปนานแค่ไหนแล้วหลังจากผ่านไปทีละ ๒.๕ วินาที ทั้งหมด ๔ ครั้ง
import responder,time
def sawatdi(req,resp):
# สร้างฟังก์ชันภารกิจเบื้องหลัง
@api.background.task
def rowelatham():
for i in range(4):
time.sleep(2.5)
print(f'ผ่านไปแล้ว {time.time()-t0:.4f} วินาที')
t0 = time.time() # เริ่มจับเวลา
rowelatham() # สั่งให้ภารกิจเบื้องหลังเริ่มแยกไปทำได้
# ส่วนนี้ทำต่อทันทีโดยไม่ต้องรอภารกิจเบื้องหลัง
resp.headers = {"Content-Type": "text/html; charset=utf-8"}
resp.html = f'<h1>สวัสดี</h1>ผ่านไปแล้ว {time.time()-t0:.4f} วินาที'
api = responder.API()
api.add_route('/',sawatdi)
api.run()เมื่อเปิด http://127.0.0.1:5042/ ก็จะขึ้นหน้าเว็บนี้
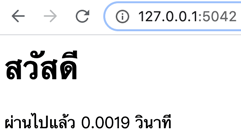
จากนั้นรอสักพักในคอมมานด์ไลน์ก็จะขึ้นแบบนี้มาเรื่อยๆตามเวลา
ผ่านไปแล้ว 2.5068 วินาที
ผ่านไปแล้ว 5.0121 วินาที
ผ่านไปแล้ว 7.5163 วินาที
ผ่านไปแล้ว 10.0206 วินาทีจะเห็นว่าหน้าเว็บปรากฏขึ้นมาเรียบร้อยแล้ว แต่ภารกิจเบื้องหลังก็ค่อยดำเนินการไปแยกกัน ไม่เกี่ยวข้องกัน แต่ยังไงก็จะไม่ส่งผลต่อหน้าเว็บ ตราบใดที่ไม่มีการโหลดใหม่
โดยรวมแล้วจะเห็นได้ว่าเมื่อใช้ responder แล้วทำให้สามารถสร้างเว็บได้ค่อนข้างง่ายทีเดียว และทำอะไรต่างๆได้มากมาย
ที่ยกมานี้ก็เป็นแค่ความสามารถส่วนหนึ่งในเบื้องต้น ส่วนรายละเอียดที่เหลืออาจอ่านได้ในเว็บหลักของ responder