ชุดข้อมูลตัวเลขที่เขียนด้วยลายมือของ MNIST สำหรับฝึกฝนการเรียนรู้ของเครื่อง
เขียนเมื่อ 2017/09/20 18:41
แก้ไขล่าสุด 2021/09/28 16:42
การเขียนโปรแกรมวิเคราะห์แยกแยะภาพเป็นการทดสอบความสามารถในการเขียนโปรแกรมสร้างปัญญาประดิษฐ์ (AI) ที่เป็นที่นิยมมากอย่างหนึ่ง
แบบฝึกการแยกภาพที่มีชื่อเสียงที่สุดและนิยมใช้กันมากก็คือชุดข้อมูลที่มีชื่อว่า MNIST
ฐานข้อมูล MNIST (Modified National Institute of Standards and Technology database) คือข้อมูลภาพขาวดำขนาด 28×28 จำนวนนับหมื่นภาพ ซึ่งแต่ละภาพคือภาพตัวเลข 0~9 ที่เขียนด้วยลายมือของคนต่างๆมากมาย
ตัวอย่างภาพส่วนหนึ่งจากในนั้น

ภาพเหล่านี้เขียนด้วยคนและคนทั่วไปก็มองแยกออกไม่ยากว่าเป็นตัวเลขอะไร แต่ว่าจะเขียนโปรแกรมยังไงให้เครื่องสามารถเรียนรู้และแยกแยกได้นั่นก็เป็นความท้าทายอย่างหนึ่ง
วิธีการดึงข้อมูล MNIST มาใช้มีหลายวิธี เช่นในหลายมอดูลมีคำสั่งสำหรับดึงข้อมูล MNIST แฝงอยู่ในตัว เช่น sklearn, tensorflow, keras
ในที่นี้จะขอใช้ sklearn เป็นตัวดึงข้อมูล เนื่องจากเป็นมอดูลพื้นฐานที่ทุกคนมักจะมีกันอยู่แล้ว
คำสั่งในการดึงข้อมูลอยู่ในมอดูลย่อยชื่อว่า datasets เช่นเดียวกับคำสั่งสร้างข้อมูลเป็นกลุ่มก้อนที่เคยเขียนถึงไปใน https://phyblas.hinaboshi.com/20161127
เพียงแต่ครั้งนี้ไม่ใช่จะสร้างข้อมูลขึ้นมาใหม่ แต่เป็นการดึงข้อมูลที่มีอยู่แล้วมาใช้ ข้อมูลเหล่านั้นมีขนาดใหญ่เกินกว่าที่จะใส่ติดมาในตัวมอดูล จึงถูกใส่ไว้อยู่ในเว็บ จึงต้องต่อเน็ตอยู่จึงจะใช้ได้
ฟังก์ชัน fetch_openml ซึ่งอยู่ภายในมอดูล datasets มีไว้ดึงข้อมูลที่ถูกเตรียมไว้ในเว็บ http://openml.org
เว็บนี้เป็นเว็บที่รวบรวมข้อมูลที่ใช้เป็นแบบฝึกสำหรับการเรียนรู้ของเครื่องมากมายหลายชนิด สามารถลองเข้าไปดูกันได้
ในที่นี้ลองใช้เพื่อดึงข้อมูล MNIST สามารถเขียนได้ดังนี้
เวลาจะใช้ครั้งแรกข้อมูลจะถูกโหลดจากเว็บมาเก็บไว้ในเครื่อง ดังนั้นครั้งแรกจึงต้องใช้เวลานานหน่อย แต่พอโหลดมาแล้วครั้งต่อไปก็จะดึงข้อมูลที่เก็บไว้ในเครื่องมาใช้
ปกติไฟล์จะถูกโหลดเก็บไว้ในโฟลเดอร์มาตรฐานชื่อ scikit_learn_data ภายในโฟลเดอร์บ้าน แต่ถ้าต้องการระบุที่เก็บเองก็ใส่ระบุคีย์เวิร์ดเพิ่มลงไปเป็น datasets.fetch_openml('mnist_784',data_home='ชื่อโฟลเดอร์')
หากต้องการโหลดข้อมูลอื่นก็แค่เปลี่ยนชื่อข้อมูลเป็นอย่างอื่น เช่น datasets.fetch_openml('leukemia')
ในที่นี้โหลดมาแล้วข้อมูลจะถูกเก็บอยู่ในตัวแปร mnist
ข้อมูลจะถูกเก็บอยู่ในแอตทริบิวต์ที่ชื่อ data โดยเป็นอาเรย์สองมิติ ส่วน ค่าตัวเลขที่เป็นคำตอบ (0~9) จะอยู่ใน target
ลองดูขนาดของข้อมูล
จะเห็นว่ามีข้อมูลทั้งหมด 70000 แถว ก็คือมีภาพตัวเลขทั้งหมด 70000 ภาพ ส่วน 784 นี่คือขนาดของข้อมูล โดยข้อมูลนี้เป็นค่าความเข้มของดินสอในแต่ละช่อง ขนาดภาพ 28×28 จึงมี 784 ค่า
ลอง print(mnist.data[1]) จะได้ค่าตัวเลขตั้งแต่ 0 (บริเวณว่าง) ไปจนถึง 255 (บริเวณที่ถูกเขียน)
เอามาวาดเป็นภาพดูได้ โดยต้องทำการ reshape เป็น 28×28 ก่อน
จะเห็นว่าเป็นรูปเลข 0
หรือลองดูตัวเลขอื่นๆ
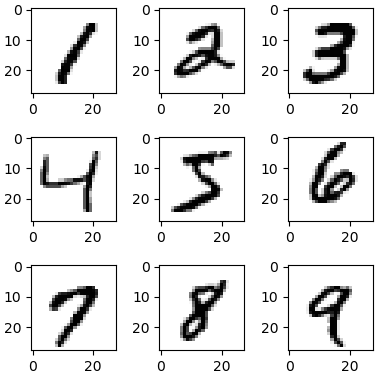
ตัวเลขพวกนี้คือสิ่งที่จะป้อนให้โปรแกรมของเราเรียนรู้ แบบนี้โปรแกรมเราก็จะเหมือนกับเด็กน้อยไร้เดียงสาที่พยายามหัดจดจำ หัดแยกแยะว่าภาพนี้คือตัวเลขนี้ ภาพนั้นคือตัวเลขนั้น

แล้วในที่สุดก็จะทายภาพที่ไม่เคยเห็นได้อย่างถูกต้อง

การเขียนโปรแกรมให้เครื่องเรียนรู้เพื่อแยกแยะตัวเลขพวกนี้มีหลายวิธี สามารถดูตัวอย่างวิธีการต่างๆได้ดังนี้
- การถดถอยโลจิสติก https://phyblas.hinaboshi.com/20170922
- วิธีการเพื่อนบ้านใกล้สุด k ตัว https://phyblas.hinaboshi.com/20171102
- ต้นไม้ตัดสินใจและป่าสุ่ม https://phyblas.hinaboshi.com/20171123
- วิธีการ k เฉลี่ย https://phyblas.hinaboshi.com/20171228
แบบฝึกการแยกภาพที่มีชื่อเสียงที่สุดและนิยมใช้กันมากก็คือชุดข้อมูลที่มีชื่อว่า MNIST
ฐานข้อมูล MNIST (Modified National Institute of Standards and Technology database) คือข้อมูลภาพขาวดำขนาด 28×28 จำนวนนับหมื่นภาพ ซึ่งแต่ละภาพคือภาพตัวเลข 0~9 ที่เขียนด้วยลายมือของคนต่างๆมากมาย
ตัวอย่างภาพส่วนหนึ่งจากในนั้น
ภาพเหล่านี้เขียนด้วยคนและคนทั่วไปก็มองแยกออกไม่ยากว่าเป็นตัวเลขอะไร แต่ว่าจะเขียนโปรแกรมยังไงให้เครื่องสามารถเรียนรู้และแยกแยกได้นั่นก็เป็นความท้าทายอย่างหนึ่ง
วิธีการดึงข้อมูล MNIST มาใช้มีหลายวิธี เช่นในหลายมอดูลมีคำสั่งสำหรับดึงข้อมูล MNIST แฝงอยู่ในตัว เช่น sklearn, tensorflow, keras
ในที่นี้จะขอใช้ sklearn เป็นตัวดึงข้อมูล เนื่องจากเป็นมอดูลพื้นฐานที่ทุกคนมักจะมีกันอยู่แล้ว
คำสั่งในการดึงข้อมูลอยู่ในมอดูลย่อยชื่อว่า datasets เช่นเดียวกับคำสั่งสร้างข้อมูลเป็นกลุ่มก้อนที่เคยเขียนถึงไปใน https://phyblas.hinaboshi.com/20161127
เพียงแต่ครั้งนี้ไม่ใช่จะสร้างข้อมูลขึ้นมาใหม่ แต่เป็นการดึงข้อมูลที่มีอยู่แล้วมาใช้ ข้อมูลเหล่านั้นมีขนาดใหญ่เกินกว่าที่จะใส่ติดมาในตัวมอดูล จึงถูกใส่ไว้อยู่ในเว็บ จึงต้องต่อเน็ตอยู่จึงจะใช้ได้
ฟังก์ชัน fetch_openml ซึ่งอยู่ภายในมอดูล datasets มีไว้ดึงข้อมูลที่ถูกเตรียมไว้ในเว็บ http://openml.org
เว็บนี้เป็นเว็บที่รวบรวมข้อมูลที่ใช้เป็นแบบฝึกสำหรับการเรียนรู้ของเครื่องมากมายหลายชนิด สามารถลองเข้าไปดูกันได้
ในที่นี้ลองใช้เพื่อดึงข้อมูล MNIST สามารถเขียนได้ดังนี้
from sklearn import datasets
mnist = datasets.fetch_openml('mnist_784')เวลาจะใช้ครั้งแรกข้อมูลจะถูกโหลดจากเว็บมาเก็บไว้ในเครื่อง ดังนั้นครั้งแรกจึงต้องใช้เวลานานหน่อย แต่พอโหลดมาแล้วครั้งต่อไปก็จะดึงข้อมูลที่เก็บไว้ในเครื่องมาใช้
ปกติไฟล์จะถูกโหลดเก็บไว้ในโฟลเดอร์มาตรฐานชื่อ scikit_learn_data ภายในโฟลเดอร์บ้าน แต่ถ้าต้องการระบุที่เก็บเองก็ใส่ระบุคีย์เวิร์ดเพิ่มลงไปเป็น datasets.fetch_openml('mnist_784',data_home='ชื่อโฟลเดอร์')
หากต้องการโหลดข้อมูลอื่นก็แค่เปลี่ยนชื่อข้อมูลเป็นอย่างอื่น เช่น datasets.fetch_openml('leukemia')
ในที่นี้โหลดมาแล้วข้อมูลจะถูกเก็บอยู่ในตัวแปร mnist
ข้อมูลจะถูกเก็บอยู่ในแอตทริบิวต์ที่ชื่อ data โดยเป็นอาเรย์สองมิติ ส่วน ค่าตัวเลขที่เป็นคำตอบ (0~9) จะอยู่ใน target
ลองดูขนาดของข้อมูล
print(mnist.data.shape) # ได้ (70000, 784)
print(mnist.target.shape) # ได้ (70000,)
print(mnist.target) # ได้ ['5' '0' '4' ... '4' '5' '6']จะเห็นว่ามีข้อมูลทั้งหมด 70000 แถว ก็คือมีภาพตัวเลขทั้งหมด 70000 ภาพ ส่วน 784 นี่คือขนาดของข้อมูล โดยข้อมูลนี้เป็นค่าความเข้มของดินสอในแต่ละช่อง ขนาดภาพ 28×28 จึงมี 784 ค่า
ลอง print(mnist.data[1]) จะได้ค่าตัวเลขตั้งแต่ 0 (บริเวณว่าง) ไปจนถึง 255 (บริเวณที่ถูกเขียน)
เอามาวาดเป็นภาพดูได้ โดยต้องทำการ reshape เป็น 28×28 ก่อน
import matplotlib.pyplot as plt
plt.imshow(mnist.data[1].reshape(28,28),cmap='gray_r')
plt.show()จะเห็นว่าเป็นรูปเลข 0
หรือลองดูตัวเลขอื่นๆ
target = mnist.target.astype(int)
plt.figure(figsize=[4,4],dpi=100)
for i in range(1,10):
plt.subplot(330+i)
ii = list(target).index(i)
plt.imshow(mnist.data[ii].reshape(28,28),cmap='gray_r')
plt.tight_layout()
plt.show()ตัวเลขพวกนี้คือสิ่งที่จะป้อนให้โปรแกรมของเราเรียนรู้ แบบนี้โปรแกรมเราก็จะเหมือนกับเด็กน้อยไร้เดียงสาที่พยายามหัดจดจำ หัดแยกแยะว่าภาพนี้คือตัวเลขนี้ ภาพนั้นคือตัวเลขนั้น
แล้วในที่สุดก็จะทายภาพที่ไม่เคยเห็นได้อย่างถูกต้อง
การเขียนโปรแกรมให้เครื่องเรียนรู้เพื่อแยกแยะตัวเลขพวกนี้มีหลายวิธี สามารถดูตัวอย่างวิธีการต่างๆได้ดังนี้
- การถดถอยโลจิสติก https://phyblas.hinaboshi.com/20170922
- วิธีการเพื่อนบ้านใกล้สุด k ตัว https://phyblas.hinaboshi.com/20171102
- ต้นไม้ตัดสินใจและป่าสุ่ม https://phyblas.hinaboshi.com/20171123
- วิธีการ k เฉลี่ย https://phyblas.hinaboshi.com/20171228
-----------------------------------------
囧囧囧囧囧囧囧囧囧囧囧囧囧囧囧囧囧囧囧囧囧囧囧囧囧
หมวดหมู่
-- คอมพิวเตอร์ >> ปัญญาประดิษฐ์-- คอมพิวเตอร์ >> เขียนโปรแกรม >> python >> numpy
-- คอมพิวเตอร์ >> เขียนโปรแกรม >> python >> matplotlib
-- คอมพิวเตอร์ >> เขียนโปรแกรม >> python >> sklearn