ความแตกต่างของการเรียนรู้ของเครื่องแบบมีและไม่มีผู้สอน
เขียนเมื่อ 2017/12/15 00:17
แก้ไขล่าสุด 2024/10/03 19:33
เทคนิคการเรียนรู้ของเครื่องนั้นโดยหลักๆแล้วอาจแบ่งตามลักษณะของข้อมูลที่ป้อนให้โปรแกรมใช้เรียนรู้ได้เป็น
- การเรียนรู้แบบมีผู้สอน (监督式学习, supervised learning)
- การเรียนรู้แบบไม่มีผู้สอน (非监督式学习, unsupervised learning)
นอกจากนี้ยังมีการเรียนรู้แบบเสริมกำลัง (强化学习, reinforcement learning) ซึ่งจริงๆลักษณะจะคล้ายกับการเรียนรู้แบบมีผู้สอน แต่มักจะถูกแบ่งเป็นชนิดแยกไว้ ในที่นี้จะยังไม่ขอพูดถึงในรายละเอียด
พอพูดถึงว่ามีผู้สอนกับไม่มีผู้สอนต่างกันยังไง เราอาจนึกภาพว่ามีผู้สอนก็คือเรียนกับอาจารย์ เอาโจทย์มาให้ทำแล้วบอกว่าข้อนี้ต้องทำอย่างนี้ตอบแบบนี้

ไม่มีผู้สอนคืออ่านโจทย์แล้วคิดเอาเองว่าอะไรคืออะไรแล้วก็เข้าใจเอง

"การสอน" ในที่นี้ก็คือการบอกคำตอบที่ถูกต้องให้นั่นเอง
ในการเรียนรู้แบบมีผู้สอน เราจะป้อนข้อมูลขาเข้า ก็คือตัวแปรต้นต่างๆ พร้อมกับป้อนข้อมูลขาออก ก็คือผลลัพธ์ที่เป็นผลจากตัวแปรต้นนั้นๆ
แบบนี้โปรแกรมก็จะไปเรียนรู้สร้างความเชื่อมโยงว่าถ้าได้ข้อมูลเข้ามาลักษณะแบบนี้จะได้ผลลัพธ์ยังไงออกมา
แต่ในการเรียนรู้แบบไม่มีผู้สอน เราจะป้อนแค่ข้อมูลขาเข้า แต่ไม่ป้อนข้อมูลขาออกให้ โปรแกรมจะทำการหาทางเรียนรู้อะไรบางอย่างจากข้อมูลที่ป้อนเข้าไปนี้เอง
ขอยกตัวอย่างเป็นปัญหาการแบ่งกลุ่ม เช่น ต้องการจะแบ่งว่าสีแบบไหนเป็นสีแดงหรือฟ้าโดยดูจากค่าสี
สมมุติว่ามีลูกปัดจำนวนหนึ่ง มีสีต่างกันไป เมื่อนำมาวาดแผนภาพดูการแจกแจงของค่าสีก็ได้ตามนี้
ในภาพนี้แกนตั้งคือค่าความเข้มสีฟ้า (=เขียวและน้ำเงิน) แกนนอนคือความเข้มสีแดง สีของจุดที่แสดงคือสีตามค่านั้นจริงๆ
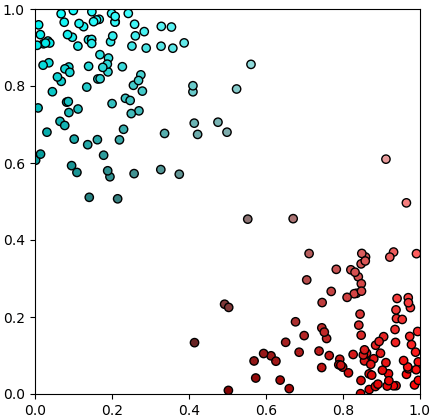
พอแบ่งแล้วก็อาจแบ่งได้ในลักษณะประมาณนี้
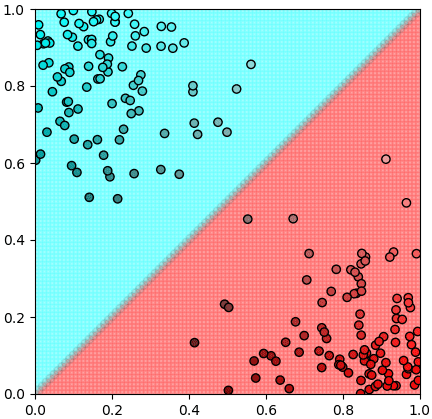
อนึ่ง ภาพตัวอย่างนี้อาจถูกวาดได้โดยโค้ดไพธอนตามนี้
สำหรับปัญหาการแบ่งกลุ่มแบบนี้ถ้าหากเป็นการเรียนรู้แบบมีผู้สอนเราให้ข้อมูลค่าสีของแต่ละจุด พร้อมกับบอกด้วยว่าจุดนั้นเป็นสีอะไร

จากนั้นโปรแกรมก็จะจำว่าสีประมาณนี้คือสีอะไร

แล้วพอลองให้ดูสีใหม่ที่ไม่เคยเห็นก็จะบอกได้ว่านี่เป็นสีอะไร

แต่ถ้าเป็นการเรียนรู้แบบไม่มีผู้สอนจะให้แค่ข้อมูลค่าสีของแต่ละจุด ไม่ได้บอกว่าจุดนั้นเรียกว่าเป็นสีอะไร แล้วให้โปรแกรมทำการหาความแตกต่างในกลุ่มข้อมูล แล้วแยกข้อมูลเอาเอง

ในที่สุดโปรแกรมจะสามารถแยกได้ว่ากระจุกนี้คือสี 1 กระจุกนี้คือสี 2 แต่ไม่ว่ายังไงก็จะไม่รู้อยู่ดีว่ากระจุกไหนคือเขียวหรือแดง เพราะไม่ได้ให้ข้อมูลไว้ แค่จะรู้แน่ๆว่าสองกลุ่มนี้มันต่างกัน

แล้วพอเราให้ดูสีใหม่ที่ไม่เคยเห็น ก็จะทำนายออกมาว่าเป็นสีในกลุ่มไหนได้ แม้จะไม่รู้ว่ากลุ่มที่แบ่งออกมาได้นี้เรียกว่าเป็นสีอะไร เพราะไม่ได้สอน

เพียงแต่ว่า โดยทั่วไปแล้วงานของการแบ่งกลุ่มแบบไม่มีผู้สอนนั้นมักจะมีเป้าหมายแค่แบ่งกลุ่มข้อมูลที่ใช้เรียนรู้นี้ได้สำเร็จ อาจไม่ได้เอาไปใช้ทำนายกลุ่มข้อมูลอื่นต่อ
ในขณะที่แบบมีผู้สอนนั้น เรารู้อยู่แล้วว่าข้อมูลที่ใช้เรียนรู้นี้จัดอยู่ในกลุ่มไหน เป้าหมายจึงอยู่ที่การสร้างบรรทัดฐานขึ้นเพื่อทำนายว่าข้อมูลอื่นที่ไม่ได้ใช้เรียนรู้นั้นอยู่กลุ่มไหน
ดังนั้นที่จริงแล้วทั้งสองวิธีนี้ต่างกันตั้งแต่จุดประสงค์เป้าหมายการใช้งานแล้ว
และจะเห็นได้ว่าการเรียนรู้แบบไม่มีผู้สอนจะแบ่งกลุ่มได้ลำบากหากข้อมูลมาแบบกระจายสม่ำเสมอต่อเนื่อง เช่นแบบนี้ อาจแยกเป็นกระจุกได้หลายวิธี ไม่มีคำตอบที่ชัดเจนแน่นอน
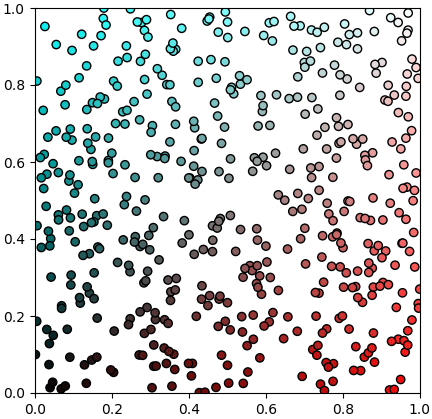
ตัวอย่างวิธีการแบ่งกลุ่มด้วยการเรียนรู้แบบมีผู้สอนมีมากมายหลายวิธี เช่น
- การถดถอยโลจิสติก (逻辑回归, logistic regression)
- เครื่องเวกเตอร์ค้ำยัน (支持向量机, support vector machine, SVM)
- เพื่อนบ้านใกล้สุด k ตัว (K-近邻算法, k-nearest neighbor, KNN)
- ตัวแบ่งกลุ่มเบส์อย่างง่าย (朴素贝叶斯分类器, naïve Bayes classifier)
- ต้นไม้ตัดสินใจ (决策树, decision tree)
- ป่าสุ่ม (随机森林, random forest)
- ฯลฯ
ส่วนวิธีการแบ่งกลุ่มข้อมูลด้วยการเรียนรู้แบบไม่มีผู้สอนนั้นมีชื่อเรียกว่า การแบ่งกระจุกข้อมูล (聚类分析, data clustering)
ตัวอย่างวิธีการนี้ได้แก่
- การแบ่ง k เฉลี่ย (K-平均算法, k-means)
- การแบ่งเป็นลำดับขั้นแบบจับเป็นกลุ่มก้อน (聚合式阶层演算法, agglomerative hierarchical)
- DBSCAN (Density-based spatial clustering of applications with noise)
- การทำแผนที่โยงก่อร่างตัวเอง (自组织映射, self-organizing map, SOM)
- ฯลฯ
นอกจากนี้แล้วในส่วนของวิธีการจัดการข้อมูลเบื้องต้นเองก็มีการแบ่งเป็นแบบมีผู้สอนกับไม่มีผู้สอนเช่นกัน
แบบไม่มีผู้สอนได้แก่ การวิเคราะห์องค์ประกอบหลัก (主成分分析, principal components analysis, PCA)
แบบมีผู้สอนได้แก่ การวิเคราะห์การจำแนกประเภทเชิงเส้น (线性判别分析, linear discriminant analysis, LDA)
สำหรับรายละเอียดวิธีการต่างๆนั้นส่วนหนึ่งได้มีเขียนแนะนำไว้ อ่านได้ใน https://phyblas.hinaboshi.com/saraban/kanrianrukhongkhrueang
อ้างอิง
- การเรียนรู้แบบมีผู้สอน (监督式学习, supervised learning)
- การเรียนรู้แบบไม่มีผู้สอน (非监督式学习, unsupervised learning)
นอกจากนี้ยังมีการเรียนรู้แบบเสริมกำลัง (强化学习, reinforcement learning) ซึ่งจริงๆลักษณะจะคล้ายกับการเรียนรู้แบบมีผู้สอน แต่มักจะถูกแบ่งเป็นชนิดแยกไว้ ในที่นี้จะยังไม่ขอพูดถึงในรายละเอียด
พอพูดถึงว่ามีผู้สอนกับไม่มีผู้สอนต่างกันยังไง เราอาจนึกภาพว่ามีผู้สอนก็คือเรียนกับอาจารย์ เอาโจทย์มาให้ทำแล้วบอกว่าข้อนี้ต้องทำอย่างนี้ตอบแบบนี้
ไม่มีผู้สอนคืออ่านโจทย์แล้วคิดเอาเองว่าอะไรคืออะไรแล้วก็เข้าใจเอง
"การสอน" ในที่นี้ก็คือการบอกคำตอบที่ถูกต้องให้นั่นเอง
ในการเรียนรู้แบบมีผู้สอน เราจะป้อนข้อมูลขาเข้า ก็คือตัวแปรต้นต่างๆ พร้อมกับป้อนข้อมูลขาออก ก็คือผลลัพธ์ที่เป็นผลจากตัวแปรต้นนั้นๆ
แบบนี้โปรแกรมก็จะไปเรียนรู้สร้างความเชื่อมโยงว่าถ้าได้ข้อมูลเข้ามาลักษณะแบบนี้จะได้ผลลัพธ์ยังไงออกมา
แต่ในการเรียนรู้แบบไม่มีผู้สอน เราจะป้อนแค่ข้อมูลขาเข้า แต่ไม่ป้อนข้อมูลขาออกให้ โปรแกรมจะทำการหาทางเรียนรู้อะไรบางอย่างจากข้อมูลที่ป้อนเข้าไปนี้เอง
ขอยกตัวอย่างเป็นปัญหาการแบ่งกลุ่ม เช่น ต้องการจะแบ่งว่าสีแบบไหนเป็นสีแดงหรือฟ้าโดยดูจากค่าสี
สมมุติว่ามีลูกปัดจำนวนหนึ่ง มีสีต่างกันไป เมื่อนำมาวาดแผนภาพดูการแจกแจงของค่าสีก็ได้ตามนี้
ในภาพนี้แกนตั้งคือค่าความเข้มสีฟ้า (=เขียวและน้ำเงิน) แกนนอนคือความเข้มสีแดง สีของจุดที่แสดงคือสีตามค่านั้นจริงๆ
พอแบ่งแล้วก็อาจแบ่งได้ในลักษณะประมาณนี้
อนึ่ง ภาพตัวอย่างนี้อาจถูกวาดได้โดยโค้ดไพธอนตามนี้
import numpy as np
import matplotlib.pyplot as plt
X = np.abs(np.random.RandomState(0).normal(0,0.22,[200,2]))
X[100:,0] = -X[100:,0]+1
X[:100,1] = -X[:100,1]+1
for i in [0,1]:
plt.figure(figsize=[5,5])
plt.axes(aspect=1,xlim=[0,1],ylim=[0,1])
plt.scatter(X[:,0],X[:,1],c=np.hstack([X,X[:,1:]]),edgecolor='k')
if(i):
z = np.hstack([np.ones(100),np.zeros(100)])
m = np.meshgrid(np.linspace(0,1,100),np.linspace(0,1,100))
m[0],m[1] = m[0].ravel(),m[1].ravel()
plt.scatter(m[0],m[1],c=np.vstack([m[0]>m[1],m[1]>m[0],m[1]>m[0]]).T,alpha=0.1,zorder=0)
plt.show()สำหรับปัญหาการแบ่งกลุ่มแบบนี้ถ้าหากเป็นการเรียนรู้แบบมีผู้สอนเราให้ข้อมูลค่าสีของแต่ละจุด พร้อมกับบอกด้วยว่าจุดนั้นเป็นสีอะไร
จากนั้นโปรแกรมก็จะจำว่าสีประมาณนี้คือสีอะไร
แล้วพอลองให้ดูสีใหม่ที่ไม่เคยเห็นก็จะบอกได้ว่านี่เป็นสีอะไร
แต่ถ้าเป็นการเรียนรู้แบบไม่มีผู้สอนจะให้แค่ข้อมูลค่าสีของแต่ละจุด ไม่ได้บอกว่าจุดนั้นเรียกว่าเป็นสีอะไร แล้วให้โปรแกรมทำการหาความแตกต่างในกลุ่มข้อมูล แล้วแยกข้อมูลเอาเอง
ในที่สุดโปรแกรมจะสามารถแยกได้ว่ากระจุกนี้คือสี 1 กระจุกนี้คือสี 2 แต่ไม่ว่ายังไงก็จะไม่รู้อยู่ดีว่ากระจุกไหนคือเขียวหรือแดง เพราะไม่ได้ให้ข้อมูลไว้ แค่จะรู้แน่ๆว่าสองกลุ่มนี้มันต่างกัน
แล้วพอเราให้ดูสีใหม่ที่ไม่เคยเห็น ก็จะทำนายออกมาว่าเป็นสีในกลุ่มไหนได้ แม้จะไม่รู้ว่ากลุ่มที่แบ่งออกมาได้นี้เรียกว่าเป็นสีอะไร เพราะไม่ได้สอน
เพียงแต่ว่า โดยทั่วไปแล้วงานของการแบ่งกลุ่มแบบไม่มีผู้สอนนั้นมักจะมีเป้าหมายแค่แบ่งกลุ่มข้อมูลที่ใช้เรียนรู้นี้ได้สำเร็จ อาจไม่ได้เอาไปใช้ทำนายกลุ่มข้อมูลอื่นต่อ
ในขณะที่แบบมีผู้สอนนั้น เรารู้อยู่แล้วว่าข้อมูลที่ใช้เรียนรู้นี้จัดอยู่ในกลุ่มไหน เป้าหมายจึงอยู่ที่การสร้างบรรทัดฐานขึ้นเพื่อทำนายว่าข้อมูลอื่นที่ไม่ได้ใช้เรียนรู้นั้นอยู่กลุ่มไหน
ดังนั้นที่จริงแล้วทั้งสองวิธีนี้ต่างกันตั้งแต่จุดประสงค์เป้าหมายการใช้งานแล้ว
และจะเห็นได้ว่าการเรียนรู้แบบไม่มีผู้สอนจะแบ่งกลุ่มได้ลำบากหากข้อมูลมาแบบกระจายสม่ำเสมอต่อเนื่อง เช่นแบบนี้ อาจแยกเป็นกระจุกได้หลายวิธี ไม่มีคำตอบที่ชัดเจนแน่นอน
ตัวอย่างวิธีการแบ่งกลุ่มด้วยการเรียนรู้แบบมีผู้สอนมีมากมายหลายวิธี เช่น
- การถดถอยโลจิสติก (逻辑回归, logistic regression)
- เครื่องเวกเตอร์ค้ำยัน (支持向量机, support vector machine, SVM)
- เพื่อนบ้านใกล้สุด k ตัว (K-近邻算法, k-nearest neighbor, KNN)
- ตัวแบ่งกลุ่มเบส์อย่างง่าย (朴素贝叶斯分类器, naïve Bayes classifier)
- ต้นไม้ตัดสินใจ (决策树, decision tree)
- ป่าสุ่ม (随机森林, random forest)
- ฯลฯ
ส่วนวิธีการแบ่งกลุ่มข้อมูลด้วยการเรียนรู้แบบไม่มีผู้สอนนั้นมีชื่อเรียกว่า การแบ่งกระจุกข้อมูล (聚类分析, data clustering)
ตัวอย่างวิธีการนี้ได้แก่
- การแบ่ง k เฉลี่ย (K-平均算法, k-means)
- การแบ่งเป็นลำดับขั้นแบบจับเป็นกลุ่มก้อน (聚合式阶层演算法, agglomerative hierarchical)
- DBSCAN (Density-based spatial clustering of applications with noise)
- การทำแผนที่โยงก่อร่างตัวเอง (自组织映射, self-organizing map, SOM)
- ฯลฯ
นอกจากนี้แล้วในส่วนของวิธีการจัดการข้อมูลเบื้องต้นเองก็มีการแบ่งเป็นแบบมีผู้สอนกับไม่มีผู้สอนเช่นกัน
แบบไม่มีผู้สอนได้แก่ การวิเคราะห์องค์ประกอบหลัก (主成分分析, principal components analysis, PCA)
แบบมีผู้สอนได้แก่ การวิเคราะห์การจำแนกประเภทเชิงเส้น (线性判别分析, linear discriminant analysis, LDA)
สำหรับรายละเอียดวิธีการต่างๆนั้นส่วนหนึ่งได้มีเขียนแนะนำไว้ อ่านได้ใน https://phyblas.hinaboshi.com/saraban/kanrianrukhongkhrueang
อ้างอิง
-----------------------------------------
囧囧囧囧囧囧囧囧囧囧囧囧囧囧囧囧囧囧囧囧囧囧囧囧囧
หมวดหมู่
-- คอมพิวเตอร์ >> ปัญญาประดิษฐ์-- คอมพิวเตอร์ >> เขียนโปรแกรม >> python >> numpy
-- คอมพิวเตอร์ >> เขียนโปรแกรม >> python >> matplotlib