pytorch เบื้องต้น บทที่ ๑๖: การเรียนรู้แบบถ่ายโอน
เขียนเมื่อ 2018/09/29 21:38
แก้ไขล่าสุด 2022/07/09 14:15
>> ต่อจาก บทที่ ๑๕
การเรียนรู้ของโครงข่ายประสาทเทียมยิ่งลึกยิ่งใช้เวลาในการฝึกนานมาก และส่วนใหญ่พอฝึกเสร็จก็แค่ถูกนำไปใช้กับแค่งานเฉพาะทาง
แต่ก็มีบางแบบจำลองที่ถูกฝึกมาให้ใช้งานได้กว้างขวาง เพียงแค่ปรับอะไรบางอย่างเพิ่มเติม ไม่ต้องฝึกใหม่ทั้งหมดก็สามารถนำมาใช้กับงานอื่นๆต่อได้
การนำแบบจำลองที่ฝึกเสร็จแล้วมาใช้ในงานอื่นต่อเรียกว่าการเรียนรู้แบบถ่ายโอน (transfer learning)
วิธีการโดยทั่วไปก็คือ เอาแบบจำลองที่ฝึกเสร็จแล้วมาปรับแก้แค่ชั้นสุดท้ายให้เข้ากับงานที่ตัวเองต้องการใช้
ค่าพารามิเตอร์ที่ได้มาจากการฝึกเสร็จแล้วอาจถูกนำมาใช้เป็นค่าเริ่มต้นเพื่อทำการฝึกต่อ หรือบางทีก็อาจจะนำค่านั้นมาใช้โดยไม่มีการฝึกต่อ คือฝึกแค่ชั้นสุดท้ายใหม่ โดยคงค่าพารามิเตอร์ของชั้นอื่นๆทั้งหมดไว้
pytorch ได้เตรียมแบบจำลองส่วนหนึ่งที่สร้างผลงานได้โดดเด่นและนิยมใช้ที่เรียนรู้เสร็จแล้ว โดยอยู่ใน torchvision.models.
ลองดูว่ามีแบบจำลองแบบไหนบ้างและแต่ละแบบมีพารามิเตอร์มากแค่ไหน
from torchvision import models as md
# ฟังก์ชันนับจำนวนพารามิเตอร์
def nap_param(khrongkhai):
param = list(khrongkhai.parameters())
return len(param),sum([p.data.numpy().size for p in param])
nap_param(md.resnet18())
function = type(lambda _:_)
# แบบจำลองทั้งหมดสร้างจากฟังก์ชัน จึงใช้วิธีไล่ค้นหาฟังก์ชันแล้วเรียกมาดูทีละตัว
for d in dir(md):
f = getattr(md,d)
if(type(f)==function):
try:
print('%s: %s'%(d,nap_param(f())))
except:
0ได้
alexnet: (16, 61100840)
convnext_base: (344, 88591464)
convnext_large: (344, 197767336)
convnext_small: (344, 50223688)
convnext_tiny: (182, 28589128)
densenet121: (364, 7978856)
densenet161: (484, 28681000)
densenet169: (508, 14149480)
densenet201: (604, 20013928)
efficientnet_b0: (213, 5288548)
efficientnet_b1: (301, 7794184)
efficientnet_b2: (301, 9109994)
efficientnet_b3: (340, 12233232)
efficientnet_b4: (418, 19341616)
efficientnet_b5: (506, 30389784)
efficientnet_b6: (584, 43040704)
efficientnet_b7: (711, 66347960)
efficientnet_v2_l: (897, 118515272)
efficientnet_v2_m: (649, 54139356)
efficientnet_v2_s: (452, 21458488)
googlenet: (187, 13004888)
inception_v3: (292, 27161264)
mnasnet0_5: (158, 2218512)
mnasnet0_75: (158, 3170208)
mnasnet1_0: (158, 4383312)
mnasnet1_3: (158, 6282256)
mobilenet_v2: (158, 3504872)
mobilenet_v3_large: (174, 5483032)
mobilenet_v3_small: (142, 2542856)
regnet_x_16gf: (215, 54278536)
regnet_x_1_6gf: (179, 9190136)
regnet_x_32gf: (224, 107811560)
regnet_x_3_2gf: (242, 15296552)
regnet_x_400mf: (215, 5495976)
regnet_x_800mf: (161, 7259656)
regnet_x_8gf: (224, 39572648)
regnet_y_128gf: (368, 644812894)
regnet_y_16gf: (251, 83590140)
regnet_y_1_6gf: (368, 11202430)
regnet_y_32gf: (277, 145046770)
regnet_y_3_2gf: (290, 19436338)
regnet_y_400mf: (225, 4344144)
regnet_y_800mf: (199, 6432512)
regnet_y_8gf: (238, 39381472)
resnet101: (314, 44549160)
resnet152: (467, 60192808)
resnet18: (62, 11689512)
resnet34: (110, 21797672)
resnet50: (161, 25557032)
resnext101_32x8d: (314, 88791336)
resnext101_64x4d: (314, 83455272)
resnext50_32x4d: (161, 25028904)
shufflenet_v2_x0_5: (170, 1366792)
shufflenet_v2_x1_0: (170, 2278604)
shufflenet_v2_x1_5: (170, 3503624)
shufflenet_v2_x2_0: (170, 7393996)
squeezenet1_0: (52, 1248424)
squeezenet1_1: (52, 1235496)
swin_b: (329, 87768224)
swin_s: (329, 49606258)
swin_t: (173, 28288354)
vgg11: (22, 132863336)
vgg11_bn: (38, 132868840)
vgg13: (26, 133047848)
vgg13_bn: (46, 133053736)
vgg16: (32, 138357544)
vgg16_bn: (58, 138365992)
vgg19: (38, 143667240)
vgg19_bn: (70, 143678248)
vit_b_16: (152, 86567656)
vit_b_32: (152, 88224232)
vit_h_14: (392, 632045800)
vit_l_16: (296, 304326632)
vit_l_32: (296, 306535400)
wide_resnet101_2: (314, 126886696)
wide_resnet50_2: (161, 68883240)แบบจำลองทั้งหมดนี้เป็นโครงข่ายประสาทแบบคอนโวลูชันที่ใช้เพื่อวิเคราะห์ข้อมูลรูปภาพเหมือนกันหมด แต่มีโครงสร้างที่แตกต่างกันออกไป
ตอนโหลดแบบจำลองมาใช้ ถ้าใส่ 1 (True) ในวงเล็บจะเป็นการเอาพารามิเตอร์ที่ได้จากการฝึกมาใช้ด้วย ถ้าไม่ใส่จะเป็นการเริ่มต้นใหม่ทั้งหมด
หากเลือกที่จะใช้พารามิเตอร์ที่มีอยู่แล้ว ตอนใช้ครั้งแรกข้อมูลจะถูกโหลดเข้ามา ซึ่งขนาดไฟล์จะใหญ่มาก ยิ่งพารามิเตอร์เยอะก็ยิ่งใหญ่
ครั้งนี้จะลองเอาแบบจำลองที่ชื่อ resnet18 มาใช้ดูเป็นตัวอย่าง
resnet เป็นแบบจำลองสำหรับวิเคราะห์รูปภาพ คิดค้นโดย เหอ ไข่หมิง (何恺明, Hé Kǎimíng) คนเดียวกับที่คิดเรื่องค่าตั้งต้นแบบเหอ (รายละเอียด https://phyblas.hinaboshi.com/umaki13)
resnet มีหลายแบบ เช่น resnet18, resnet34, resnet50, resnet101, resnet152 โดยตัวเลขข้างหลังแสดงถึงจำนวนชั้น ยิ่งลึกก็ยิ่งทำงานได้ดี แต่พารามิเตอร์ก็จะมีมากและยิ่งต้องใช้เวลาฝึกนานมาก และกินหน่วยความจำมาก
ในที่นี้จะลองแค่ resnet18 ซึ่งเป็นแบบที่เล็กที่สุด ฝึกเร็วที่สุด ถึงอย่างนั้นก็ยังต้องใช้เวลานานพอสมควร
ลองดูโครงสร้างของ resnet18
from torchvision.models import resnet18
print(resnet18())ได้
...
...(ด้านบนยาวมากขอละไว้)
...
(avgpool): AvgPool2d(kernel_size=7, stride=1, padding=0)
(fc): Linear(in_features=512, out_features=1000, bias=True)
)โครงสร้างของ resnet มีความซับซ้อนเล็กน้อย ไม่ได้แค่ต่อเป็นชั้นๆตรงไปตรงมาแต่มีการสร้างส่วนที่เรียกว่า shortcut ระหว่างบล็อกย่อย
รายละเอียดจะขอละไว้ แต่ส่วนที่สำคัญก็คือ จะเห็นว่าชั้นสุดท้ายชื่อ fc เป็นชั้นคำนวณเชิงเส้น โดยทั่วไปเวลาใช้งานแบบจำลองนี้เราจะแทนที่แค่ชั้นนี้ด้วยชั้นใหม่ที่มีค่าขาออกเป็นแบบที่เราต้องการ
การใช้แบบจำลองอันนี้มีข้อกำหนดอยู่ว่า
- ใช้กับภาพขนาด 224×224
- ภาพต้องนอร์มาไลซ์โดยใช้ค่าเฉลี่ย=(0.485,0.456,0.406) ส่วนเบี่ยงเบนมาตรฐาน=(0.229,0.224,0.225)
อาจเขียนแบบจำลองใหม่สำหรับจำแนกประเภทข้อมูลภาพโดยใช้ resnet18 เป็นฐานได้แบบนี้
import torch
from torchvision.models import resnet18
import time
ha_entropy = torch.nn.CrossEntropyLoss()
class PrasatResnet18(torch.nn.Sequential):
def __init__(self,n_klum,eta=0.001,aothifueklaeo=1,fuekthangmot=1,gpu=1):
self.fuekthangmot = fuekthangmot
rn = resnet18(aothifueklaeo)
if(not fuekthangmot):
for p in rn.parameters():
p.requires_grad = False
rn.eval()
rn.fc = torch.nn.Linear(512,n_klum)
super(PrasatResnet18,self).__init__(rn)
if(gpu):
self.dev = torch.device('cuda')
self.cuda()
else:
self.dev = torch.device('cpu')
self.opt = torch.optim.Adam(rn.parameters(),lr=eta)
def rianru(self,rup_fuek,rup_truat,n_thamsam=500,ro=10):
self.khanaen = []
khanaen_sungsut = 0
t_roem = time.time()
for o in range(n_thamsam):
if(self.fuekthangmot):
self.train()
for i,(Xb,zb) in enumerate(rup_fuek):
a = self(Xb.to(self.dev))
J = ha_entropy(a,zb.to(self.dev))
J.backward()
self.opt.step()
self.opt.zero_grad()
self.eval()
khanaen = []
for Xb,zb in rup_truat:
khanaen.append(self.thamnai_(Xb.to(self.dev)).cpu()==zb)
khanaen = torch.cat(khanaen).numpy().mean()
self.khanaen.append(khanaen)
print('%d ครั้งผ่านไป ใช้เวลาไป %.1f นาที ทำนายแม่น %.4f'%(o+1,(time.time()-t_roem)/60,khanaen))
if(khanaen>khanaen_sungsut):
khanaen_sungsut = khanaen
maiphoem = 0
else:
maiphoem += 1
if(ro>0 and maiphoem>=ro):
break
def thamnai_(self,X):
return self(X).argmax(1)fueklaeo เป็นตัวกำหนดว่าจะฝึกแบบจำลองใหม่หรือไม่ ถ้าเป็น 0 จะฝึกใหม่ทั้งหมด ถ้าเป็น 1 จะฝึกใหม่แค่ชั้นสุดท้าย (fc)
ในที่นี้ได้ทำตัวเลือกไว้ ๒ ตัว คือ
aothifueklaeo ถ้าเลือกเป็น 1 คือดึงเอาค่าพารามิเตอร์ที่ผ่านการฝึกแล้วมาใช้ ถ้าเป็น 0 คือฝึกใหม่จากค่าตั้งต้น
fuekthangmot ถ้าเลือกเป็น 1 คือเวลาฝึกให้มีการปรับพารามิเตอร์ของทุกตัว ถ้าเป็น 0 จะปรับแค่ชั้นสุดท้าย (fc) ที่เราใส่แก้เข้าไป
หากเลือก fuekthangmot=1 จะทำการตั้งให้พารามิเตอร์ทุกตัวเป็น requires_grad = False เพื่อจะได้ไม่มีการฝึกใหม่เพื่อปรับพารามิเตอร์
นอกจากนี้เนื่องจากภายในมีชั้นแบตช์นอร์มอยู่ด้วย แต่เพราะไม่มีการฝึกส่วนนี้แล้วดังนั้นต้องสั่ง .eval()
ชั้น fc ในที่นี้ถูกแทนที่ดวย Linear ที่มีขนาดขาออกเท่ากับจำนวนที่เรากำหนดเอง (n_klum)
ต่อมาลองนำมาใช้ทดสอบกับข้อมูล CIFAR10 ดู
เนื่องจากแบบจำลองนี้ใช้กับขนาด 224 แต่ภาพ CIFAR มีขนาดแค่ 32 ดังนั้นต้องทำการปรับขยายขนาด
และเนื่องจากแบบจำลองขนาดใหญ่ กินพื้นที่หน่วยความจำมาก ขนาดมินิแบตช์จึงไม่สามารถใหญ่มากได้ ในที่นี้จึงตั้งให้ n_batch=32 ถ้าใหญ่ไปหน่วยความจำของ GPU จะมีที่ไม่พอ
ลองแยกทำ ๓ กรณีเพื่อเปรียบเทียบ
- ใช้พารามิเตอร์ที่ฝึกมาแล้ว ฝึกใหม่แค่ชั้น fc
- ใช้พารามิเตอร์ที่ฝึกมาแล้ว และฝึกต่อ
- ฝึกใหม่ทั้งหมด
เริ่มจากลองแบบที่ใช้พารามิเตอร์ที่ฝึกมาแล้ว แต่ฝึกใหม่แค่ชั้น fc
import matplotlib.pyplot as plt
from torch.utils.data import DataLoader as Dalo
import torchvision.datasets as ds
import torchvision.transforms as tf
folder_cifar10 = 'pytorchdata/cifar'
tran = tf.Compose([
tf.Resize(224),
tf.RandomHorizontalFlip(),
tf.ToTensor(),
tf.Normalize((0.485,0.456,0.406),(0.229,0.224,0.225))])
rup_fuek = ds.CIFAR10(folder_cifar10,transform=tran,train=1,download=1)
rup_fuek = Dalo(rup_fuek,batch_size=32,shuffle=True)
tran = tf.Compose([
tf.Resize(224),
tf.ToTensor(),
tf.Normalize((0.485,0.456,0.406),(0.229,0.224,0.225))])
rup_truat = ds.CIFAR10(folder_cifar10,transform=tran,train=0)
rup_truat = Dalo(rup_truat,batch_size=32)
prasat = PrasatResnet18(10,eta=0.001,aothifueklaeo=1,fuekthangmot=0,gpu=1)
prasat.rianru(rup_fuek,rup_truat,ro=10)
torch.save(prasat.state_dict(),'resnet18_cifar_param_.pkl')
prasat.load_state_dict(torch.load('resnet18_cifar_param_.pkl'))
plt.plot(prasat.khanaen)
plt.savefig('resnet18_cifar_.png')
plt.show()ผลที่ได้คือความแม่นสูงสุดถึง 87%
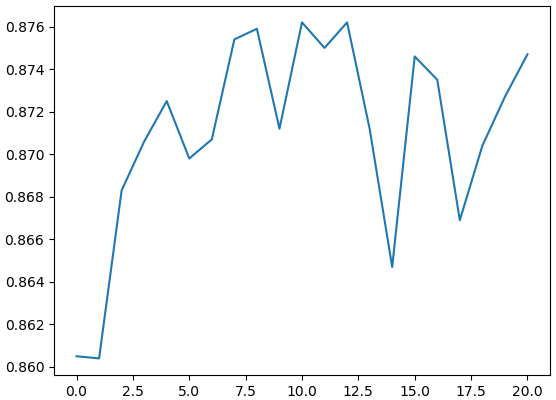
จากนั้นเปลี่ยนเป็นแบบฝึกทั้งหมดหมดทุกชั้น
prasat = PrasatResnet18(10,eta=0.001,aothifueklaeo=1,fuekthangmot=1,gpu=1)ผลที่ได้ ได้คะแนนสูงสุดถึงกว่า 92% สูงขึ้นยิ่งกว่าตอนฝึกใหม่แค่ชั้นเดียว
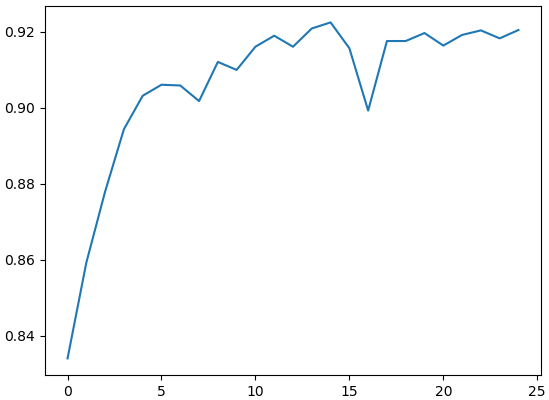
เพียงแต่ระยะเวลาที่ใช้ในการฝึกแต่ละรอบจะนานกว่ามาก เพราะต้องมีการคำนวณแพร่ย้อนกลับจนถึงชั้นแรกสุด
ถ้าไม่ต้องปรับพารามิเตอร์อะไรจะแค่คำนวณไปข้างหน้า และโดยทั่วไปการแพร่ย้อนกลับจะใช้เวลามากกว่าการคำนวณไปข้างหน้า ดังนั้นระยะเวลาโดยรวมจึงต่างกันเกินสองเท่า
สุดท้าย ลองทำการฝึกตั้งแต่เริ่มใหม่
prasat = PrasatResnet18(10,eta=0.001,aothifueklaeo=0,fuekthangmot=1,gpu=1)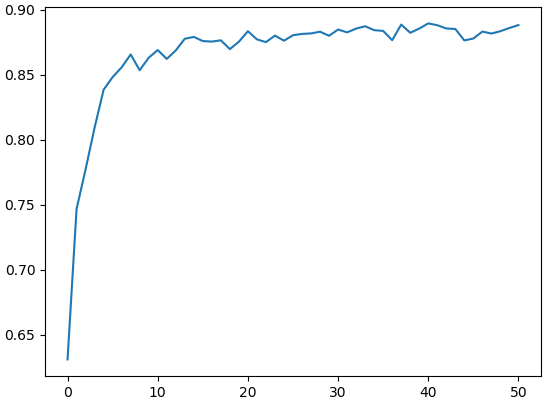
ผลที่ได้คะแนนสู้ตอนที่ใช้ค่าที่ฝึกมาแล้วเป็นค่าเริ่มต้นไม่ได้ แถมตอนช่วงเริ่มจะเริ่มจากคะแนนต่ำกว่าเพราะต้องเริ่มฝึกใหม่หมด จำนวนรอบที่ต้องฝึกจึงมากกว่า
ในบทที่ ๑๔ ได้ลองใช้แบบจำลองที่ตัวเองสร้างเองแล้วทายได้แม่น 83% แต่พอลองใช้ resnet18 ผลที่ได้ออกมาแม่นขึ้นกว่าเดิมมาก จึงแสดงให้เห็นถึงประสิทธิภาพของแบบจำลองนี้เป็นอย่างดี และยังแสดงให้เห็นว่าต่อให้ฝึกใหม่แค่ชั้นสุดท้ายชั้นเดียว ผลก็ออกมาเป็นที่น่าพอใจได้มากพอ
แบบจำลองต้องสร้างแบบไหนถึงจะดีนั้นเป็นอะไรที่บอกได้ยาก ส่วนใหญ่มักเป็นเชิงประสบการณ์มากกว่าทฤษฎี ต้องทดลองใช้จริงจึงจะรู้แน่ชัด การใช้แบบที่คนสร้างมาก่อนแล้วให้ผลได้ดีจึงเป็นแนวทางหนึ่งที่ดี
-----------------------------------------
囧囧囧囧囧囧囧囧囧囧囧囧囧囧囧囧囧囧囧囧囧囧囧囧囧
หมวดหมู่
-- คอมพิวเตอร์ >> ปัญญาประดิษฐ์ >> โครงข่ายประสาทเทียม-- คอมพิวเตอร์ >> เขียนโปรแกรม >> python >> pytorch