จัดการข้อมูลด้วย pandas เบื้องต้น บทที่ ๒๑: การจัดการกับไฟล์ excel (.xlsx, .xls)
เขียนเมื่อ 2021/04/15 20:25
แก้ไขล่าสุด 2021/09/28 16:42
pandas มีฟังก์ชันสำหรับอ่านข้อมูลจากไฟล์เอ็กซ์เซล (สกุล .xlsx หรือ .xls) มาเป็นเดตาเฟรม และมีเมธอดสำหรับเอาข้อมูลจากเดตาเฟรมบันทึกลงเป็นไฟล์เอ็กซ์เซล
เอ็กซ์เซลเองก็เป็นรูปแบบการเก็บข้อมูลในรูปแบบตารางที่ได้ใช้บ่อยมากอยู่อันหนึ่ง
ที่จริงไฟล์เอ็กซ์เซลสามารถแปลงเป็น .csv ได้ง่ายด้วยโปรแกรมไมโครซอฟต์เอ็กซ์เซล ถ้าแปลงแล้วค่อยใช้ pandas อ่านไฟล์ .csv ที่ได้นั้นอีกทีก็ได้เช่นกัน
แต่เมื่อสามารถอ่านเขียนไฟล์เอ็กซ์เซลได้โดยตรง ไม่ต้องทำผ่าน .csv ก็ย่อมสะดวกกว่า
ไพธอนมีมอดูลที่ใช้จัดการกับไฟล์เอ็กซ์เซลอยู่แล้ว ซึ่งภายใน pandas จะไปเรียกใช้มอดูลเหล่านั้นมาใช้อีกที ดังนั้นจึงจำเป็นต้องติดตั้งก่อนจึงจะใช้ความสามารถตรงนี้ได้
ในการอ่านไฟล์จะทำผ่านมอดูล xlrd ส่วนในการเขียนไฟล์จะใช้มอดูล openpyxl
ตอนที่ติดตั้ง pandas มอดูลเหล่านี้ไม่ได้ถูกติดตั้งให้ด้วยโดยอัตโนมัติ ต้องติดตั้งเพิ่มอีกที ซึ่งก็จัดการได้ง่ายโดยใช้ pip หรือ conda
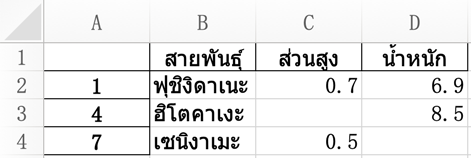
เมื่อมีเดตาเฟรมอยู่ สามารถแปลงเป็นไฟล์เอ็กซ์เซลได้ด้วยเมธอด .to_excel
ตัวอย่างเช่น

จะได้
หากต้องการกำหนดชื่อหน้าก็ใส่ที่คีย์เวิร์ด sheet_name ถ้าไม่ใส่จะได้ชื่อ sheet_name='Sheet1'
ช่องที่ไม่มีข้อมูลจะถูกเว้นว่างไว้ แต่ถ้าหากต้องการให้ใส่ความความอะไรลงไปแทนการไม่มีข้อมูลก็กำหนดที่คีย์เวิร์ด na_rep
ตัวอย่างเช่น
ได้

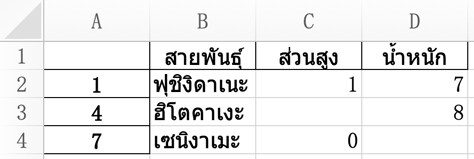
สำหรับข้อมูลที่เป็นเลขทศนิยม อาจกำหนดรูปแบบการเขียนด้วยคีย์เวิร์ด float_format
เช่น ให้ปัดเศษเลขทศนิยมไปหมด
ได้
หากต้องการข้อมูลแค่บางคอลัมน์ก็กำหนดที่คีย์เวิร์ด columns เช่น
ได้

หากไม่ต้องการชื่อคอลัมน์ ให้ใส่ header=False เช่น
ได้

หากไม่ต้องการชื่อดัชนี ให้ใส่ index=False
ได้
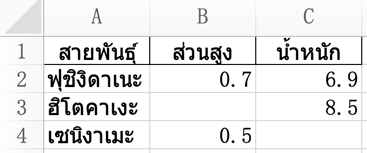
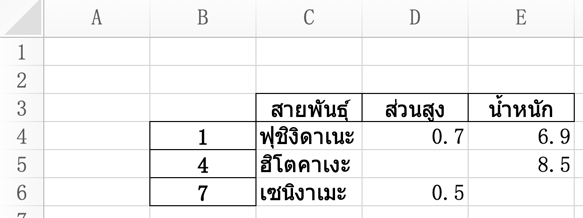
หากต้องการกำหนดตำแหน่งแถวและคอลัมน์ที่เริ่มต้นวางให้ใส่ที่คีย์เวิร์ด startrow และ startcol
ได้
การใช้ .to_excel โดยใส่แค่ชื่อไฟล์ที่ต้องการบันทึกลงไปเลยนั้นจะใช้เขียนได้แค่ไฟล์ละหน้าเดียวเท่านั้น
หากต้องการเขียนหลายหลายหน้าพร้อมกันอาจทำได้โดยใช้ ExcelWriter ช่วย
วิธีการใช้นั้นคือใช้กับ with แล้วใส่ ตัว pd.ExcelWriter ลงไปแทนที่ชื่อไฟล์
เช่น
แต่ตัวอย่างข้างต้นนี้เป็นการเขียนแค่หน้าเดียว ที่จริงจึงไม่จำเป็นต้องใช้ pd.ExcelWriter แบบนี้ใส่แค่ชื่อไฟล์เฉยๆก็ได้ผลเหมือนกัน
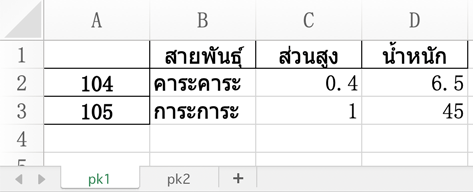
ตัวอย่างการสร้างไฟล์ที่มี ๒ หน้า เช่น
ได้
นอกจากนี้ ExcelWriter ยังใช้เพื่อเขียนหน้าใหม่ลงในไฟล์ที่มีอยู่แล้วได้ โดยการเปิดด้วย mode='a'
เช่นลองเขียนทับไฟล์จากตัวอย่างที่แล้ว


ได้

ส่วนการอ่านข้อมูลจากไฟล์เอ็กซ์เซลทำได้โดยใช้ฟังก์ชัน pd.read_excel
ตัวอย่างเช่น ลองเปิดไฟล์เอ็กซ์เซลที่ได้จากตัวอย่างที่แล้วขึ้นมา
ได้
หากไม่ได้กำหนดว่าจะเอาหน้าไหน จะเป็นการอ่านข้อมูลหน้าแรกสุดหน้าเดียว แต่หากกำหนด sheet_name ก็จะอ่านหน้าที่กำหนด โดยจะใส่เป็นลำดับหน้าก็ได้ (โดยเริ่มไล่จากหน้าแรกคือ 0) หรือใส่ชื่อหน้าก็ได้
เช่นอ่านหน้าที่ ๒ ซึ่งมีชื่อหน้าว่า pk2
ได้
สามารถอ่านหลายหน้าพร้อมกันได้ โดยผลที่ได้จะออกมาในรูปดิกชันนารีของเดตาเฟรม
ได้
เช่น
ได้
เช่นเช่นเดียวกันกับใน .read_csv สามารถกำหนดว่าจะเอาแค่บางคอลัมน์ได้โดยใส่ usecols
ได้
นอกจากนี้คีย์เวิร์ดอื่นๆเช่น skiprows, nrows, na_values, keep_default_na, dtype พวกนี้สามารถใช้ได้เช่นเดียวกับใน df.read_csv อ่านรายละเอียดได้ในบทที่ ๓
ตัวอย่าง
ได้
อ้างอิง
เอ็กซ์เซลเองก็เป็นรูปแบบการเก็บข้อมูลในรูปแบบตารางที่ได้ใช้บ่อยมากอยู่อันหนึ่ง
ที่จริงไฟล์เอ็กซ์เซลสามารถแปลงเป็น .csv ได้ง่ายด้วยโปรแกรมไมโครซอฟต์เอ็กซ์เซล ถ้าแปลงแล้วค่อยใช้ pandas อ่านไฟล์ .csv ที่ได้นั้นอีกทีก็ได้เช่นกัน
แต่เมื่อสามารถอ่านเขียนไฟล์เอ็กซ์เซลได้โดยตรง ไม่ต้องทำผ่าน .csv ก็ย่อมสะดวกกว่า
ไพธอนมีมอดูลที่ใช้จัดการกับไฟล์เอ็กซ์เซลอยู่แล้ว ซึ่งภายใน pandas จะไปเรียกใช้มอดูลเหล่านั้นมาใช้อีกที ดังนั้นจึงจำเป็นต้องติดตั้งก่อนจึงจะใช้ความสามารถตรงนี้ได้
ในการอ่านไฟล์จะทำผ่านมอดูล xlrd ส่วนในการเขียนไฟล์จะใช้มอดูล openpyxl
ตอนที่ติดตั้ง pandas มอดูลเหล่านี้ไม่ได้ถูกติดตั้งให้ด้วยโดยอัตโนมัติ ต้องติดตั้งเพิ่มอีกที ซึ่งก็จัดการได้ง่ายโดยใช้ pip หรือ conda
pip install openpyxl
pip install xlrd
pip install xlrd
เมื่อมีเดตาเฟรมอยู่ สามารถแปลงเป็นไฟล์เอ็กซ์เซลได้ด้วยเมธอด .to_excel
ตัวอย่างเช่น
import pandas as pd
df = pd.DataFrame([
['ฟุชิงิดาเนะ',0.7,6.9],
['ฮิโตคาเงะ',None,8.5],
['เซนิงาเมะ',0.5]],
columns=['สายพันธุ์','ส่วนสูง','น้ำหนัก'],
index=[1,4,7])
df.to_excel('pokemon.xlsx')จะได้
หากต้องการกำหนดชื่อหน้าก็ใส่ที่คีย์เวิร์ด sheet_name ถ้าไม่ใส่จะได้ชื่อ sheet_name='Sheet1'
ช่องที่ไม่มีข้อมูลจะถูกเว้นว่างไว้ แต่ถ้าหากต้องการให้ใส่ความความอะไรลงไปแทนการไม่มีข้อมูลก็กำหนดที่คีย์เวิร์ด na_rep
ตัวอย่างเช่น
df.to_excel('pokemon.xlsx',na_rep='ไม่มีข้อมูล')ได้
สำหรับข้อมูลที่เป็นเลขทศนิยม อาจกำหนดรูปแบบการเขียนด้วยคีย์เวิร์ด float_format
เช่น ให้ปัดเศษเลขทศนิยมไปหมด
df.to_excel('pokemon.xlsx',float_format='%.0f')ได้
หากต้องการข้อมูลแค่บางคอลัมน์ก็กำหนดที่คีย์เวิร์ด columns เช่น
df.to_excel('pokemon.xlsx',columns=['สายพันธุ์','ส่วนสูง'])ได้
หากไม่ต้องการชื่อคอลัมน์ ให้ใส่ header=False เช่น
df.to_excel('pokemon.xlsx',header=False)ได้
หากไม่ต้องการชื่อดัชนี ให้ใส่ index=False
df.to_excel('pokemon.xlsx',index=False)ได้
หากต้องการกำหนดตำแหน่งแถวและคอลัมน์ที่เริ่มต้นวางให้ใส่ที่คีย์เวิร์ด startrow และ startcol
df.to_excel('pokemon.xlsx',startrow=2,startcol=1)ได้
การใช้ .to_excel โดยใส่แค่ชื่อไฟล์ที่ต้องการบันทึกลงไปเลยนั้นจะใช้เขียนได้แค่ไฟล์ละหน้าเดียวเท่านั้น
หากต้องการเขียนหลายหลายหน้าพร้อมกันอาจทำได้โดยใช้ ExcelWriter ช่วย
วิธีการใช้นั้นคือใช้กับ with แล้วใส่ ตัว pd.ExcelWriter ลงไปแทนที่ชื่อไฟล์
เช่น
with pd.ExcelWriter('pokemon.xlsx') as ew:
df.to_excel(ew)แต่ตัวอย่างข้างต้นนี้เป็นการเขียนแค่หน้าเดียว ที่จริงจึงไม่จำเป็นต้องใช้ pd.ExcelWriter แบบนี้ใส่แค่ชื่อไฟล์เฉยๆก็ได้ผลเหมือนกัน
ตัวอย่างการสร้างไฟล์ที่มี ๒ หน้า เช่น
col = ['สายพันธุ์','ส่วนสูง','น้ำหนัก']
df1 = pd.DataFrame([
['คาระคาระ',0.4,6.5],
['การะการะ',1,45]],
columns=col,index=[104,105])
df2 = pd.DataFrame([
['ซาวามูลาร์',1.5,49.8],
['เอบิวาลาร์',1.4,50.2]],
columns=col,
index=[106,107])
with pd.ExcelWriter('pokemon.xlsx') as ew:
df1.to_excel(ew,sheet_name='pk1')
df2.to_excel(ew,sheet_name='pk2')ได้
นอกจากนี้ ExcelWriter ยังใช้เพื่อเขียนหน้าใหม่ลงในไฟล์ที่มีอยู่แล้วได้ โดยการเปิดด้วย mode='a'
เช่นลองเขียนทับไฟล์จากตัวอย่างที่แล้ว
df3 = pd.DataFrame([
['ไซฮอร์น',1,115],
['ไซดอน',1.9,120]],
columns=['สายพันธุ์','ส่วนสูง','น้ำหนัก'],
index=[111,112])
with pd.ExcelWriter('pokemon.xlsx',mode='a') as ew:
df3.to_excel(ew,sheet_name='pk3')ได้
ส่วนการอ่านข้อมูลจากไฟล์เอ็กซ์เซลทำได้โดยใช้ฟังก์ชัน pd.read_excel
ตัวอย่างเช่น ลองเปิดไฟล์เอ็กซ์เซลที่ได้จากตัวอย่างที่แล้วขึ้นมา
df = pd.read_excel('pokemon.xlsx')
print(df)ได้
Unnamed: 0 สายพันธุ์ ส่วนสูง น้ำหนัก
0 104 คาระคาระ 0.4 6.5
1 105 การะการะ 1.0 45.0หากไม่ได้กำหนดว่าจะเอาหน้าไหน จะเป็นการอ่านข้อมูลหน้าแรกสุดหน้าเดียว แต่หากกำหนด sheet_name ก็จะอ่านหน้าที่กำหนด โดยจะใส่เป็นลำดับหน้าก็ได้ (โดยเริ่มไล่จากหน้าแรกคือ 0) หรือใส่ชื่อหน้าก็ได้
เช่นอ่านหน้าที่ ๒ ซึ่งมีชื่อหน้าว่า pk2
df = pd.read_excel('pokemon.xlsx',sheet_name='pk2')
# หรือ df = pd.read_excel('pokemon.xlsx',sheet_name=1)
print(df)ได้
Unnamed: 0 สายพันธุ์ ส่วนสูง น้ำหนัก
0 106 ซาวามูลาร์ 1.5 49.8
1 107 เอบิวาลาร์ 1.4 50.2สามารถอ่านหลายหน้าพร้อมกันได้ โดยผลที่ได้จะออกมาในรูปดิกชันนารีของเดตาเฟรม
df = pd.read_excel('pokemon.xlsx',sheet_name=[0,'pk3'])
print(df)ได้
{0: Unnamed: 0 สายพันธุ์ ส่วนสูง น้ำหนัก
0 104 คาระคาระ 0.4 6.5
1 105 การะการะ 1.0 45.0, 'pk3': Unnamed: 0 สายพันธุ์ ส่วนสูง น้ำหนัก
0 111 ไซฮอร์น 1.0 115
1 112 ไซดอน 1.9 120}เช่น
df = pd.read_excel('pokemon.xlsx',index_col=0)
print(df)ได้
สายพันธุ์ ส่วนสูง น้ำหนัก
104 คาระคาระ 0.4 6.5
105 การะการะ 1.0 45.0เช่นเช่นเดียวกันกับใน .read_csv สามารถกำหนดว่าจะเอาแค่บางคอลัมน์ได้โดยใส่ usecols
df = pd.read_excel('pokemon.xlsx',usecols=[1,2,3])
print(df)ได้
สายพันธุ์ ส่วนสูง น้ำหนัก
0 คาระคาระ 0.4 6.5
1 การะการะ 1.0 45.0นอกจากนี้คีย์เวิร์ดอื่นๆเช่น skiprows, nrows, na_values, keep_default_na, dtype พวกนี้สามารถใช้ได้เช่นเดียวกับใน df.read_csv อ่านรายละเอียดได้ในบทที่ ๓
ตัวอย่าง
df1 = pd.read_excel('pokemon.xlsx',nrows=1)
df2 = pd.read_excel('pokemon.xlsx',skiprows=1)
print(df1)
print('---')
print(df2)ได้
Unnamed: 0 สายพันธุ์ ส่วนสูง น้ำหนัก
0 104 คาระคาระ 0.4 6.5
---
104 คาระคาระ 0.4 6.5
0 105 การะการะ 1 45อ้างอิง
https://qiita.com/yniji/items/2e80ace081c4b59bc327
https://qiita.com/7oosako/items/4314afc337ca5b4ee25b
https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.to_excel.html
https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.read_excel.html
https://qiita.com/7oosako/items/4314afc337ca5b4ee25b
https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.to_excel.html
https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.read_excel.html