สร้างข้อมูลกลุ่มรูปไข่ดาวเพื่อใช้ทดสอบการเรียนรู้ของเครื่อง
เขียนเมื่อ 2018/07/16 08:42
แก้ไขล่าสุด 2022/07/11 12:42
ก่อนหน้านี้เคยได้แนะนำการสร้างข้อมูลเป็นกลุ่มๆก้อนๆและพระจันทร์เสี้ยวเพื่อใช้ทดสอบแบบจำลองการเรียนรู้ของเครื่องไป
https://phyblas.hinaboshi.com/20161127
https://phyblas.hinaboshi.com/20171202
คราวนี้มาลองข้อมูลทดสอบอีกแบบ คือ make_circles เอาไว้สร้างข้อมูลที่มีการกระจายตัวเป็นวงสองวงซ้อนกันคล้ายไข่ดาว
ตัวอย่างการใช้ ถ้าใช้โดยไม่ได้ปรับแต่งอะไร ก็จะได้ ๑๐๐ จุด อยู่วงในและวงนอกอย่างเป็นระเบียบแบบนี้

ถ้าใส่ตัวเลือกเพิ่มเติมเข้าไปสิ่งที่สามารถปรับแต่งได้มีดังนี้
ลองวาดภาพเทียบกรณีที่ค่า factor และ noise ต่างกันออกไปเทียบกันดู
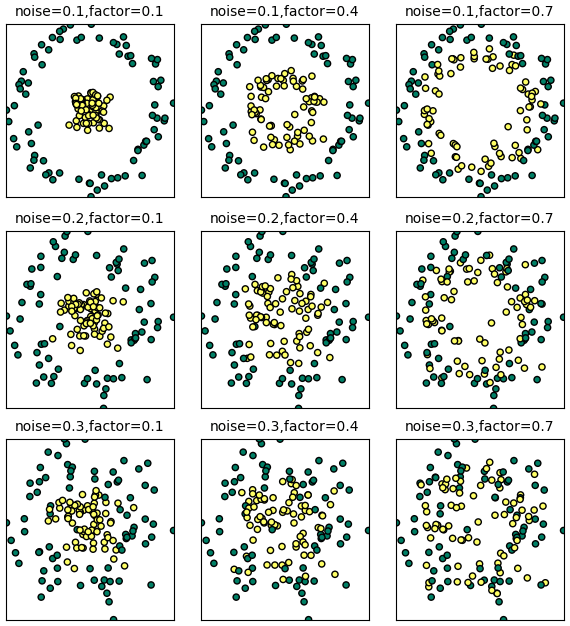
ข้อมูลลักษณะแบบนี้เหมาะเอาไว้ใช้เป็นตัวอย่างเรื่องการใช้ลูกเล่นเคอร์เนล (kernel trick) หรือการแบ่งด้วยวิธีการที่ไม่เป็นเชิงเส้น
ต่อมา ลองสร้างชุดข้อมูลขึ้นมาแล้วทดสอบการแบ่งกลุ่มข้อมูลนี้ด้วยแบบจำลองการแบ่งกลุ่มที่ต่างกัน ๔ แบบดู
- การถดถอยโลจิสติก (逻辑回归, logistic regression)
- วิธีการเพื่อนบ้านใกล้สุด k ตัว (K-近邻算法, k-nearest neighbor, KNN)
- เครื่องเวกเตอร์ค้ำยัน (支持向量机, support vector machine, SVM)
- ป่าสุ่ม (随机森林, random forest)
ทั้งหมดนี้ก็ใช้ sklearn ทำทั้งหมด
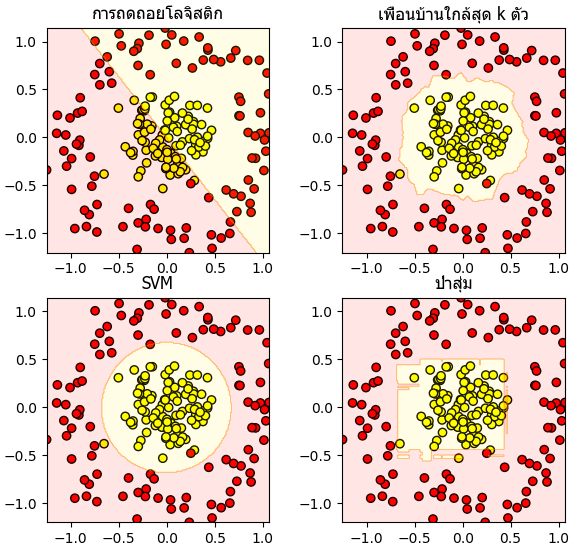
จะเห็นได้ว่าแต่ละวิธีมีลักษณะการแบ่งที่ต่างกันออกไป
- การถดถอยโลจิสติกจะแบ่งได้แต่เส้นตรงเท่านั้น จึงไม่สามารถใช้ประโยชน์ในกรณีนี้ได้เลย
- เพื่อนบ้านใกล้สุด k ตัวจะแบ่งได้เส้นหยึกหยักไม่เรียบ
- SVM เมื่อใช้เคอร์เนล RBF จึงสามารถแบ่งเป็นเส้นโค้งเรียบ ดูแล้วแบ่งได้เป็นธรรมชาติที่สุด
- ป่าสุ่ม จะได้เส้นแบ่งตามแนวตั้งแนวนอนเป็นก้อนๆไม่สม่ำเสมอ
https://phyblas.hinaboshi.com/20161127
https://phyblas.hinaboshi.com/20171202
คราวนี้มาลองข้อมูลทดสอบอีกแบบ คือ make_circles เอาไว้สร้างข้อมูลที่มีการกระจายตัวเป็นวงสองวงซ้อนกันคล้ายไข่ดาว
ตัวอย่างการใช้ ถ้าใช้โดยไม่ได้ปรับแต่งอะไร ก็จะได้ ๑๐๐ จุด อยู่วงในและวงนอกอย่างเป็นระเบียบแบบนี้
import matplotlib.pyplot as plt
from sklearn import datasets
X,z = datasets.make_circles()
x,y = X.T
plt.axes(aspect=1)
plt.scatter(x,y,c=z,cmap='spring')
plt.show()ถ้าใส่ตัวเลือกเพิ่มเติมเข้าไปสิ่งที่สามารถปรับแต่งได้มีดังนี้
| ความหมาย | ค่าตั้งต้น | |
|---|---|---|
| n_samples | จำนวนข้อมูลทั้งหมด | 100 |
| shuffle | จะสุ่มการจัดเรียงแต่ละกลุ่มหรือไม่ | True |
| noise | ขนาดของคลื่นรบกวน | 0 |
| factor | อัตราส่วนขนาดวงในต่อวงนอก | 0.8 |
| random_state | หมายเลขชุดของการสุ่ม | None |
ลองวาดภาพเทียบกรณีที่ค่า factor และ noise ต่างกันออกไปเทียบกันดู
plt.figure(figsize=[6,7])
for i,n in enumerate([0.1,0.2,0.3]):
for j,f in enumerate([0.1,0.4,0.7]):
X,z = datasets.make_circles(n_samples=150,noise=n,factor=f,random_state=111)
x,y = X.T
plt.subplot2grid((3,3),(i,j),xlim=[x.min(),x.max()],ylim=[y.min(),y.max()],xticks=[],yticks=[],aspect=1)
plt.scatter(x,y,s=20,c=z,cmap='summer',edgecolor='k')
plt.title('noise=%.1f,factor=%.1f'%(n,f),size=10)
plt.tight_layout()
plt.show()ข้อมูลลักษณะแบบนี้เหมาะเอาไว้ใช้เป็นตัวอย่างเรื่องการใช้ลูกเล่นเคอร์เนล (kernel trick) หรือการแบ่งด้วยวิธีการที่ไม่เป็นเชิงเส้น
ต่อมา ลองสร้างชุดข้อมูลขึ้นมาแล้วทดสอบการแบ่งกลุ่มข้อมูลนี้ด้วยแบบจำลองการแบ่งกลุ่มที่ต่างกัน ๔ แบบดู
- การถดถอยโลจิสติก (逻辑回归, logistic regression)
- วิธีการเพื่อนบ้านใกล้สุด k ตัว (K-近邻算法, k-nearest neighbor, KNN)
- เครื่องเวกเตอร์ค้ำยัน (支持向量机, support vector machine, SVM)
- ป่าสุ่ม (随机森林, random forest)
ทั้งหมดนี้ก็ใช้ sklearn ทำทั้งหมด
import numpy as np
from sklearn.linear_model import LogisticRegression as Lori
from sklearn.neighbors import KNeighborsClassifier as Knn
from sklearn.svm import SVC
from sklearn.ensemble import RandomForestClassifier as Rafo
X,z = datasets.make_circles(n_samples=200,noise=0.15,factor=0.25)
x,y = X.T
model = [Lori(),Knn(),SVC(),Rafo()]
chue = [u'การถดถอยโลจิสติก',u'เพื่อนบ้านใกล้สุด k ตัว',u'SVM',u'ป่าสุ่ม']
mx,my = np.meshgrid(np.linspace(x.min(),x.max(),200),np.linspace(y.min(),y.max(),200))
mX = np.array([mx.ravel(),my.ravel()]).T
plt.figure(figsize=[7,7])
for i,m in enumerate(model):
m.fit(X,z)
mz = m.predict(mX).reshape(200,200)
plt.subplot(221+i,xlim=[x.min(),x.max()],ylim=[y.min(),y.max()],aspect=1)
plt.scatter(x,y,c=z,edgecolor='k',cmap='autumn')
plt.contourf(mx,my,mz,alpha=0.1,cmap='autumn')
plt.title(chue[i],family='Tahoma')
plt.show()จะเห็นได้ว่าแต่ละวิธีมีลักษณะการแบ่งที่ต่างกันออกไป
- การถดถอยโลจิสติกจะแบ่งได้แต่เส้นตรงเท่านั้น จึงไม่สามารถใช้ประโยชน์ในกรณีนี้ได้เลย
- เพื่อนบ้านใกล้สุด k ตัวจะแบ่งได้เส้นหยึกหยักไม่เรียบ
- SVM เมื่อใช้เคอร์เนล RBF จึงสามารถแบ่งเป็นเส้นโค้งเรียบ ดูแล้วแบ่งได้เป็นธรรมชาติที่สุด
- ป่าสุ่ม จะได้เส้นแบ่งตามแนวตั้งแนวนอนเป็นก้อนๆไม่สม่ำเสมอ
-----------------------------------------
囧囧囧囧囧囧囧囧囧囧囧囧囧囧囧囧囧囧囧囧囧囧囧囧囧
หมวดหมู่
-- คอมพิวเตอร์ >> ปัญญาประดิษฐ์-- คอมพิวเตอร์ >> เขียนโปรแกรม >> python >> numpy
-- คอมพิวเตอร์ >> เขียนโปรแกรม >> python >> matplotlib
-- คอมพิวเตอร์ >> เขียนโปรแกรม >> python >> sklearn