การใช้ PyPDF2 เพื่อตัดต่อและทำอะไรหลายๆอย่างกับไฟล์ pdf
เขียนเมื่อ 2023/03/02 08:56
แก้ไขล่าสุด 2024/03/27 16:50
มอดูล PyPDF2 ในไพธอนมีไว้สำหรับจัดการกับไฟล์ pdf โดยทำอะไรได้หลายๆอย่าง เช่นดึงเอาบางหน้าในไฟล์ หรือเอา pdf หลายไฟล์มาผสมเป็นไฟล์เดียว หรือแยกไฟล์เดียวเป็นหลายไฟล์ หรือทำการแก้ตัวไฟล์ในส่วนภาพรวมที่ไม่ใช่การเข้าไปแก้องค์ประกอบโดยละเอียด เช่นข้อมูล metadata เอาหน้ามาซ้อนทับกัน ทำเป็นลายน้ำ หรือจับหน้ากระดาษมาหมุนหรือย่อขยายขนาด
เพียงแต่ว่างานละเอียดอย่างเช่นการเข้าไปเติมหรือลบหรือย้ายข้อความหรือรูปภาพลงในหน้าของ pdf นั้นจะเกินขอบเขตความสามารถของ PyPDF2
การสร้างไฟล์ pdf ขึ้นมาจากศูนย์ หรือแปลงจากไฟล์ต่างหรือแปลง pdf ไปเป็นไฟล์ต่างๆก็ไม่สามารถทำได้เช่นกัน
แม้จะใช้ทำงานละเอียดลึกๆไม่ได้ แต่สิ่งที่ PyPDF2 ทำได้นั้นเป็นอะไรที่มักใช้งานบ่อย อีกทั้งใช้งานง่ายด้วย จึงถูกใช้อย่างกว้างขวาง
บทความนี้จะอธิบายการใช้ PyPDF2 ตั้งแต่เบื้องต้น
การติดตั้งและใช้งาน
PyPDF2 เป็นมอดูลที่ไม่ได้มีอยู่ในไพธอนตั้งแต่ต้น ต้องติดตั้งเพิ่ม ซึ่งก็สามารถติดตั้งได้ง่ายโดยใช้ pip
pip install PyPDF2ส่วนในการใช้งานนั้นโดยทั่วไปแค่เริ่มจากเรียกใช้ตัวมอดูลโดยพิมพ์
import PyPDF2เท่านี้ก็สามารถใช้งานทุกสิ่งทุกอย่างภายในมอดูลนี้ได้แล้ว ไม่ได้มีความจำเป็นจะต้องมา import แยกส่วนให้ยุ่งยาก ถือว่าใช้งานได้ง่าย
การดูข้อมูลต่างๆของไฟล์ pdf
ขอเริ่มที่การเปิดไฟล์ pdf ขึ้นมาเพื่อดูข้อมูลต่างๆคร่าวๆภายในนั้น
การอ่านไฟล์ pdf ขึ้นมาทำได้โดยสร้างออบเจ็กต์
PyPDF2.PdfReader คือออบเจ็กต์ตัวอ่านข้อมูลไฟล์เช่นมีไฟล์ชื่อ
รายการอาหาร.pdf อยู่ เราอาจใช้ PyPDF2 เพื่อเปิดขึ้นมาอ่านดูข้อมูลพื้นฐานต่างๆได้ดังนี้import PyPDF2
pdf = PyPDF2.PdfReader('รายการอาหาร.pdf')
print(len(pdf.pages)) # ดูจำนวนหน้า
print(pdf.metadata) # ดู metadata
print(pdf.is_encrypted) # ดูว่าไฟล์นี้ต้องป้อนรหัสผ่านเพื่อเปิดหรือไม่การเข้าถึงแต่ละหน้าภายใน pdf
ไฟล์ pdf นั้นจะประกอบด้วยหน้ากระดาษหลายๆหน้า เวลาที่จัดการไฟล์ pdf เรามักจะต้องจัดการแยกเป็นหน้าๆ ดังนั้นก่อนจะทำอะไรต้องเริ่มจากเข้าถึงออบเจ็กต์ตัวหน้ากระดาษของหน้านั้นๆ
วิธีการเข้าถึงนั้นทำได้โดยใช้
.pages[เลขหน้า] โดยที่เลขหน้าในที่นี้จะเริ่มไล่จาก 0 ดังนั้นหน้าแรกคือเลข 0 หน้าที่สองเป็นเลข 1 ตามลำดับ เช่นถ้าต้องการเอาหน้าแรกก็อาจเขียนเป็นna = pdf.pages[0]PageObjectprint(type(pdf.pages[0])) # ได้ PyPDF2._page.PageObjectหากเอาออบเจ็กต์ชนิดนี้มาสั่ง print ก็จะแสดงโครงสร้างส่วนประกอบภายในหน้าเป็นโค้ดให้เห็น
เช่น ขอยกตัวอย่างโดยลองสร้าง pdf หน้าเปล่าๆขึ้นมาจากไฟล์ไมโครซอฟต์เวิร์ดด้วยมอดูล docx2pdf (รายละเอียดอ่านได้ใน https://phyblas.hinaboshi.com/20230207) โดยไม่ได้ใส่ข้อความหรือรูปภาพอะไรลงไปเลย แล้วเอามาเปิดด้วย PyPDF2 ดู
pdf = PyPDF2.PdfReader('หน้าเปล่า.pdf')
print(pdf.pages[0])ก็จะขึ้นโครงสร้างแบบนี้มาให้เห็น
{'/Type': '/Page',
'/Parent': {'/Type': '/Pages',
'/Count': 1,
'/Kids': [IndirectObject(3, 0, 1951717119360)]},
'/Resources': {'/Font': {'/F1': {'/Type': '/Font',
'/Subtype': '/TrueType',
'/Name': '/F1',
'/BaseFont': '/BCDEEE+YuMincho-Regular',
'/Encoding': '/WinAnsiEncoding',
'/FontDescriptor': {'/Type': '/FontDescriptor',
'/FontName': '/BCDEEE+YuMincho-Regular',
'/Flags': 32,
'/ItalicAngle': 0,
'/Ascent': 880,
'/Descent': -120,
'/CapHeight': 880,
'/AvgWidth': 969,
'/MaxWidth': 2243,
'/FontWeight': 400,
'/XHeight': 250,
'/Leading': 315,
'/StemV': 96,
'/FontBBox': [-1000, -120, 1243, 880],
'/FontFile2': {'/Filter': '/FlateDecode', '/Length1': 170008}},
'/FirstChar': 32,
'/LastChar': 32,
'/Widths': [260]}},
'/ExtGState': {'/GS7': {'/Type': '/ExtGState', '/BM': '/Normal', '/ca': 1},
'/GS8': {'/Type': '/ExtGState', '/BM': '/Normal', '/CA': 1}},
'/ProcSet': ['/PDF', '/Text', '/ImageB', '/ImageC', '/ImageI']},
'/MediaBox': [0, 0, 595.32, 841.92],
'/Contents': {'/Filter': '/FlateDecode'},
'/Group': {'/Type': '/Group', '/S': '/Transparency', '/CS': '/DeviceRGB'},
'/Tabs': '/S',
'/StructParents': 0}ซึ่งตรงนี้จะเห็นว่าแม้จะเป็นหน้าเปล่าก็มีอะไรขนาดนี้แล้ว ดูแล้วค่อนข้างซับซ้อน มีอะไรมากมาย ขอไม่อธิบายในรายละเอียด
ที่สามารถจะทำได้ง่ายๆก็เช่นการดึงข้อความภายในหน้ากระดาษ หากต้องการดึงเอาข้อความที่อยู่ภายในหน้าก็สามารถทำได้โดยเมธอด
.extract_text()pdf = PyPDF2.PdfReader('รายการอาหาร.pdf')
na = pdf.pages[0]
print(na.extract_text()) # ได้ข้อความในหน้านั้นมาหรือหากอยากรู้ว่าหน้ากระดาษนี้มีขนาดกว้างหรือสูงเท่าไหร่ก็ดูได้ที่แอตทริบิวต์
.mediabox.width และ .mediabox.heightpdf = PyPDF2.PdfReader('รายการอาหาร.pdf')
na = pdf.pages[0]
print(na.mediabox.width) # ความกว้างหน้า
print(na.mediabox.height) # ความสูงหน้าการดึงเอาเฉพาะบางหน้าของ pdf
ไฟล์ pdf ที่เปิดขึ้นมาไว้ในออบเจ็กต์
PyPDF2.PdfReader นั้นทำได้แค่ดูข้อมูล แต่ไม่สามารถไปแก้ไขอะไรได้ แต่เราสามารถนำข้อมูลในแต่ละหน้าของมันมาใช้เพื่อสร้างไฟล์ pdf ไฟล์ใหม่ได้การสร้างไฟล์ pdf ใหม่ขึ้นมาทำได้โดยสร้างออบเจ็กต์
PyPDF2.PdfWriter เป็นออบเจ็กต์ตัวเขียนไฟล์ เอาไว้ใช้สำหรับรวบรวมหน้าเพื่อจะนำมาบันทึกเป็นไฟล์ pdf ใหม่ขึ้น โดยเมื่อสร้างขึ้นมาใหม่มันจะว่างเปล่า ให้ใช้เมธอด .add_page() เพื่อทำการใส่หน้ากระดาษที่ต้องการลงไป จากนั้นก็ใช้เมธอด .write() เพื่อบันทึกลงไฟล์ใหม่เช่นถ้าต้องการดึงหน้าแรกจากไฟล์ pdf ที่มีอยู่เดิมก็ทำได้โดยใช้
PyPDF2.PdfReader เปิดไฟล์นั้นขึ้นมา แล้วสร้าง PyPDF2.PdfWriter แล้วนำหน้าแรกนั้นใส่ลงไป แบบนี้pdf_0 = PyPDF2.PdfReader('รายการอาหาร.pdf') # เปิดไฟล์เอกสารเดิม
na = pdf_0.pages[0] # ดึงเอาหน้าแรกมา
pdf_x = PyPDF2.PdfWriter() # สร้างออบเจ็กต์ตัวเขียนไฟล์ขึ้นมาใหม่
pdf_x.add_page(na) # เพิ่มหน้าที่ดึงมานั้นลงไป
pdf_x.write('หน้าแรกของรายการอาหาร.pdf') # บันทึกลงไฟล์เท่านี้เราก็จะได้ไฟล์ pdf ใหม่ที่มีหน้าเดียวหรือหน้าแรกของไฟล์เดิมนั้น
หากต้องการดึงหลายหน้าก็
.add_page() หน้าที่ต้องการไปเรื่อยๆ เช่นถ้าจะเอาแค่หน้าที่ 2 ถึง 4 ก็เขียนแบบนี้pdf_0 = PyPDF2.PdfReader('รายการอาหาร.pdf')
pdf_x = PyPDF2.PdfWriter()
na_raek = 2 # หน้าแรกที่จะเอา
na_sutthai = 4 # หน้าสุดท้ายที่จะเอา
# วนซ้ำเพื่อเพิ่มไปทีละหน้า
for i in range(na_raek-1,na_sutthai):
na = pdf_0.pages[i]
pdf_x.add_page(na)
pdf_x.write('หน้า 2-4 ของรายการอาหาร.pdf') # บันทึกลงไฟล์การแยกแต่ละหน้าเป็น pdf คนละไฟล์
ถ้าต้องการจะเอาไฟล์ pdf หลายหน้าที่มีอยู่เดิมมาแยกแต่ละหน้าให้กลายเป็น pdf หลายไฟล์ก็อาจเขียนได้ดังนี้
pdf_0 = PyPDF2.PdfReader('รายการอาหาร.pdf')
for i in range(len(pdf_0.pages)):
pdf_x = PyPDF2.PdfWriter()
pdf_x.add_page(pdf_0.pages[i])
pdf_x.write('รายการอาหารหน้า %d.pdf'%(i+1))การใส่หน้าเปล่าเข้าไป
PyPDF2 นั้นไม่มีความสามารถในการสร้างหน้ากระดาษใหม่ที่มีข้อมูลขึ้นมา แต่ถ้าแค่หน้าเปล่าๆละก็สามารถสร้างได้อยู่ ทำได้โดยใช้ฟังก์ชัน
.add_blank_page() ที่ตัวออบเจ็กต์ PyPDF2.PdfWriter ซึ่งก็คล้ายกับ .add_page() แค่สิ่งที่ใส่เข้าไปนั้นเป็นหน้าเปล่าๆเท่านั้นในการใส่หน้าเปล่าเข้าไปนั้นสิ่งที่จะต้องกำหนดก็มีเพียงขนาดความกว้างยาวของหน้าเปล่านั่นเท่านั้น
เช่น เราอาจลองสร้างไฟล์ pdf เปล่าที่มีหน้ากระดาษแผ่นเดียวขนาด 400×300 ได้ดังนี้
pdf_x = PyPDF2.PdfWriter()
pdf_x.add_blank_page(400,300)
pdf_x.write('หน้าว่างเปล่า.pdf')ตัวอย่างการใช้เพิ่มเติมอีกอย่าง เช่น หากต้องการเอาไฟล์ pdf มาแทรกหน้าว่างเปล่าคั่นทีละหน้าก็อาจเขียนได้แบบนี้
pdf_0 = PyPDF2.PdfReader('รายการอาหาร.pdf')
pdf_x = PyPDF2.PdfWriter()
for i in range(len(pdf_0.pages)):
na = pdf_0.pages[i]
pdf_x.add_page(na)
pdf_x.add_blank_page(na.mediabox.width,na.mediabox.height) # เพิ่มหน้าเปล่าที่มีขาดเท่ากับหน้าก่อนหน้า
pdf_x.write('รายการอาหารที่แทรกหน้าเปล่า.pdf')การหมุนหน้า pdf
ออบเจ็กต์หน้ากระดาษสามารถนำมาหมุนพลิกแนวตั้งแนวนอนได้โดยใช้เมธอด
.rotate() สำหรับหมุนตามเข็มนาฬิกาโดยเมธอดนี้ต้องใส่ค่ามุมลงไป โดยอาจใส่เป็น 90, 180, 270 ก็ได้ แต่ใส่ค่าอื่นไม่ได้เพราะการพลิกต้องพลิกเป็นมุนฉากเท่านั้น จะพลิกเอียงๆครึ่งๆกลางๆไม่ได้
ตัวอย่างการใช้ เช่น หากต้องการนำ pdf ที่มีอยู่มาหมุนตามเข็มไป 90 องศาหมดทุกหน้า
pdf_0 = PyPDF2.PdfReader('รายการอาหาร.pdf')
pdf_x = PyPDF2.PdfWriter()
for i in range(len(pdf_0.pages)):
na = pdf_0.pages[i]
na.rotate(90)
pdf_x.add_page(na)
pdf_x.write('รายการอาหารตะแคง.pdf')การย่อขยายหน้า pdf
หน้ากระดาษสามารถนำมาย่อขยายเปลี่ยนขนาดได้โดยใช้เมธอด
.scale() โดยใส่ค่าสัดส่วนขนาดในแนวตั้งและแนวนอนลงไป ค่าที่ใส่เป็นจำนวนเท่าของขนาดเดิม ถ้าใส่ 1 คือขนาดเดิมเช่นลองสร้าง pdf ใหม่โดยเอา pdf เดิมมาทำการขยายให้ความกว้างเป็น ๒ เท่าก็อาจเขียนได้ดังนี้
pdf_0 = PyPDF2.PdfReader('รายการอาหาร.pdf')
pdf_x = PyPDF2.PdfWriter()
for i in range(len(pdf_0.pages)):
na = pdf_0.pages[i]
na.scale(2,1)
pdf_x.add_page(na)
pdf_x.write('รายการอาหาาาาาาร.pdf')หรืออาจเปลี่ยนขนาดโดยกำหนดความกว้างและสูงใหม่โดยใช้เมธอด
.scale_to() เช่นถ้าต้องการได้หน้ากว้าง 500 สูง 400 ก็เขียนna.scale_to(500,400)การรวมไฟล์ pdf หลายไฟล์เข้าด้วยกัน
ใน PyPDF2 นั้นมีออบเจ็กต์
PyPDF2.PdfMerger ซึ่งเอาไว้ใช้รวมไฟล์ pdf หลายไฟล์เข้าด้วยกันตัวอย่างการใช้ เช่น ถ้าต้องการเอาหน้าทั้งหมดจาก pdf ๒ ไฟล์มาต่อรวมกันก็เขียนได้แบบนี้
pdf_x = PyPDF2.PdfMerger()
pdf_x.append('รายการอาหารเช้า.pdf')
pdf_x.append('รายการอาหารเย็น.pdf')
pdf_x.write('รายการอาหารเช้าเย็น.pdf')การรวมไฟล์ในลักษณะเดียวกันนี้ก็อาจทำได้โดยใช้
PyPDF2.PdfWriter เช่นกัน โดยอาจใช้เมธอด .append_pages_from_reader() เพื่อทำการใส่หน้าทั้งหมดจากตัวออบเจ็กต์ PyPDF2.PdfReader เขียนได้ดังนี้pdf_a = PyPDF2.PdfReader('รายการอาหารเช้า.pdf')
pdf_b = PyPDF2.PdfReader('รายการอาหารเย็น.pdf')
pdf_x = PyPDF2.PdfWriter()
pdf_x.append_pages_from_reader(pdf_a)
pdf_x.append_pages_from_reader(pdf_b)
pdf_x.write('รายการอาหารเช้าเย็น.pdf')จะเห็นว่าเขียนยาวขึ้นหน่อยเพราะต้องเปิดไฟล์ด้วย
PyPDF2.PdfReader ก่อน แต่ผลที่ได้ก็ไม่ต่างกันแต่ว่าเมธอด
.append() ของ PyPDF2.PdfMerger นั้นยังสามารถใส่คีย์เวิร์ด pages เข้าไปเพื่อกำหนดให้อาเฉพาะหน้าที่ต้องการได้ โดยใส่เป็นทูเพิลของช่วง (หน้าแรก,หน้าสุดท้าย) เช่นถ้าต้องการแค่ ๒ หน้าแรกของทั้ง ๒ ไฟล์ก็อาจเขียนแบบนี้pdf_x = PyPDF2.PdfMerger()
pdf_x.append('รายการอาหารเช้า.pdf',pages=(0,1))
pdf_x.append('รายการอาหารเย็น.pdf',pages=(0,1))
pdf_x.write('รายการอาหารรวมบางหน้า.pdf')กรณีนี้ถ้าใช้
PyPDF2.PdfWriter ก็อาจต้องใช้เมธอด .add_page() เพื่อยัดใส่ทีละหน้าแบบนี้pdf_a = PyPDF2.PdfReader('รายการอาหารเช้า.pdf')
pdf_b = PyPDF2.PdfReader('รายการอาหารเย็น.pdf')
pdf_x = PyPDF2.PdfWriter()
pdf_x.add_page(pdf_a.pages[0])
pdf_x.add_page(pdf_a.pages[1])
pdf_x.add_page(pdf_b.pages[0])
pdf_x.add_page(pdf_b.pages[1])
pdf_x.write('รายการอาหารรวมบางหน้า.pdf')การซ้อนหน้าเข้าด้วยกัน
PyPDF2 สามารถนำเอาหน้ากระดาษใน pdf ๒ หน้ามาซ้อนรวมเข้าด้วยกันได้ ทำได้โดยใช้เมธอด
.merge_page() ที่ตัวหน้าที่ต้องการให้เป็นพื้น โดยใส่หน้าที่ต้องการจะเอามาทับลงไป คือเขียนเป็น หน้าที่เป็นพื้น.merge_page(หน้าที่ต้องการทับ)เช่น มีไฟล์ pdf ที่มี ๒ หน้า มีอักษร "ฌ" กับ "ฬ" อยู่แบบนี้ แล้วต้องการเอามาซ้อนรวมกัน
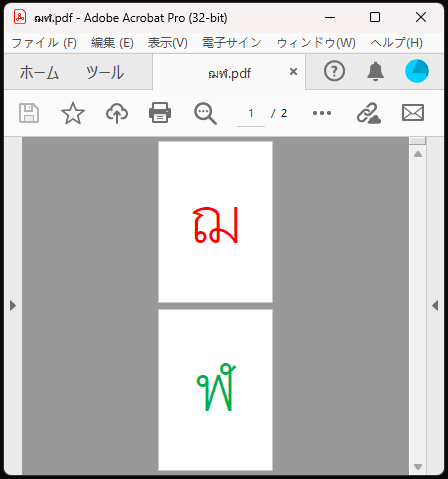
เขียนโค้ดได้ดังนี้
pdf_0 = PyPDF2.PdfReader('ฌฬ.pdf')
na_0 = pdf_0.pages[0]
na_0.merge_page(pdf_0.pages[1])
pdf_x = PyPDF2.PdfWriter()
pdf_x.add_page(na_0)
pdf_x.write('ฌxฬ.pdf')แล้วก็จะได้ไฟล์ pdf ที่มีส่วนประกอบของ ๒ หน้ามาซ้อนทับกัน โดยหน้าหลังวางทับหน้าแรก
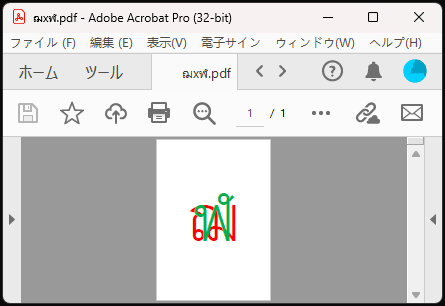
การใส่ลายน้ำ
เมธอด
.merge_page() นั้นสามารถนำมาใช้เพื่อทำลายน้ำได้ โดยภาพที่ต้องการทำเป็นลายน้ำนั้นต้องเตรียมไว้อยู่ในไฟล์ pdf (ถ้าเป็นไฟล์รูปหรือไฟล์ชนิดอื่นให้แปลงเป็น pdf ก่อน)ตัวอย่างเช่นเตรียมภาพสำหรับทำลายน้ำไว้ในไฟล์
ลายน้ำ.pdf แล้วต้องการใส่ลายน้ำนี้ลงไปในทุกหน้าของไฟล์ รายการอาหาร.pdf ก็อาจเขียนได้ดังนี้pdf_0 = PyPDF2.PdfReader('รายการอาหาร.pdf')
pdf_x = PyPDF2.PdfWriter()
for i in range(len(pdf_0.pages)):
na_i = pdf_0.pages[i]
pdf_lainam = PyPDF2.PdfReader('ลายน้ำ.pdf')
na_lainam = pdf_lainam.pages[0]
na_lainam.scale_to(float(na_i.mediabox.width),
float(na_i.mediabox.height))
na_lainam.merge_page(na_i)
pdf_x.add_page(na_lainam)
pdf_x.write('รายการอาหารใส่ลายน้ำ.pdf')ในที่นี้หน้าลายน้ำถูกใช้เป็นพื้น เพราะต้องการให้ซ้อนอยู่ด้านล่างข้อความของไฟล์หลัก แต่ถ้าเผลอทำสลับกันละก็ลายน้ำจะทับอยู่ด้านบนบังข้อความไป เพราะฉะนั้นต้องระวัง
ส่วน
.scale_to() นั้นใส่เพื่อทำให้ขนาดของหน้าลายน้ำมีขนาดเท่าหน้าของไฟล์หลัก เพียงแต่ว่าจริงๆแล้วควรจะเตรียมไฟล์ที่มีขนาดหน้าเท่านั้นไว้ตั้งแต่แรกดีกว่า แบบนั้นก็ไม่ต้องมาปรับขนาดอีก ก็ตัดบรรทัดนี้ทิ้งไปได้การใส่รหัสผ่านให้ไฟล์ pdf
ไฟล์ pdf นั้นสามารถตั้งรหัสเพื่อให้เฉพาะคนที่รู้รหัสเท่านั้นจึงจะอ่านเนื้อหาภายในได้
การตั้งรหัสนั้นก็สามารถทำได้โดยใช้เมธอด
.encrypt() ที่ตัวออบเจ็กต์ PyPDF2.PdfWriterหากต้องการทำให้ไฟล์ pdf ที่มีอยู่เดิมกลายเป็นไฟล์ที่ต้องใส่รหัสผ่าน อาจทำได้ดังนี้
pdf_0 = PyPDF2.PdfReader('รายการอาหาร.pdf')
pdf_x = PyPDF2.PdfWriter()
pdf_x.append_pages_from_reader(pdf_0)
pdf_x.encrypt('xxxx')
pdf_x.write('รายการอาหารลับ.pdf')เท่านี้เมื่อจะเปิดไฟล์นี้ก็จะต้องพิมพ์รหัส xxxx ลงไปจึงจะอ่านได้
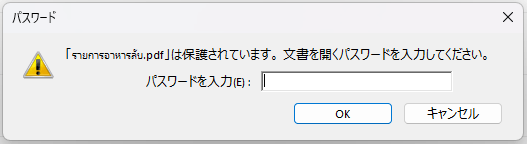
การเปิดอ่านไฟล์ pdf ที่ต้องป้อนรหัสผ่าน
ไฟล์ที่ต้องป้อนรหัสจึงจะอ่านได้นั้นถ้าเอามาอ่านโดย
PyPDF2.PdfReader โดยไม่ได้ทำอะไรก่อนก็จะเกิดข้อผิดพลาดขึ้นเช่นลองเอาไฟล์ที่เข้ารหัสจากตัวอย่างที่แล้วมาเปิด แล้วลองพยายามดูจำนวนหน้า
pdf_0 = PyPDF2.PdfReader('รายการอาหารที่ใส่รหัส.pdf')
len(pdf_0.pages) # ได้ FileNotDecryptedError: File has not been decryptedการที่จะทำให้สามารถอ่านข้อมูลจากไฟล์นี้ได้โดยไม่เกิดข้อผิดพลาดจะต้องใช้เมธอด
.decrypt() โดยป้อนรหัสลงไป แบบนี้จึงจะสามารถเปิดอ่านได้ตามปกติpdf_0 = PyPDF2.PdfReader('รายการอาหารลับ.pdf')
pdf_0.decrypt('xxxx') # ใส่รหัสเพื่อปลดล็อก
len(pdf_0.pages) # ไม่เกิดข้อผิดพลาดหากต้องการเอาไฟล์ที่เข้ารหัสไว้มาปลดรหัสแก้เป็นไฟล์ที่ไม่ต้องใส่รหัสก็อ่านได้ละก็อาจเขียนดังนี้
pdf_0 = PyPDF2.PdfReader('รายการอาหารลับ.pdf')
pdf_0.decrypt('xxxx') # ใส่รหัสเพื่อปลดล็อก
pdf_x = PyPDF2.PdfWriter()
pdf_x.append_pages_from_reader(pdf_0)
pdf_x.write('รายการอาหารไม่ลับ.pdf')ไฟล์ใหม่ที่ได้นั้นจะสามารถเปิดอ่านได้โดยไม่ต้องป้อนรหัสผ่านแล้ว
การจัดการ metadata
metadata คือข้อมูลที่ติดมากับไฟล์ pdf ซ่อนอยู่ภายในไฟล์ ไม่ได้แสดงให้ผู้ใช้ที่เปิดอ่านไฟล์ทั่วไปได้เห็น ใช้บอกข้อมูลคร่าวๆเช่นว่าไฟล์นี้ถูกสร้างขึ้นมาด้วยโปรแกรมอะไร เมื่อไหร่ ใครเป็นคนสร้างขึ้นมาตั้งแต่แรก เป็นต้น
เมื่อใช้
PyPDF2.PdfReader เพื่ออ่านไฟล์เข้ามาเราสามารถดูข้อมูล metadata ได้ที่แอตทริบิวต์ .metadata โดยจะได้มาเป็นออบเจ็กต์ดิกชันนารีที่บรรจุข้อมูลต่างๆไว้ข้อมูลใน metadata หลักๆที่สำคัญมีประมาณนี้
| /Author | ผู้ที่สร้างไฟล์ขึ้นมา |
| /Creator | โปรแกรมที่ใช้สร้างไฟล์ |
| /CreationDate | เวลาที่ไฟล์ถูกสร้างขึ้น |
| /ModDate | เวลาที่ไฟล์ถูกแก้ไขล่าสุด |
| /Producer | โปรแกรมที่ใช้ดัดแปลงไฟล์มา |
| /Title | ไตเติล |
นอกจากนี้จริงๆแล้วจะใส่อะไรก็ได้ ตามแต่ที่ผู้สร้างไฟล์อยากจะใส่
ตัวอย่างเช่นเปเปอร์ที่โหลดจากเว็บ Identifying Exoplanets with Deep Learning. V. Improved Light-curve Classification for TESS Full-frame Image Observations
เมื่อลองโหลดเข้ามาแล้วเปิดดู metadata
pdf_0 = PyPDF2.PdfReader('Tey_2023_AJ_165_95.pdf')
print(pdf_0.metadata)ก็จะออกมาแบบนี้
{'/Creator': 'IOPP',
'/CrossMarkDomains#5B1#5D': 'iop.org',
'/ModDate': "D:20230206150834+05'30'",
'/robots': 'noindex',
'/doi': '10.3847/1538-3881/acad85',
'/Keywords': 'Neural networks; Transit photometry; Exoplanet detection methods; Exoplanet catalogs',
'/Title': 'Identifying Exoplanets with Deep Learning. V. Improved Light-curve Classification for TESS Full-frame Image Observations',
'/CreationDate': "D:20230206150814+05'30'",
'/crossmarkMajorVersionDate': '2023-02-09',
'/Subject': 'The Astronomical Journal, 165(2023) 95. doi:10.3847/1538-3881/acad85',
'/Author': 'Evan Tey'}จะมีข้อมูลตรงนี้ถูกใส่ไว้เยอะแค่ไหนก็อาจขึ้นอยู่กับสำนักพิมพ์และโปรแกรมที่ใช้ บางทีข้อมูลอาจจะไม่ถูกใส่อยู่เลยก็ได้
ปกติเมื่อใช้
PyPDF2.PdfWriter สร้างไฟล์ pdf ขึ้นมาใหม่จะไม่มีข้อมูล metadata อยู่ภายในนั้นเลยแต่ว่าในตัวอย่างหลายตัวอย่างที่ยกมาข้างต้นเช่นการเอาไฟล์ pdf มาหมุนหรือย่อขยายขนาดนั้นหรือใส่รหัสผ่านนั้น ตัวไฟล์ที่บันทึกนั้นไม่ใช่ตัวไฟล์เดิมจริงๆ ไม่ได้บรรจุข้อมูล metadata เหมือนอย่างในไฟล์เดิม แบบนั้นถ้าไฟล์เดิมมี metadata อยู่ก็ย่อมจะหายไปหมด
หากต้องการจะรักษา metadata จากไฟล์เดิมไว้ก็ทำได้โดยใช้เมธอด
.add_metadata() โดยใส่ metadata จากไฟล์เก่า แค่นี้ก็ได้ไฟล์ใหม่ที่มี metadata เหมือนกับไฟล์เดิมแล้วเช่นโค้ดที่ทำการใส่รหัสให้ไฟล์ pdf นั้นอาจเขียนใหม่ได้เป็น
pdf_0 = PyPDF2.PdfReader('รายการอาหาร.pdf')
pdf_x = PyPDF2.PdfWriter()
pdf_x.append_pages_from_reader(pdf_0)
pdf_x.add_metadata(pdf_0.metadata) # แค่เพิ่มบรรทัดนี้เข้าไป
pdf_x.encrypt('xxxx')
pdf_x.write('รายการอาหารลับ.pdf')เท่านี้ก็จะได้ไฟล์ใหม่ที่มี metadata เหมือนเดิม แค่เพิ่มการใส่รหัสเข้าไป
นอกจากนี้
.add_metadata() นั้นยังใช้เพื่อแก้ข้อมูล metadata หรือเพิ่มใหม่ได้ด้วย โดยใส่เป็นดิกชันนารีของค่าที่ต้องการแก้หรือเพิ่มเข้าไปได้เลย ถ้าค่านั้นมีอยู่แล้วก็จะเป็นการเขียนทับ ถ้ายังไม่มีก็จะถูกเพิ่มเข้าไปใหม่เช่นถ้าต้องการเอาไฟล์มาแก้ข้อมูล metadata ในส่วนของ /Author ซึ่งหมายถึงผู้ที่เป็นเจ้าของไฟล์ (คนที่สร้างไฟล์เป็นคนแรก) ก็ทำได้โดย
pdf_0 = PyPDF2.PdfReader('รายการอาหาร.pdf')
pdf_x = PyPDF2.PdfWriter()
pdf_x.append_pages_from_reader(pdf_0)
pdf_x.add_metadata(pdf_0.metadata)
pdf_x.add_metadata({'/Author':'ข้าพเจ้าเอง'}) # ส่วนที่ต้องการแก้หรือเพิ่ม
pdf_x.write('รายการอาหารของฉันเอง.pdf')หรือหากต้องการจะลบ metadata บางส่วนที่มีอยู่ก็ทำได้ เช่นถ้าต้องการลบ /Author ออกก็อาจเขียนแบบนี้
pdf_0 = PyPDF2.PdfReader('รายการอาหารของฉันเอง.pdf')
info = pdf_0.metadata # ดึงดิกของตัวข้อมูล metadata ออกมา
del info['/Author'] # ลบตัวที่ไม่ต้องการทิ้ง
pdf_x = PyPDF2.PdfWriter()
pdf_x.append_pages_from_reader(pdf_0)
pdf_x.add_metadata(info) # ใส่ metadata ที่ลบบางส่วนทิ้งแล้วเข้าไป
pdf_x.write('รายการอาหารที่ไม่มีเจ้าของ.pdf')สรุปแอตทริบิวต์และเมธอดของ PdfReader
สุดท้ายนี้ขอสรุปแอตทริบิวต์และเมธอดที่สำคัญภายในออบเจ็กต์
PyPDF2.PdfReader ที่จริงยังมีอีกมากมายที่ไม่ได้พูดถึง แต่ในที่นี้จะขอสรุปเฉพาะที่ได้เขียนถึงมาทั้งหมด| .metadata | ข้อมูล metadata |
| .pages | ลิสต์ของออบเจ็กต์หน้ากระดาษทั้งหมด |
| .is_encrypted | ดูว่าไฟล์ถูกขึ้นรหัสอยู่หรือเปล่า |
| .decrypt(x) | ป้อนรหัสผ่านเพื่อปลดล็อกไฟล์ที่ถูกตั้งรหัสผ่านไว้ |
x ในวงเล็บหลังชื่อเมธอดในที่นี้หมายถึงสิ่งที่ต้องใส่ลงไปขณะใช้เมธอดนั้นๆ รายละเอียดดูที่เนื้อหาด้านบน
สรุปเมธอดของ PdfWriter
| .write(x) | บันทึกไฟล์ |
| .add_page(x) | ใส่หน้าใหม่เข้าไป |
| .add_blank_page() | ใส่หน้าเปล่าเข้าไป |
| .append_pages_from_reader(x) | ใส่หน้าทั้งหมดจากออบเจ็กต์ PdfReader |
| .add_metadata(x) | ใส่ metadata เข้าไป |
| .encrypt(x) | ตั้งรหัสผ่านที่ต้องป้อนเวลาจะเปิดไฟล์ |
สรุปแอตทริบิวต์และเมธอดของ PageObject
| .extract_text() | เอาข้อความตัวหนังสือทั้งหมดในหน้านั้น |
| .mediabox.width | ความกว้างของหน้า |
| .mediabox.height | ความสูงของหน้า |
| .rotate(x) | หมุนหน้าตามเข็มนาฬิกาเป็นมุม x |
| .scale(x,y) | ปรับขนาดของหน้าเป็นกว้าง x เท่าสูง y เท่าจากเดิม |
| .scale_to(x,y) | ปรับขนาดของหน้าเป็นกว้าง x สูง y |
| .merge_page(x) | ซ้อนหน้า x ลงไป |
อ้างอิง
PyPDF2的使用
Python 自动化办公 —— PyPDF2 库的基本使用
PyPDF2を使ってPythonでPDFを操作する
PythonでPDFを分割する(PyPDF2)
PythonでPDFのページサイズを取得(PyPDF2)
【Python×PDF】PyPDF2によるPDFファイルの結合・分割と画像抽出する方法
PyPDF2を調べた
PyPDF2を使用し、PythonでPDFファイルの暗号化及び復号化
Python, PyPDF2でPDFの作成者やタイトルなどを取得・削除・変更
Python 自动化办公 —— PyPDF2 库的基本使用
PyPDF2を使ってPythonでPDFを操作する
PythonでPDFを分割する(PyPDF2)
PythonでPDFのページサイズを取得(PyPDF2)
【Python×PDF】PyPDF2によるPDFファイルの結合・分割と画像抽出する方法
PyPDF2を調べた
PyPDF2を使用し、PythonでPDFファイルの暗号化及び復号化
Python, PyPDF2でPDFの作成者やタイトルなどを取得・削除・変更
