การใช้ scipy.stats เพื่อสุ่มหรือคำนวณค่าต่างๆของการแจกแจงความน่าจะเป็นแบบต่างๆ
เขียนเมื่อ 2020/09/13 23:46
แก้ไขล่าสุด 2023/08/26 13:18
การแจกแจงความน่าจะเป็นแบบต่างๆ
มอดูลย่อย scipy.stats ใน scipy เป็นมอดูลสำหรับจำลองการแจกแจงความน่าจะเป็นในรูปแบบต่างๆไว้มากมาย
ความสามารถของมอดูลนี้นั้นสามารถทำได้ทั้งสร้างค่าสุ่มตามการแจกแจงความน่าจะเป็นในแบบที่ต้องการ หรือสามารถคำนวณค่าของฟังก์ชันการแจกแจงความน่าจะเป็น หรือความหนาแน่นความน่าจะเป็นสะสมตามที่ต้องการได้
รูปแบบการแจกแจงต่างๆที่ใช้ได้ภายในมอดูลนี้มีเยอะแยะครอบคลุมมากมายจนไม่อาจจะเขียนถึงได้หมด
โดยทั่วไปแบ่งออกเป็น ๓ กลุ่มหลักๆ คือ
- การแจกแจงแบบไม่ต่อเนื่อง (discrete)
- การแจกแจงแบบต่อเนื่อง (continuous)
- การแจกแจงแบบหลายตัวแปร (multivariate)
ส่วนกลุ่มที่เป็นการแจกแจงแบบหลายตัวแปรนั้นจะค่อนข้างซับซ้อนกว่า ซึ่งต่างกันออกไป ในที่นี้จะไม่เขียนถึงวิธีใช้การแจกแจงกลุ่มนี้ เมธอดต่างๆที่จะแนะนำต่อไปนี้จะเป็นที่ใช้ใน ๒ กลุ่มแรกเป็นหลัก
ในที่นี้จะยกตัวอย่างการแจกแจงต่างๆเฉพาะที่ได้กล่าวถึงไปในบทความความน่าจะเป็นเบื้องต้นสำหรับเขียนโปรแกรม ซึ่งมีทั้งหมด ๑๗ แบบ
ก่อนอื่นจะขอเริ่มจากแนะนำชื่อฟังก์ชันใน scipy.stats ที่ใช้สำหรับสร้างการแจกแจงชนิดต่างๆก่อน โดยรายละเอียดของการแจกแจงแต่ละแบบนั้นจะไม่มีการอธิบายในหน้านี้ แต่ดูได้จากลิงก์ที่ตัวเลขทางขวา ซึ่งแสดงบทเนื้อหาที่เกี่ยวข้อง
ชื่อพารามิเตอร์ต่างๆในที่นี้ยึดตามที่เขียนในบทความนั้น แต่ตัวแปรที่แจกแจงจะเขียนเป็น x ทั้งหมด
การแจกแจงแบบไม่ต่อเนื่อง
| ชื่อการแจกแจง | ฟังก์ชันมวล (pmf) | x | scipy.stats | พารามิเตอร์ | รายละเอียด |
|---|---|---|---|---|---|
| การแจกแจงทวินาม | {0,1,2,...,n} | .binom(n,p) | n ∈ จำนวนเต็มบวก, p ∈ [0,1] |
[5], [14] | |
| การแจกแจงแบร์นุลลี | {0,1} | .bernoulli(p) | p ∈ [0,1] | ||
| การแจกแจงทวินามเชิงลบ | {0,1,2,...} | .nbinom(r,p) | r ∈ จำนวนเต็มบวก, p ∈ [0,1] |
[6] | |
| การแจกแจงแบบเรขาคณิต | {1,2,...} | .geom(p) | p ∈ [0,1] | ||
| การแจกแจงปัวซง | {0,1,2,...} | .poisson(λ) | λ ∈ (0,∞) | [7], [10] | |
| การแจกแจงเอกรูปไม่ต่อเนื่อง | {a,a+1,...,b-1} | .randint(a,b) | a ∈ จำนวนเต็ม, b ∈ จำนวนเต็ม |
[4] |
โดย C คือจำนวนวิธีการในการจัดหมู่
การแจกแจงแบบต่อเนื่อง
| ชื่อการแจกแจง | ฟังก์ชันความหนาแน่น (pdf) | x | scipy.stats | พารามิเตอร์ | รายละเอียด |
|---|---|---|---|---|---|
| การแจกแจงเอกรูปต่อเนื่อง | [a,b] | .uniform(a,b) | a ∈ (−∞,∞), b ∈ (−∞,∞) |
[8] | |
| การแจกแจงแบบปกติ | (−∞,∞) | .norm(μ,σ) | μ ∈ (−∞,∞), σ ∈ (0,∞) |
[12], [14] | |
| การแจกแจงแบบเลขชี้กำลัง | [μ,∞) | .expon(μ,λ) | μ ∈ (-∞,∞) λ ∈ (0,∞) |
[10] | |
| การแจกแจงเบตา | (0,1) | .beta(α,β) | α ∈ (0,∞), β ∈ (0,∞) |
[11], [15] | |
| การแจกแจงแกมมา |
หรือ |
(0,∞) | .gamma(ν,1/β) หรือ .gamma(ν,θ) |
ν ∈ (0,∞), β ∈ (0,∞) |
[16], [19] |
| การแจกแจงไคกำลังสอง | (0,∞) | .chi2(k) | k ∈ จำนวนเต็มบวก | [18] | |
| การแจกแจงสติวเดนต์ที | (−∞,∞) | .t(ν) | ω ∈ (0,∞) μ ∈ (-∞,∞) |
[20] |
โดย
- B คือฟังก์ชันเบตา
- Γ คือฟังก์ชันแกมมา
การแจกแจงแบบหลายตัวแปร
| การแจกแจง | ฟังก์ชันความหนาแน่นหรือฟังก์ชันมวล และพารามิเตอร์ | รายละเอียด |
|---|---|---|
| การแจกแจงแบบปกติหลายตัวแปร .multivariate_normal(μ,Σ) |
พารามิเตอร์ , , , , |
[13] |
| การแจกแจงวิชาร์ต .wishart(ν,V) |
พารามิเตอร์ , , |
[17] |
| การแจกแจงอเนกนาม .multinomial(n,p) |
พารามิเตอร์ n ∈ จำนวนเต็ม, , |
[21] |
| การแจกแจงดีริคเล .dirichlet(α) |
พารามิเตอร์ , |
[22] |
การเริ่มต้นใช้งาน
การใช้งานมอดูลย่อย scipy.stats นั้นจำเป็นต้องสั่ง import scipy.stats โดยตรง จะแค่ import scipy เฉยๆไม่ได้
import scipy
print(scipy.stats) # ได้ AttributeError: module 'scipy' has no attribute 'stats'สำหรับตัวอย่างต่อๆไปนี้จะ import แบบนี้ทั้งหมด (รวม numpy และ matplotlib ที่ต้องใช้ด้วย)
import scipy.stats
import numpy as np
import matplotlib.pyplot as pltสร้างค่าสุ่มตามการแจกแจงความน่าจะเป็น
งานหลักของมอดูล scipy.stats ที่มักจะถูกใช้มากที่สุดก็คือการใช้สุ่มค่าเพื่อให้ได้การแจกแจงตามที่ต้องการ
การใช้งานโดยทั่วไปจะเริ่มจากสร้างออบเจ็กต์ตัวแจกแจงขึ้นมา โดยใส่พารามิเตอร์ของการแจกแจงนั้นลงไปตอนนั้น จากนั้นก็เรียกใช้เมธอด .rvs(จำนวน) ก็จะเป็นการสุ่มค่าตามการแจกแจงนั้น
ยกตัวอย่างเช่นลองสุ่มการแจกแจงทวินามสักหมื่นตัว
n = 50
p = 0.05
binom = scipy.stats.binom(n,p)
x = binom.rvs(10000)
plt.hist(x,np.arange(-0.5,x.max()+1),fc='r',ec='k')
plt.show()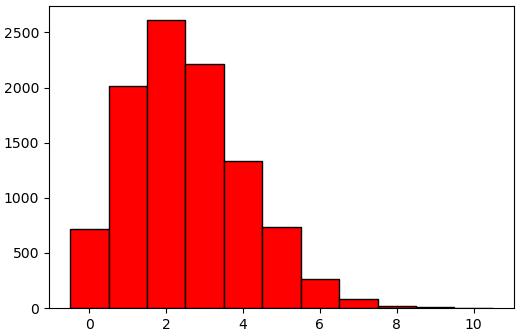
นอกจากนี้ยังมีวิธีลัดในการใช้โดยไม่ต้องสร้างออบเจ็กต์ขึ้นมาก่อน แต่ถ้าต้องการจะทำการสุ่มแค่ครั้งเดียวอยู่แล้วก็อาจจะใช้เมธอด .rvs โดยตรงได้เลย โดยใส่พารามิเตอร์ลงไปเช่นเดียวกับตอนสร้างออบเจ็กต์เฉยๆ ส่วนจำนวนที่ต้องการใส่ให้ใส่เป็นคีย์เวิร์ด size
เช่นสร้างค่า x โดยเขียนแบบนี้ก็ให้ผลเหมือนเดิม
x = scipy.stats.binom.rvs(n,p,size=10000)การแจกแจงแบบอื่นๆก็ใช้ในลักษณะเดียวกัน แค่เปลี่ยนพารามิเตอร์ เช่นลองดูตัวอย่างการแจกแจงเบตา อาจเขียนได้แบบนี้
α = 3
β = 7
beta = scipy.stats.beta(α,β)
x = beta.rvs(10000)
# หรืออาจเขียนเป็น x = scipy.stats.beta.rvs(α,β,size=10000)
plt.hist(x,50,fc='r',ec='k')
plt.show()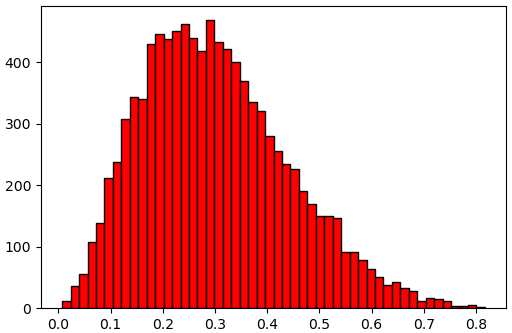
สำหรับการใช้งานตรงส่วนนี้ ทั้งการแจกแจงแบบต่อเนื่องหรือไม่ต่อเนื่องก็มีวิธีการใช้งานเหมือนกัน
การแจกแจงบางส่วนสามารถใช้ np.random ของ numpy แทนได้ เช่นหากต้องการสุ่มการแจกแจงแบบปกติ scipy.stats.norm.rvs() สามารถใช้ np.random.normal()
ส่วนการแจกแจงแบบเอกนามต่อเนื่องก็ใช้ np.random.uniform() ถ้าเป็นเอกนามแบบไม่ต่อเนื่องก็ใช้ np.random.randint()
เกี่ยวกับฟังก์ชันสุ่มต่างๆใน numpy ได้เขียนถึงไว้ใน numpy & matplotlib เบื้องต้น บทที่ ๑๕
คำนวณฟังก์ชันความหนาแน่นของความน่าจะเป็น
สำหรับการแจกแจงแบบต่อเนื่องจะมีเมธอด .pdf() ไว้ใช้คำนวณค่าฟังก์ชันความหนาแน่นของความน่าจะเป็น (probability density function)
ตัวอย่างการใช้งานการแจกแจงทวินาม
α = 2
β = 8
beta = scipy.stats.beta(α,β)
x = np.linspace(0,1,101)
y = beta.pdf(x)
plt.plot(x,y,'r')
plt.show()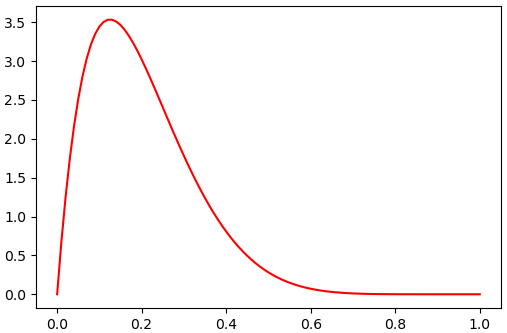
หรืออาจเรียกใช้งานเมธอด .pdf โดยตรงโดยไม่ต้องสร้างขึ้นมาก่อนได้เช่นกัน โดยใส่ค่า x เป็นอาร์กิวเมนต์ตัวแรก แล้วค่อยตามด้วยพารามิเตอร์ตามลำดับ
y = scipy.stats.beta.pdf(x,α,β)ฟังก์ชันมวลของความน่าจะเป็น
เช่นเดียวกับที่การแจกแจงแบบต่อเนื่องมีเมธอด .pdf() สำหรับการแจกแจงแบบไม่ต่อเนื่องจะมีเมธอด .pmf() ไว้ใช้คำนวณฟังก์ชันมวลของความน่าจะเป็น (probability mass function)
ตัวอย่าง ใช้กับการแจกแจงเบตา
n = 40
p = 0.1
binom = scipy.stats.binom(n,p)
x = np.arange(14)
y = binom.pmf(x)
plt.plot(x,y,'ro-')
plt.show()สามารถเรียกเมธอด .pmf() โดยตรงได้เช่นกัน
y = scipy.stats.binom.pmf(x,n,p)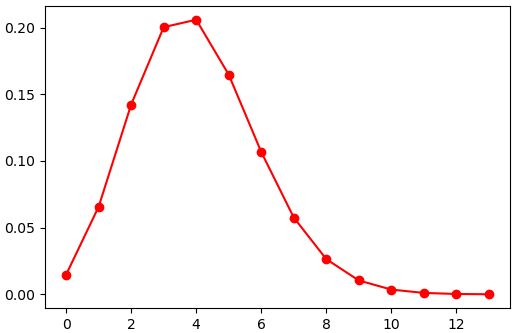
ฟังก์ชันแจกแจงความน่าจะเป็นสะสมหรือฟังก์ชันอยู่รอด
การคำนวณฟังก์ชันแจกแจงสะสม (cumulative distribution function) ทำได้โดยใช้เมธอด .cdf() โดยเมธอดนี้ใช้ได้เหมือนกันทั้งการแจกแจงแบบต่อเนื่องและไม่ต่อเนื่อง
เกี่ยวกับฟังก์ชันแจกแจงสะสมอ่านรายละเอียดได้ใน ความน่าจะเป็นเบื้องต้น บทที่ ๘
ตัวอย่าง ลองใช้กับการแจกแจงทวินาม
n = 20
p = 0.4
binom = scipy.stats.binom(n,p)
x = np.arange(18)
y = binom.cdf(x)
# หรือ y = scipy.stats.binom.cdf(x,n,p)
plt.plot(x,y,'ro-')
plt.show()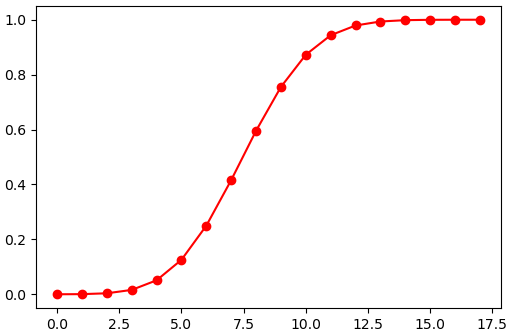
การแจกแจงเบตา
α = 5
β = 4
beta = scipy.stats.beta(α,β)
x = np.linspace(0,1,101)
y = beta.cdf(x)
# หรือ y = scipy.stats.beta.cdf(x,α,β)
plt.plot(x,y,'r')
plt.show()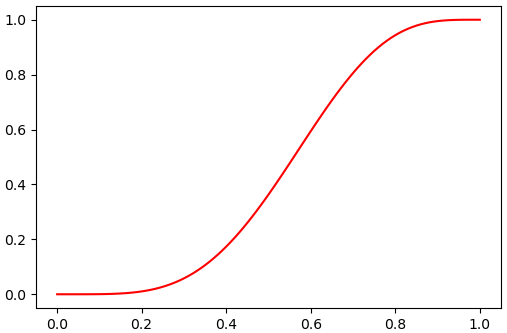
นอกจากนี้มีเมธอด .sf() ซึ่งจะคำนวณค่าฟังก์ชันอยู่รอด (survival function) ซึ่งก็เท่ากับ 1-cdf
y = beta.sf(x)
plt.plot(x,y,'r')
plt.show()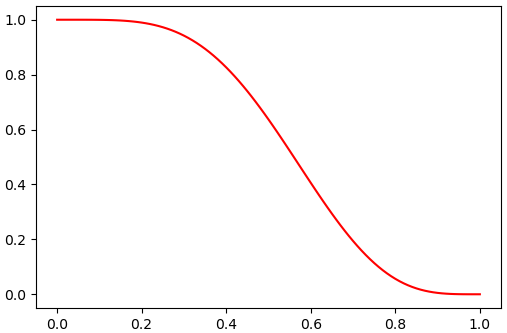
กราฟที่ได้จะกลับกับ .cdf() จากบนลงล่าง
ส่วนกลับของการแจกแจงความน่าจะเป็นสะสม
เมธอด .ppf() ไว้คำนวณค่าส่วนกลับของ cdf ซึ่งเรียกว่าเป็นฟังก์ชันจุดร้อยละ (percent point function) หรือเรียกว่า ฟังก์ชันควอนไทล์ (quantile function)
ค่านี้เป็นค่าที่บอกว่าถ้ามีค่าความน่าจะเป็นรวมถึงเท่านี้แสดงว่าต้องรวมความน่าจะเป็นสะสมมาจนถึงค่าเท่าใด
ตัวอย่าง เมื่อใช้กับการแจกแจงแบบไม่ต่อเนื่องอย่างการแจกแจงทวินาม
n = 10
p = 0.75
binom = scipy.stats.binom(n,p)
q = np.linspace(0,1,1001)
ppf = binom.ppf(q)
plt.plot(q,ppf,'r')
plt.show()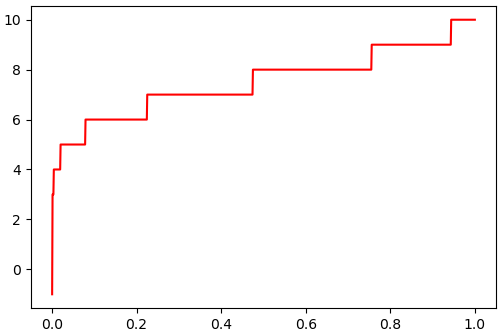
ต่อมาลองใช้กับการแจกแจงแบบต่อเนื่องอย่างการแจกแจงเบตา
α = 10
β = 7
beta = scipy.stats.beta(α,β)
q = np.linspace(0,1,1001)
ppf = beta.ppf(q)
plt.plot(q,ppf,'r')
plt.show()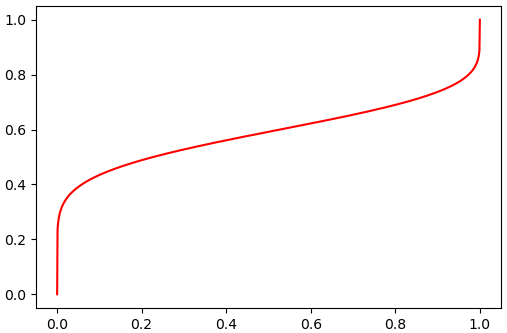
และมีเมธอด .isf ซึ่งเอาไว้คำนวณค่าฟังก์ชันอยู่รอดผกผัน (inverse survival function) ซึ่งก็คือส่วนกลับของ sf กราฟที่ได้จะกลับจาก .ppf() เป็นบนลงล่าง
isf = beta.isf(q)
plt.plot(q,isf,'r')
plt.show()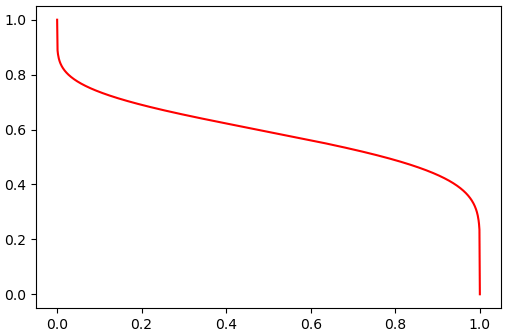
คำนวณค่าคาดหมาย
เมธอด .expect() ใช้คำนวณค่าคาดหมาย (expectation value) จากการแจกแจงนั้นของฟังก์ชันที่ต้องการได้
เกี่ยวกับการคำนวณค่าคาดหมายอ่านรายละเอียดได้ใน ความน่าจะเป็นเบื้องต้น บทที่ ๔
เช่น
n = 10
p = 0.3
binom = scipy.stats.binom(n,p)
def f(x):
return x**2
print(binom.expect(f)) # ได้ 11.100000000000007
def g(x):
return 1/(x+1)
print(binom.expect(g)) # ได้ 0.297038403809091หากไม่ได้ใส่ฟังก์ชันลงไปจะเป็นการหาค่าคาดหมายของ f(x)=x
print(binom.expect()) # ได้ 3.0000000000000013คำนวณค่าเฉลี่ย, มัธยฐาน, ความแปรปรวน, ส่วนเบี่ยงเบนมาตรฐาน
ค่าต่างๆที่สำคัญทางสถิติ เช่น ค่าเฉลี่ย, มัธยฐาน, ความแปรปรวน, ส่วนเบี่ยงเบนมาตรฐาน ของการแจกแจงแบบต่างๆสามารถคำนวณได้โดยใช้เมธอด .mean() .median() .var() .std()
n = 100
p = 0.2
binom = scipy.stats.binom(n,p)
print(binom.median()) # ได้ 20.0
print(binom.mean()) # ได้ 20.0
print(binom.std()) # ได้ 4.0
print(binom.var()) # ได้ 16.0
α = 3
β = 2
beta = scipy.stats.beta(α,β)
print(scipy.stats.beta.median(α,β)) # ได้ 0.6142724318676104
print(scipy.stats.beta.mean(α,β)) # ได้ 0.6
print(scipy.stats.beta.std(α,β)) # ได้ 0.2
print(scipy.stats.beta.var(α,β)) # 0.04สรุปเมธอดต่างๆ
| ชื่อฟังก์ชัน | ความหมาย |
|---|---|
| .rvs(size=1, random_state=None) | ทำการสุ่มค่าตามการแจกแจงนั้น |
| .pmf(x) หรือ .pdf(x) |
คำนวณฟังก์ชันมวลหรือฟังก์ชันความหนาแน่น |
| .logpmf(x) หรือ .logpdf(x) |
คำนวณลอการิธึมของฟังก์ชันมวลหรือฟังก์ชันความหนาแน่น |
| .cdf(x) | คำนวณฟังก์ชันการแจกแจงสะสม |
| .logcdf(x) | คำนวณลอการิธึมของฟังก์ชันการแจกแจงสะสม |
| .sf(x) | คำนวณ 1 - cdf |
| .logsf(x) | คำนวณลอการิธึมของ 1 - cdf |
| .ppf(q) | คำนวณฟังก์ชันผกผันของ cdf |
| .isf(q) | คำนวณฟังก์ชันผกผันของ sf |
| .entropy() | หาเอนโทรปี |
| .expect(func) | หาค่าคาดหมายของฟังก์ชัน func |
| .mean() | ค่าเฉลี่ย |
| .median() | มัธยฐาน |
| .std() | ส่วนเบี่ยงเบนมาตรฐาน |
| .var() | ความแปรปรวน |
เมธอดที่ขึ้นต้นด้วย .log มีไว้คำนวณค่าลอการิธึมของค่านั้นๆ เช่น .logpdf() .logpmf() ในที่นี้ไม่ได้แสดงตัวอย่างการใช้ให้เห็น แต่วิธีการใช้ก็เหมือนกันกับ .pdf() .pmf() แค่คำนวณออกมาเป็นค่าลอการิธึม
กรณีที่ต้องการคำนวณค่าลอการึธึมให้ใช้เมธอดเหล่านี้โดยตรงจะดีกว่าไปคำนวณลอการิธึมเองภายหลัง เพราะเร็วกว่าและป้องกันตัวเลขสูงหรือต่ำเกิน (overflow & underflow) ได้
ความแตกต่างระหว่างการแจกแจงแบบต่อเนื่องกับไม่ต่อเนื่องที่เห็นชัดที่สุดคือเมธอด .pmf() กับ .pdf() โดยการแจกแจงแบบไม่ต่อเนื่องใช้ .pmf() ส่วนการแจกแจงแบบต่อเนื่องใช้ .pdf()
-----------------------------------------
囧囧囧囧囧囧囧囧囧囧囧囧囧囧囧囧囧囧囧囧囧囧囧囧囧
หมวดหมู่
-- คณิตศาสตร์ >> ความน่าจะเป็น-- คอมพิวเตอร์ >> เขียนโปรแกรม >> python >> scipy
-- คอมพิวเตอร์ >> การสุ่ม